- 【大内存服务GC实践】- 一文看懂”ParNew+CMS”垃圾回收器
- 【大内存服务GC实践】- “ParNew+CMS”实践案例 : HiveMetastore FullGC诊断优化
本篇文章重点结合生产线上NameNode RPC毛刺这个现象,分析两起严重的YGC问题。NameNode是HDFS服务最核心的组件,大数据任务读写文件都需要请求NameNode,该服务一旦出现RPC处理毛刺,就可能会引起上层大数据平台离线、实时任务的延迟甚至异常。公司内部NameNode采用”ParNew+CMS”组合垃圾回收器。
随着HDFS集群规模的增大,NameNode性能压力越来越大,因此我们结合社区新版本的优化进行了内部分支的优化并发布上线。上线之后观察了一周,发现上线后RPC排队毛刺明显变大变多。如下图所示:

为什么RPC排队毛刺会出现?
按照经验来看,NameNode的RPC请求处理/排队毛刺很大有可能有这么几个原因:
- 大规模文件删除导致NameNode卡住。
- 大目录getContentSummary接口调用。
- 大GC影响。
按照这几个思路分别查看监控,发现事发时间点GC表现有些异常,如下所示:
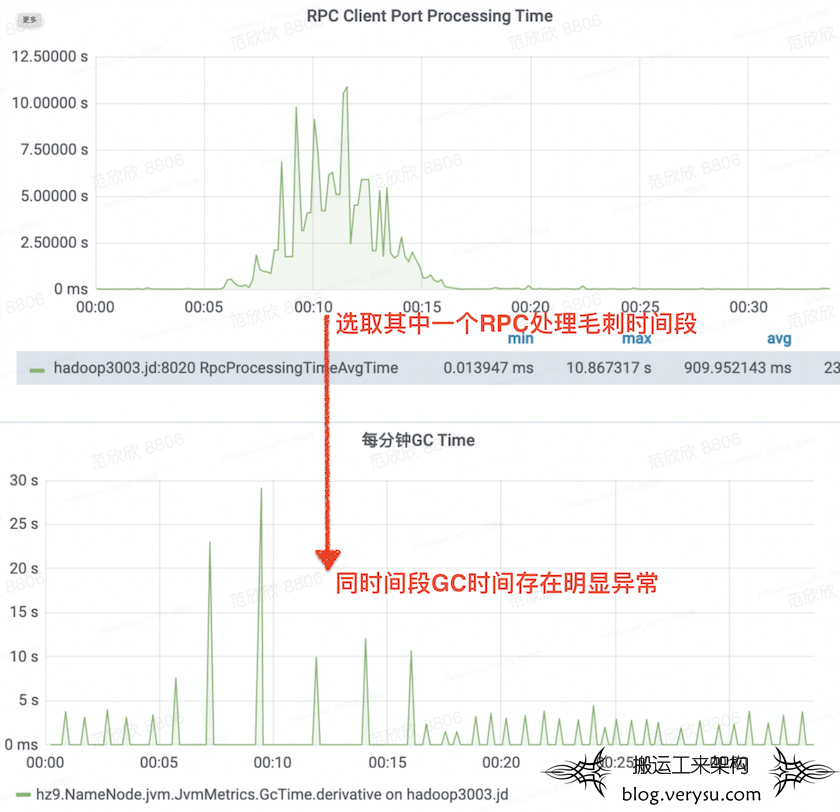
结合时间点查看对应的GC日志,发现部分YGC耗时异常。正常情况下YGC耗时基本稳定在0.2~0.5秒,但是事发时间段耗时长达3秒、7秒。如下图所示:
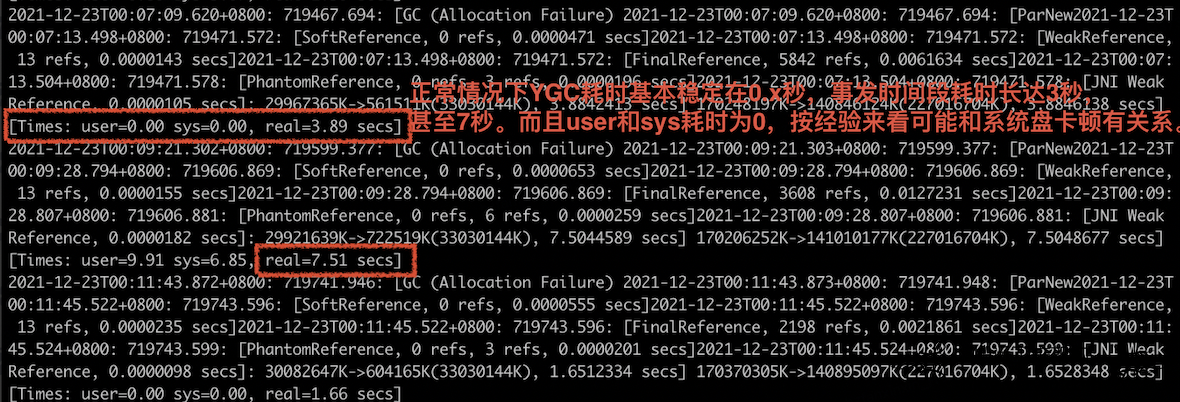
为什么YGC耗时卡顿这么长时间?
这里面一个最关键的信息点是多次YGC的user和sys耗时都是0.00秒,这说明这段时间根本就没有发生CPU的消耗。结合经验,如果user+sys的时间远小于real的值,这种情况说明JVM暂停的时间没有消耗在CPU执行上,而大概率卡顿在IO上。观察对应时间点节点磁盘IO利用率,发现系统盘IO确实被打满了。如下图所示:
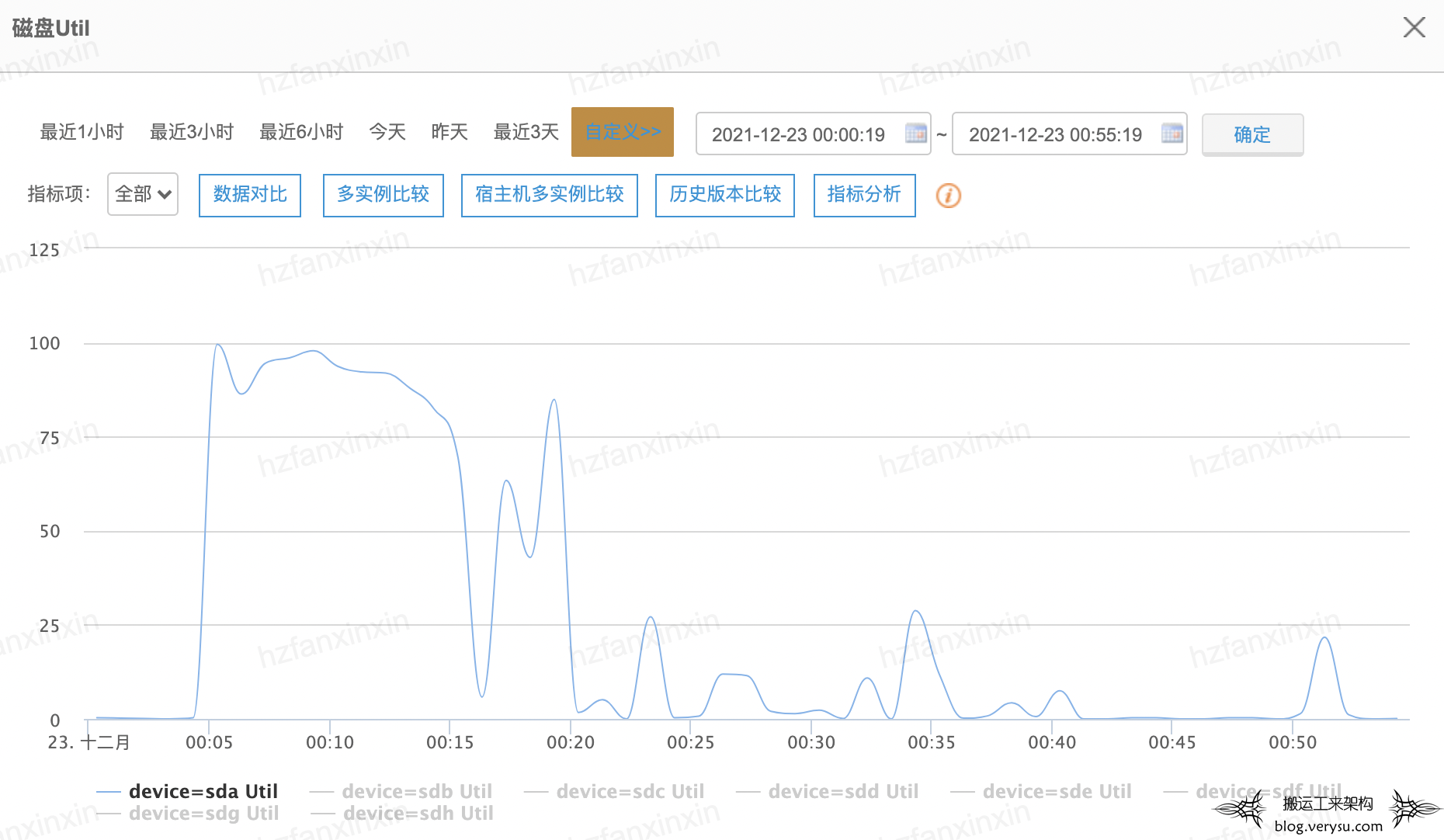
为什么系统盘IO会被打满?
那什么原因造成系统盘IO打满的呢?按照以往经验来说,一般有两种可能,一种可能是日志写入造成,一种可能是缓存换入换出造成。经过监控系统的进一步分析,确认这个IO是读IO,这就否定了日志写入这个可能性。如下图所示:
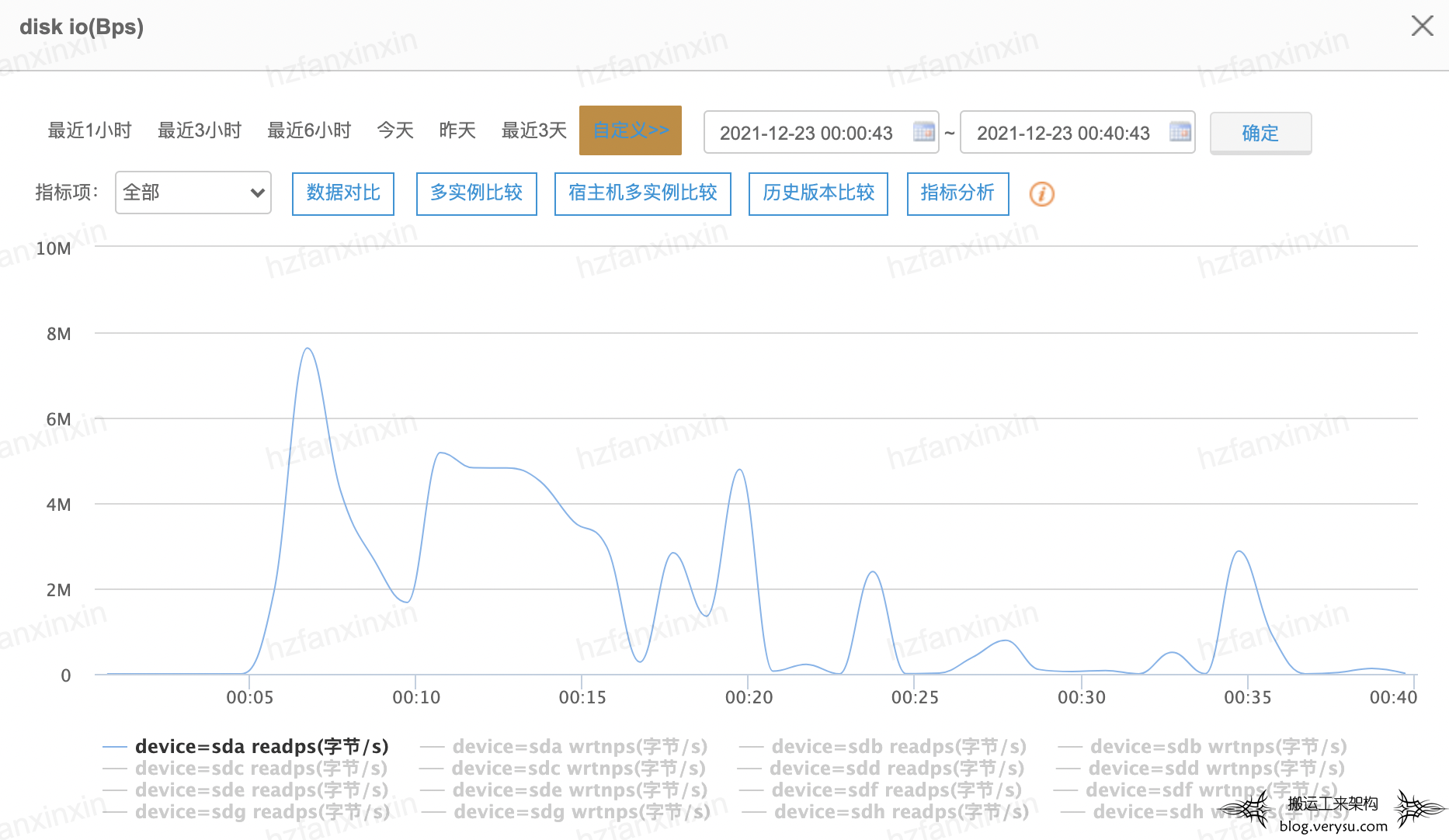
再结合对应时间段缓存换入换出次数的监控,基本可以确认系统盘IO打满是因为缓存大量换入导致。如下图:

为什么新版本上线后会频繁触发缓存换入呢?
经过进一步分析发现,这个节点上有一个脚本会周期性判断系统pagecache使用量是否超过一个阈值,如果超过的话就会执行清理操作。我们知道pagecache是用来缓存文件的,如果执行pagecache清理的话可能会导致短时间读文件都需要从磁盘上读,进而导致读IO增大。
那为什么新版本上线后会频繁触发这个问题呢?经过线下验证,NameNode新版本中部分新引入的功能会频繁读写日志文件,导致节点pagecache消耗非常快。这样就会更加频繁的触发脚本清理cache。
案例二. Ranger插件升级之后NameNode RPC大毛刺问题探究
这个案例是NameNode的Ranger插件升级之后产生的,所以有必有先介绍一下Apache Ranger。Ranger是Hadoop生态中各种组件权限审计管控的服务。比如HDFS,用户读取一个文件的话首先需要经过Ranger的鉴权认证的,如果权限认证成功,才能进行读取操作,否则就会报认证异常。
从技术层面看,用户读取HDFS文件首先会向NameNode发送一个读取请求,NameNode服务本身集成了一个Ranger插件,这个Ranger插件负责从Ranger Server拉取权限库信息到本地缓存,同时通过hook的方式监听NameNode读取请求,一旦有读取请求,Ranger插件拦截到用户信息以及文件路径信息,再根据权限库中信息进行匹配,如果能够匹配上就认证成功。
有了Ranger这个背景之后,再来看这个案例。生产线上一Ranger插件升级后,第二天查看主NameNode,发现请求处理RPC耗时出现较频繁的毛刺,平均请求处理耗时相比升级前也增加了60%+。如下图所示,其中hadoop3897是升级前的NameNode,平均请求处理耗时为18ms,Ranger升级后主NameNode切换到hadoop3898,平均请求处理耗时为33ms。很明显,升级后主NameNode频繁出现超过1s的请求处理毛刺。
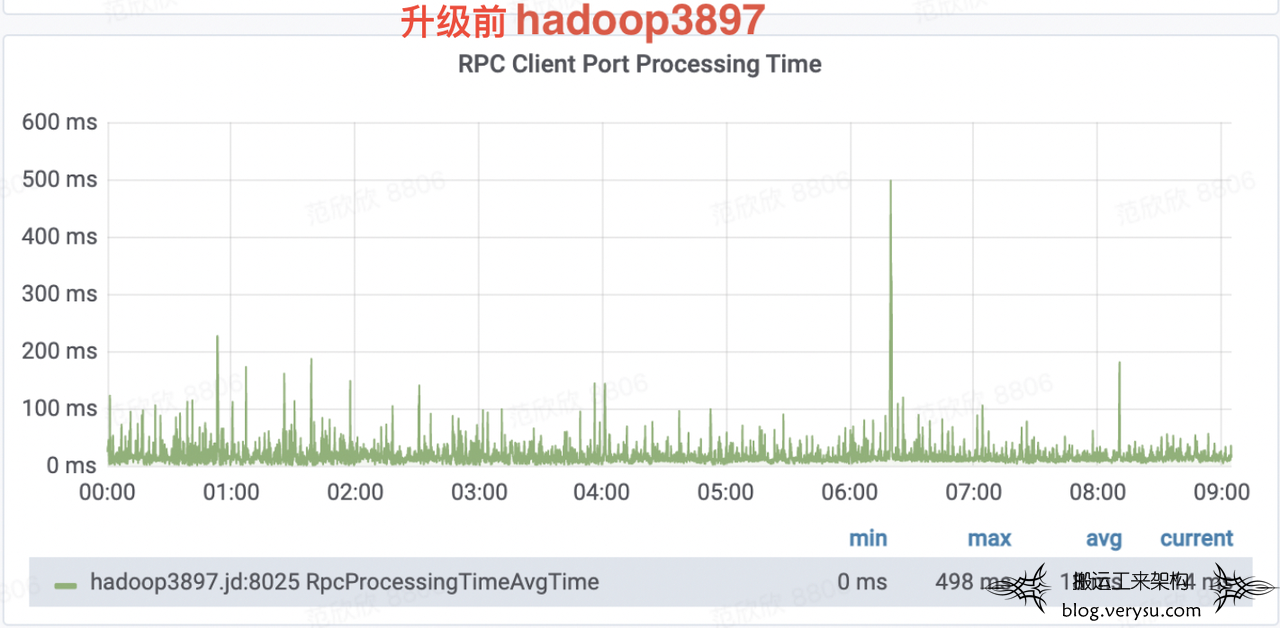
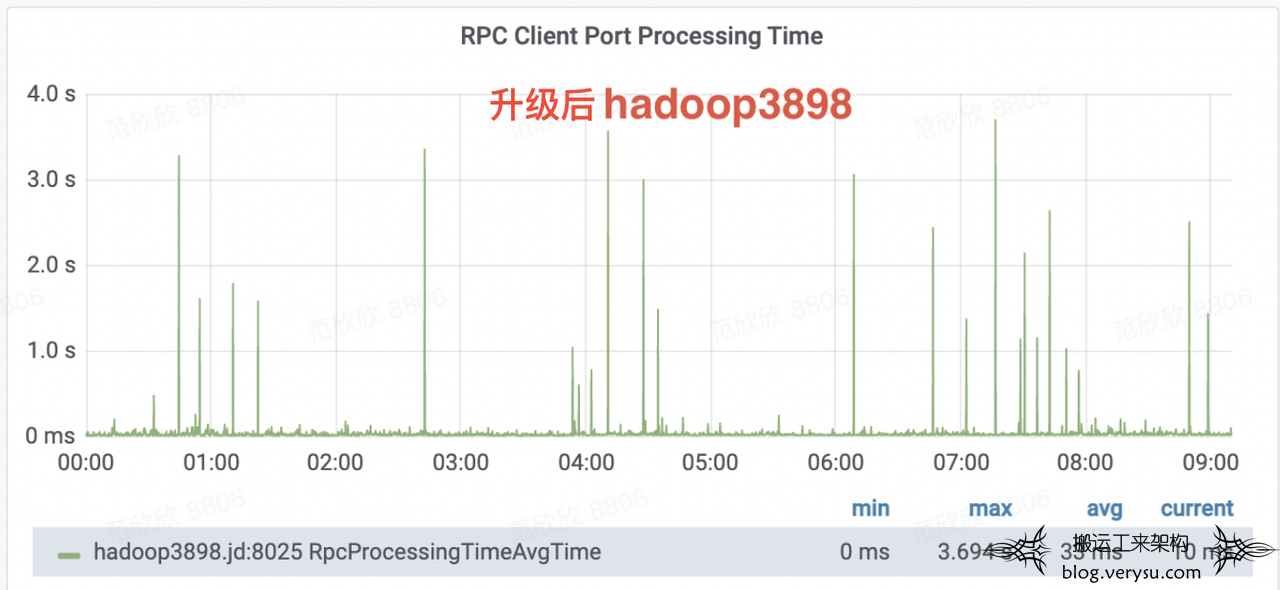
为什么PRC处理毛刺会出现?
NameNode切换到hadoop3898节点后出现请求处理毛刺这个现象在之前也出现过,当时猜测和机器本身有关系。为了排除这个因素,运维将主NameNode切换到hadoop3897节点(也已经升级过Ranger插件),切换后发现还是存在严重的性能问题。这种情况就不排除是因为Ranger升级之后引入的性能问题。
排查异常NameNode相关指标发现一个非常关键的线索,每分钟GC时间在升级之后出现明显增多,如下图所示:
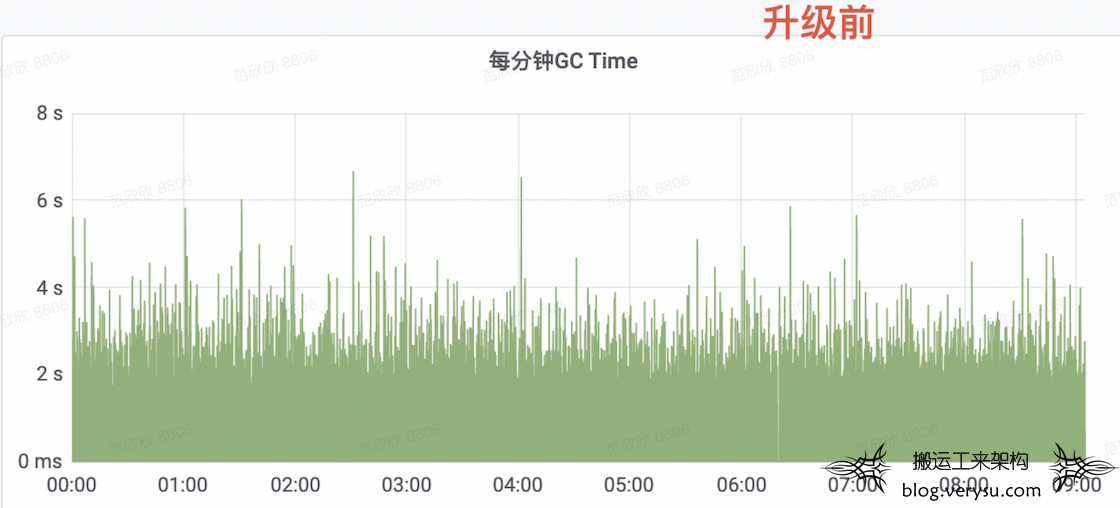
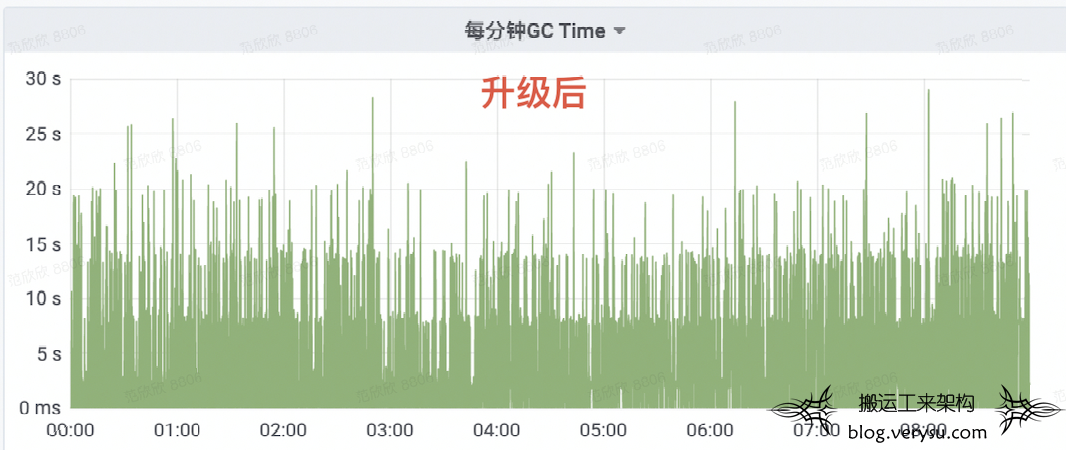
为了更细节地明确GC问题,查看相关的GC日志,发现两个重要事实:
- 升级后YGC的频率从平均20s一次增多到10s一次左右,而且可能会出现连续多次YGC耗时都超过1~2s的情况,对比升级前每次YGC耗时基本稳定在0.5s左右。
Desired survivor size 5368709120 bytes, new threshold 15 (max 15) - age 1: 845855096 bytes, 845855096 total - age 2: 315664752 bytes, 1161519848 total - age 3: 6367320 bytes, 1167887168 total - age 4: 389355792 bytes, 1557242960 total - age 5: 9163192 bytes, 1566406152 total - age 6: 37404216 bytes, 1603810368 total - age 7: 930872 bytes, 1604741240 total - age 12: 96928 bytes, 1604838168 total - age 15: 3352 bytes, 1604841520 total : 42842835K->1874036K(52428800K), 3.3199043 secs] 458215362K->417246566K(618659840K), 3.3203978 secs] [Times: user=15.94 sys=3.41, real=3.32 secs]
- 升级后CMS GC执行remark阶段耗时太长,会造成NameNode长达90秒的卡顿。
2021-11-17T18:33:09.820+0800: 179227.136: [Rescan (parallel) , 0.4236529 secs] 2021-11-17T18:33:10.244+0800: 179227.560: [weak refs processing, 93.3276296 secs] 2021-11-17T18:34:43.571+0800: 179320.888: [class unloading, 0.0895056 secs] 2021-11-17T18:34:43.661+0800: 179320.977: [scrub symbol table, 0.0107147 secs] 2021-11-17T18:34:43.671+0800: 179320.988: [scrub string table, 0.0025554 secs] [1 CMS-remark: 415575980K(566231040K)] 416281199K(618659840K), 94.1390159 secs] [Times: user=107.70 sys=10.29, real=94.14 secs]
至此基本可以确认NameNode请求延迟毛刺是因为Ranger升级之后导致NameNode进程YGC频率增多,且单次耗时增多导致。
为什么YGC和CMS GC Remark耗时变长了呢?
这里面最关键的一个线索来自于CMS GC Remark日志,如下所示:
2021-11-17T18:33:10.244+0800: 179227.560: [weak refs processing, 93.3276296 secs] ... 2021-11-17T18:34:43.671+0800: 179320.988: [scrub string table, 0.0025554 secs][1 CMS-remark: 415575980K(566231040K)] 416281199K(618659840K), 94.1390159 secs] [Times: user=107.70 sys=10.29, real=94.14 secs]
可以看到,remark阶段耗时94.14s,其中weak refs processing阶段耗时93.33s。那问题肯定出在对弱引用的处理上。当然要是为了降低weak refs processing阶段耗时,可以使用参数-XX:+ParallelRefProcEnabled开启并发处理。
为什么weak refs processing耗时这么长?
虽然开启并发处理参数可以简单粗暴的降低GC耗时,但是为什么Ranger插件升级之后出现了这个问题还需要进一步深挖。
weak refs processing主要包括SoftReference、WeakReference、FinalReference、PhantomReference以及JNI Weak Reference这五种Reference对象的处理。到底处理哪种引用对象耗时,需要添加参数-XX:+PrintReferenceGC,来具体显示各种Reference的个数和处理时间。在线下环境添加参数之后复现该问题,对应的GC日志(相对极端的一条)如下所示:
2022-01-17T14:51:26.616+0800: 2061.131: [GC (Allocation Failure) 2022-01-17T14:51:26.617+0800: 2061.131: [ParNew 2022-01-17T14:51:27.115+0800: 2061.630: [SoftReference, 0 refs, 0.0000930 secs] 2022-01-17T14:51:27.115+0800: 2061.630: [WeakReference, 156 refs, 0.0000494 secs] 2022-01-17T14:51:27.115+0800: 2061.630: [FinalReference, 1348 refs, 10.2301307 secs] 2022-01-17T14:51:37.345+0800: 2071.860: [PhantomReference, 0 refs, 95 refs, 0.0000758 secs] 2022-01-17T14:51:37.346+0800: 2071.860: [JNI Weak Reference, 0.0000177 secs]: 52844281K->5134129K(53476800K), 10.7291830 secs] 90304049K->43584416K(172316096K), 10.7294849 secs] [Times: user=20.36 sys=0.17, real=10.73 secs]
可以看到,这次YGC花费了10.73s,其中处理FinalReference的时间为10.23s,可见YGC问题是出在FinalReference的处理上。关于FinalReference的详细解读,可以参考《JVM源码分析之FinalReference完全解读》
为什么Ranger插件升级之后会导致FinalReference处理耗时变长?
FinalReference对象一般是某类重写了finalize方法,那具体是哪个类呢?通常的办法是使用jmap将堆dump下来使用MAT进行离线分析。然而实际测试环境要复现这个场景需要开比较大的堆,导致MAT分析比较困难。那有没有其他办法呢?
既然我们知道大概率是因为某个类重写了finalize方法导致的这个问题,那有没有什么方法从JVM中找到这个类呢?答案是肯定的,可以使用arthas的sm方法搜索JVM中某个方法。方法和结果如下所示:
[arthas@42668]$ sm org.apache.* finalize -n 10000 org.apache.hadoop.hdfs.protocol.RollingUpgradeInfo finalize(J)V org.apache.ranger.plugin.policyengine.PolicyEngine finalize()V org.apache.ranger.plugin.policyengine.RangerPolicyRepository finalize()V org.apache.ranger.plugin.contextenricher.RangerAbstractContextEnricher finalize()V org.apache.log4j.AppenderSkeleton finalize()V
可以看出就这么几个方法实现了finalize方法,结合这个现象是Ranger上线之后引入的,所以大概率怀疑是上面几个Ranger类有异常。和Ranger开发同学沟通后,确认他们新增了org.apache.ranger.plugin.policyengine.PolicyEngine中的finalize方法做相关对象的清理。问题代码如下:
protected void finalize() throws Throwable {
try {
/*120*/ this.cleanup();
}
finally {
/*122*/ super.finalize();
}
}
最终开发同学重新修改了cleanup的逻辑,不再使用finalize方法后问题得到了解决。
文章总结
本文结合HDFS生产线上NameNode的两次YGC异常现象,分别介绍了如何结合日志进行GC问题的排查分析。这里有两个比较常见的现象总结:
- 如果user+sys的时间远小于real的值,这种情况说明JVM暂停的时间没有消耗在CPU执行上,而大概率卡顿在IO上。
- 如果新生代GC时间比较长,可以尝试添加参数-XX:+PrintReferenceGC来确认各种Reference的个数和处理时间。确认是否是某种Reference的GC时间较长。
本文(https://verysu.com)仅供学习!所有权归属原作者。侵删!文章来源:作者 http://hbasefly.com/2022/01/19/gc-practise-parnew-cms-namenode-ygc/



文章评论