因为工作的需要,笔者前前后后分别接触了HBase RegionServer、HiveServerMetastore以及HDFS NameNode这些大内存JVM服务。 在和这些JVM系统打交道的过程中,GC优化始终是一个绕不过去的话题,有的是因为GC导致NameNode RPC请求耗时增大,有的是因为GC导致RegionServer/HiveServer/Metastore经常宕机。在优化的过程中,笔者花时间系统地学习并梳理了CMS、G1GC以及ZGC这几款垃圾回收器的原理,并基于这些原理进行了多次线上GC问题的定位以及优化。这个系列的文章初步安排了多篇:
- 【大内存服务GC实践】- 一文看懂”ParNew+CMS”组合垃圾回收器
- 【大内存服务GC实践】- “ParNew+CMS”组合垃圾回收器实践案例(一)
- 【大内存服务GC实践】- “ParNew+CMS”组合垃圾回收器实践案例(二)
- 【大内存服务GC实践】- 一文看懂G1垃圾回收器
- 【大内存服务GC实践】- G1垃圾回收器实践案例(一)
- 【大内存服务GC实践】- G1垃圾回收器实践案例(二)
- 【大内存服务GC实践】- 一文看懂ZGC垃圾回收器
- 【大内存服务GC实践】- ZGC垃圾回收器实践案例
从我们的认知说起
- JVM内存为什么要分代?
- 新生代GC触发条件是什么?简单介绍一下新生代GC算法。
- 在哪些条件下对象会从新生代晋升到老年代?
- 老年代GC触发条件是什么?简单介绍一下老年代GC算法。
- FGC触发条件是什么?
- 如果一个Java系统(CMS回收器,下同)新生代GC耗时长,可以考虑从哪些方面分析优化?
- 如果一个Java系统(CMS回收器,下同)老年代GC耗时长,可以考虑从哪些方面分析优化?
- 如果一个Java系统频繁发生FGC,可以考虑从哪些方面分析优化?
- 不同对象的生命周期是不一样的。可以大体分成两类,一类称为短寿对象,这类对象存活时间很短,比如局部变量、短链接对象。与之对应的称为长寿对象,比如数据缓存、session对象等。
- 大部分Java应用中短寿对象占比都占绝大多数,这类对象可以很快就会被回收。
如何判断一个对象是否活跃?
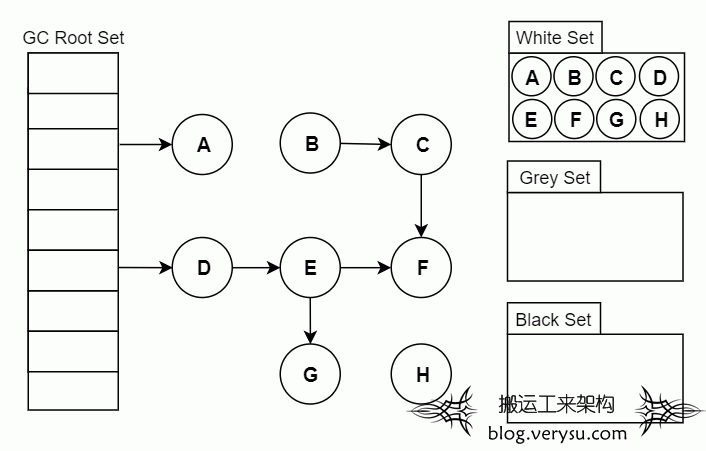
- 白色:尚未访问过。
- 黑色:本对象已访问过,而且本对象引用到的其他对象也全部访问过了。
- 灰色:本对象已访问过,但是本对象引用到的其他对象尚未全部访问完。全部访问后,会转换为黑色。
- 初始时,所有对象都在【白色集合】中。
- 将 GC Roots 直接引用到的对象挪到 【灰色集合】中。
- 从灰色集合中获取对象:
- 重复步骤3,直至【灰色集合】为空时结束。
- 结束后,仍在【白色集合】的对象即为 GC Roots 不可达,可以进行回收。
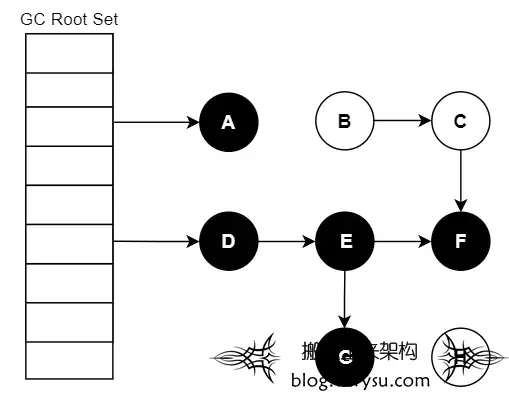
如何标记一个活跃对象?
如何跨区迁移对象?
- 在S1区为对象申请特定大小的内存。
- 初始化对象,并将对象的字段进行赋值。
- 全部迁移完成之后将Eden/S0区的所有对象清除。
如何修改引用对象指针地址?
有一个方案是扫描整个老年代的所有对象,但是这样的效率必然不高,尤其是在老年代内存设置非常大的情况下效率就会更差。于是JVM算法设计者设计了使用一个Card Table记录老年代对象到新生代对象的引用方案。
这里多说一句,通常有两种方法记录对象之间的引用关系,一种为Point Out,一种为Point In。假设有这样的引用关系,对象A的成员变量指向对象B(伪代码为:ObjA.Field = ObjB),对于Point Out的记录方式来说,会在对象A(ObjA)的Card Table中记录对象B(ObjB)的地址。对于Point In的记录方式来说,会在对象B(ObjB)的Card Table中记录对象A(ObjA)的地址,这相当于一种反向引用。这二者的区别在于处理时有所不同:Point Out方式在记录这种引用关系的时候比较简单,但是在反向查找时需要对Card Table做全部扫描。Point In记录引用关系操作相对稍微复杂,但是在标记扫描时可以直接找到有用和无用的对象,不需要进行额外的扫描,因为Card Table里面的对象可以看作根对象。”ParNew+CMS”组合回收器中老年代到新生代的跨代引用使用的是Point Out模式。
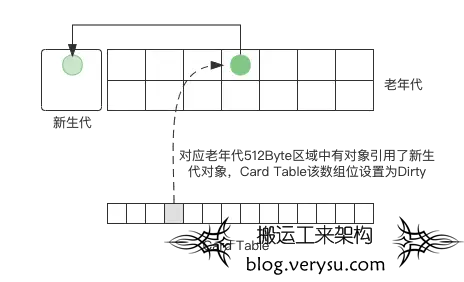
Card Table上的Card什么时候会被设置为Dirty?
- 躲过15次新生代GC后晋升到老年代(15是默认情况)。
- 大对象直接进入老年代。
- 动态对象年龄判断机制:假如当Survivor区中,相同年龄的对象总大小大于这Survivor区域总大小的50%,那么大于等于这批对象年龄的对象,在下次YGC后就会晋升到老年代。
- YGC后存活对象太多超过Survivor区大小,通过分配担保机制晋升到老年代。

现在我们深入地分析一下这些步骤:
1. 初始标记。从GC Roots集合以及新生代对象出发,标记直接引用的对象。示意图如下所示:
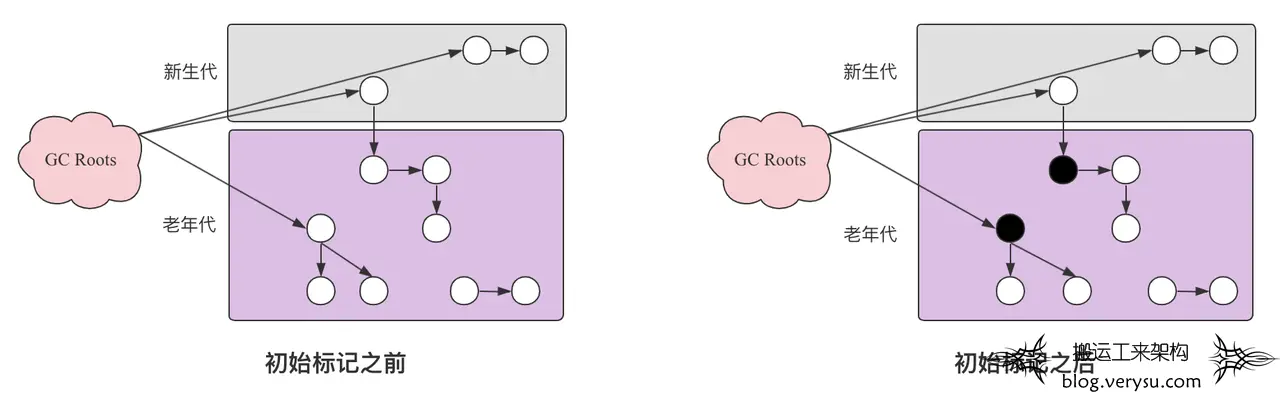
2. 并发标记。从初识标记阶段标记出来的对象开始基于”三色标记法”找出所有存活对象并标记。这个阶段应用线程会和标记线程并发执行。假如此时只有标记线程工作,那并发标记前后的示意图如下:
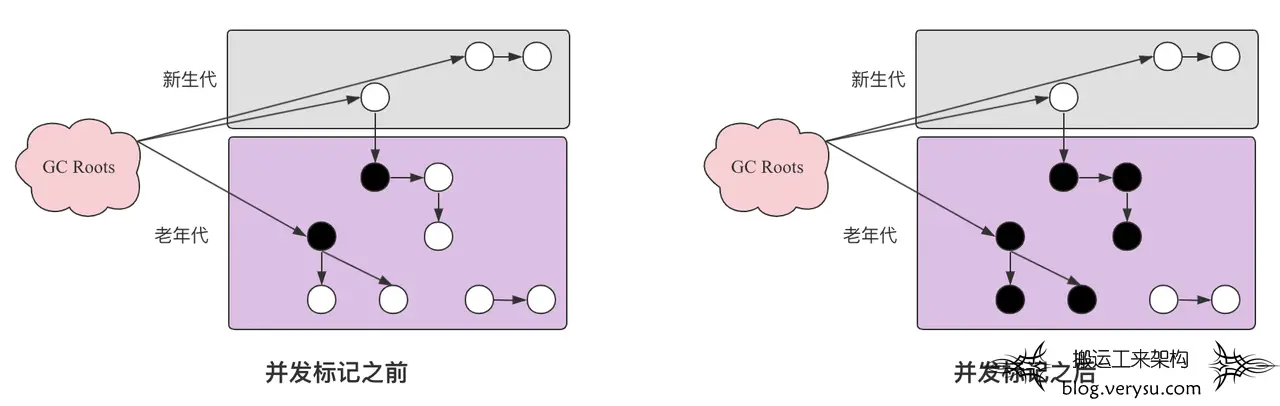
- 对象引用被删除。
- 应用线程直接在老年代分配新对象。
- 新生代对象晋升到老年代。
- 老年代对象之间引用发生变更。
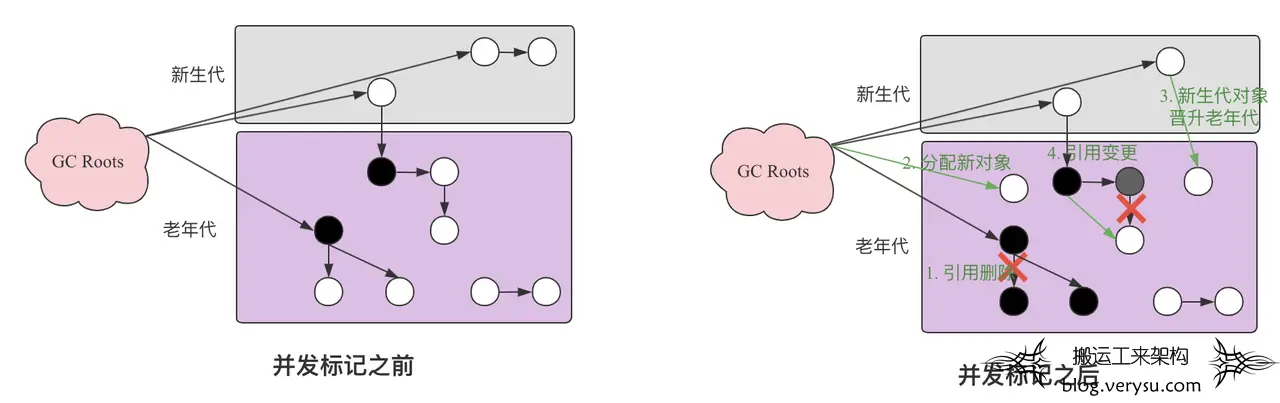
- 对象引用被删除(上图场景1):假如一个对象在被标记为活跃对象之后引用关系被删除。因为该对象已经被标记为活跃对象,所以它不会在本次GC中被回收。但是理论上来讲,这个对象是应该被回收的。应该被回收的对象没有被回收,这种情况不影响正确性,但会产生”浮动垃圾”。这种现象称为“多标”。
- 直接在老年代分配新对象(上图场景2):如果在标记线程执行结束之后应用线程重新new了一些新对象(比如大对象)并产生了引用关系。这些对象本应该被标记为活跃对象但实际上没有被标记,就会出现正确性问题。这是“并发标记”引入的第一个问题。
- 新生代对象晋升到老年代(上图场景3):因为应用线程在工作,所以Eden区就可能会满,进而触发YGC,YGC之后就会有新生代对象晋升到老年代。晋升到老年代的对象本应该被标记为活跃对象但实际上没有被标记,就会出现正确性问题。与场景2类似。
- 老年代对象之间引用发生变更(上图场景4):这个场景稍微复杂一点,使用下面的示意图分析一下。
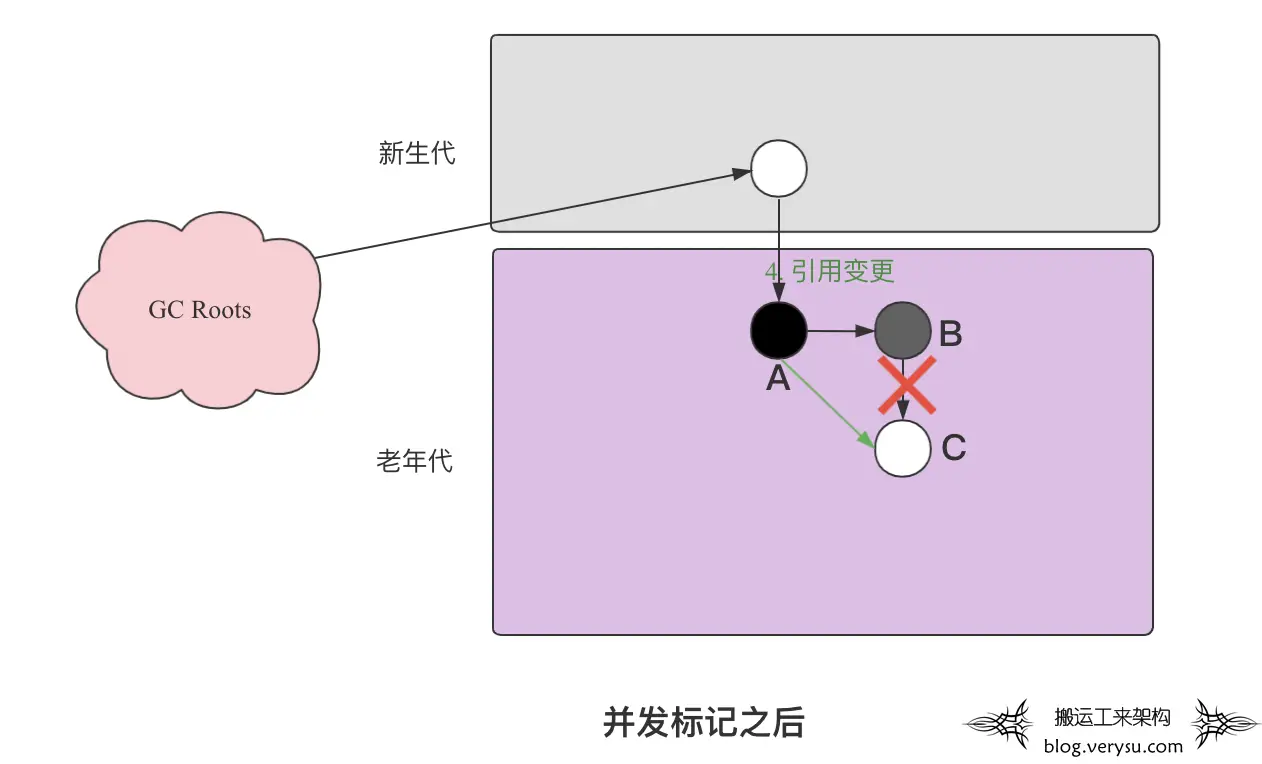
假设标记线程已经遍历到对象B(回想三色标记法,对象B变为灰色),这个时候应用线程执行了如下代码:
objB.fieldC = null; objA.filedC = C;
对应示意图中对象B和对象C之间的引用关系断掉,然后对象A和对象C之间建立新的引用关系。注意对象A和对象C之间虽然建立了新的引用关系,但是对象A已经是黑色了,不会再重新做遍历处理了。最终导致的结果就是:对象C会一直是白色,最后被当作垃圾清理掉。很显然,这直接影响到了应用程序的正确性,是不可接受的。这种现象称为“漏标”,这是“并发标记”引入的第二个问题。
可见,并发标记可以让应用线程与标记线程一起工作,不需要STW。但是会引入如下两个问题:
- 新增老年代对象没有被标记。
- 引用变更导致的漏标问题。
对于场景4,如果在引用变更的时候记录下对应的对象,比如上述场景如果能够记录下对象A,重新标记的时候从对象A开始重新标记,就可以相对快速的完成重新标记。实际实现中再次用到了上文介绍到的Card Table,当引用发生变更时,将对象A所在的Card标记为Dirty。后续只需扫描这些Dirty Cards的对象,避免扫描整个老年代。
这里有一个问题,如果在老年代并发标记的过程中同时发生了一次YGC。上文我们说过YGC会扫描Card Table中的Dirty Cards,找到跨代引用,同时在YGC完成后将Dirty Cards清空。很显然,增量更新和YGC这两个过程共用Card Table会产生冲突,一旦YGC完成之后将某个Dirty Card清空,但是这个Dirty Card刚好是”并发标记”过程中引用变更标记的,就会导致漏标。为了解决这个问题,CMS算法引入另一种数据结构Mod Union Table,它是一个位数组,数组中每个元素分别对应一个Card。基于这个新结构,在每次YGC处理完脏卡之前,会将该Dirty Card在Mod Union Table中对应的数组位置1。这样CMS在执行重新标记阶段的时候,扫描Mod Union Table和Card Table里面被标记的项,找到所有可能的Dirty Card。
3. 并发预处理。
4. 可中断预处理。
这两个阶段都是为了尽可能降低重标记阶段的耗时,采用增量更新的方式重新标记”并发标记”阶段新增的对象。这两个阶段依然是应用线程和标记线程并发执行的,所以还是会有新增对象产生,不过数量会降低很多。
5. 重标记。
- 遍历GC Roots,标记直接关联的没有被标记的老年代对象以及引用链上的对象。
- 遍历新生代对象,标记直接关联的没有被标记的老年代对象以及引用链上的对象。
- 遍历老年代的Dirty Cards,重新标记。
- 使用distcp全量拷贝一次数据。这个过程distcp和业务写入并发进行。(对应并发标记)
- 使用distcp -update增量拷贝一次或者多次数据。这个过程distcp和业务写入并发执行。(对应并发预处理)
- 经过上述两个步骤之后,可以认为需要增量拷贝的数据已经不多了。这个时候暂停写入,再使用distcp -update增量拷贝一次就完成了表的迁移。(对应重标记)
通过这种方式迁移对业务的影响应该是最低的。
6. 并发清理。
经过上述一系列的标记之后,没有被标记的对象就一定是垃圾对象。这些垃圾对象会被并发清理释放内存空间。
7. 并发重置。
- Concurrent Mode Failure模式FGC。上文我们讲过老年代使用内存占总堆大小超过阈值-XX:CMSInitiatingOccupancyFraction的话就会触发老年代GC。老年代GC的”并发标记”阶段是应用线程和标记线程一起工作的,假如在并发标记的过程中,不断有对象晋升到老年代最终导致老年代内存放不下这些对象的话,就会触发Concurrent Mode Failure模式FGC。根据字面意思也可以猜到这种FGC和并发执行有关系。
- Promotion Failure模式FGC。从字面意思来看是晋升失败,是一次新生代GC之后部分对象要晋升到老年代,但是老年代没有足够内存容纳这些对象导致FGC。通常来说,是因为老年代存在大量的内存碎片导致这种模式的FGC。
- CMS算法为什么要分代?
- 其中新生代GC触发条件是什么?简单介绍一下新生代GC算法。
- 在哪些条件下对象会从新生代晋升到老年代?
- 老年代GC触发条件是什么?简单介绍一下老年代GC算法。
- FGC触发条件是什么?
https://www.jianshu.com/p/2a1b2f17d3e4
本文(https://verysu.com)仅供学习!所有权归属原作者。侵删!文章来源:作者 http://hbasefly.com/2022/01/13/gc-practise-parnew-cms-metastore-fullgc/



文章评论
并发清理并不会STW