Metastore服务是Hive的核心组成部分,是整个hadoop大数据体系的元数据基石,所有数据表相关schema信息、partition信息、元数据统计信息等都存储在Metastore所依赖的MySQL中,通过Metastore服务执行各种元数据操作。Metastore服务一旦长时间异常,所有依赖服务(诸如HiveServer、Spark、Impala等)就都会出现功能或服务异常。
Metastore是一个相对成熟的服务,通常情况下不会发生特殊的异常。但和所有的数据库系统一样,一旦上层业务使用姿势不对的话,是可能导致发生一些莫名其妙的系统异常。这篇文章重点介绍两起因为上层业务使用用法不恰当导致Metastore服务频繁FGC,底层MySQL负载飙升问题。
之前有段时间,Hive运维反馈三天两头Metastore服务会发生FGC,发生FGC之后只能通过重启来解决,好在重启对业务的影响可控。
最直观的现象是Metastore服务的内存会出现飙升,如下图所示Metastore内存忽然升高,old区内存达到一定阈值之后发生CMS GC,但是GC执行后GC不出来可用内存,此时还在不断产生大量对象,导致发生长时间的FGC,服务与Zookeeper失联。
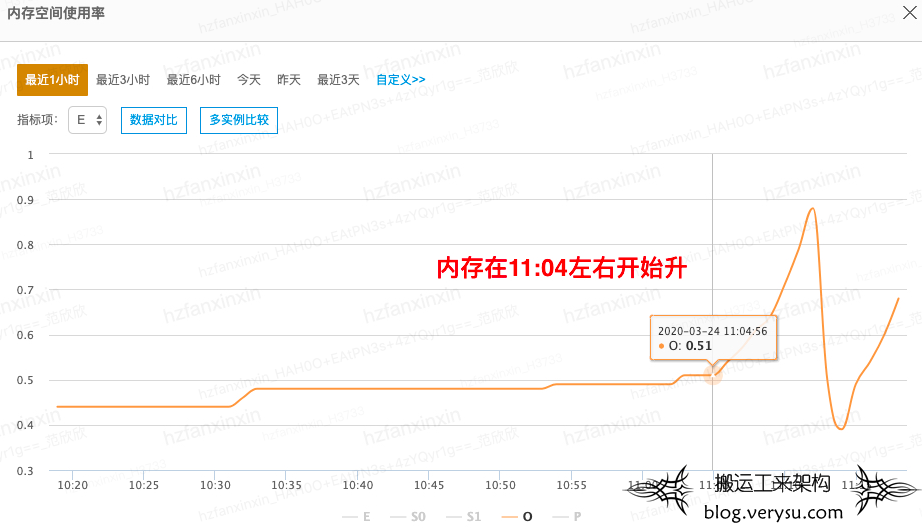
上图只显示出了内存飙升的那个时间点,并没有记录下GC不出来可用内存,但是在之后那条黄线持续高位,每次GC只会掉下来一丢丢,因为距离当时太久,原始监控数据已经不可查,在此说明。
内存升高从理论上分析肯定是短时间内产生了大量的Java对象,结合Metastore服务在之前没有出现类似现象,而最近一周频繁出现,那基本上可以推断出应该是一个特殊任务在执行或者不断地频繁执行。只有找到这个任务才能让用户停止执行并进行修正,从根本上解决这个问题。那怎么才能找到这个任务呢?
这个问题应该这样分析,先从内存升高这个表象关联到可疑Metastore命令,再通过可疑Metastore命令关联到用户执行的可疑任务。第一阶段需要Metastore侧进行排查。第二阶段则需要业务配合抓现场,平台端提供下发可疑API的ip、用户等基本信息,用户通过抓现场正在运行的任务逐个排除。这主要是因为执行的任务和Metastore命令之间的关联性非常弱,如果不是非常特殊的命令,是很难关联到具体的任务。
接下来进行第一阶段的排查工作,如何从内存升高这个表象关联到可疑的metastore命令。
- 排查一:首先排查了Metastore服务相关metrics,确认Metastore的连接数和之前相应时间区间的连接数基本相同,基本排除因为外部请求太多导致的内存升高可能。
- 排查二:使用jmap命令jmap -histo:live 13176 | head -n 10查看Metastore进程最多的10个存活对象。存在类似的FiledSchema对象很多,但是对应不到对应的接口,更对应不到任务。
- 排查三:根据Metastore日志排查事发点所有执行过的Metastore API。这也是一个笨办法,但是也是一个还可行的方案。Metastore日志中一个时间段可能执行大量命令,很难从日志中看出非常明显的问题。好在我们内部有一个基于日志数据解析实现的一个审计监控,可以查看特定时间段内某Metastore上所有Metastore API的执行频次。通过查看对应时间段执行的命令执行频次,发现对应时间段内get_multi_table命令频次也同步升高。拉长时间段看,get_multi_table命令频次和内存升高基本是同步的。如下图所示:
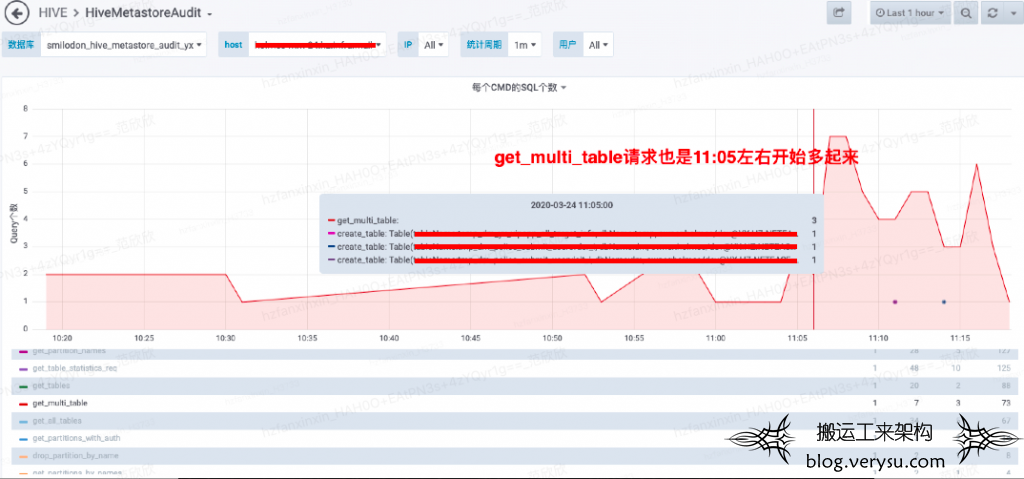
再查看对应get_multi_table的具体参数,发现这个命令确实比较可疑,如下所示这个命令的参数真是一大堆:
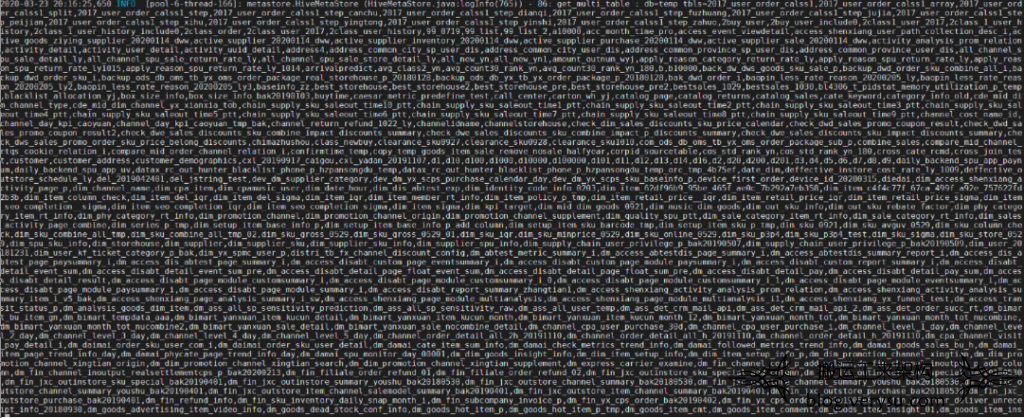
到这个阶段,基本可以确认内存升高和get_multi_table这个命令有关系。联系对应开发同学,询问是否在这个时间点执行过temp数据库的什么任务。开发刚开始是一脸懵逼,很多任务都用到了temp这个数据库,但是执行get_multi_table这个命令,还带着这么多参数的任务好像没有。过了一会,开发同学找过来,会不会是这样一个bug:
严选|数据|xxx 3月31日 15:17:46
严选|数据|xxx 3月31日 15:17:59
在hue里面写代码的时候temp会友情提示表
这完全有可能呀,于是我们就做了几个相关的实验,用户每次使用Hue智能提示之后我这边观察get_multi_table命令是否有下发,Metastore内存是否有升高。经过几轮实验,基本确认了罪魁祸首就是hue的智能提示功能。
找到问题之后业务同学调研了hue的用法,确认可以禁用智能提示功能,于是禁用了hue的智能提示功能,禁用之后问题得到解决。

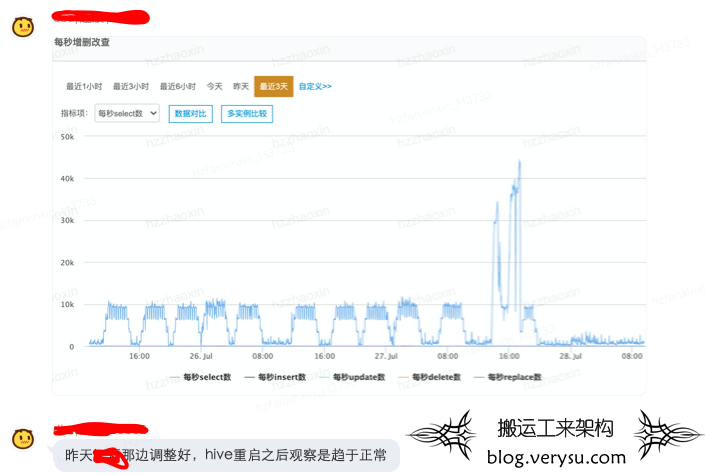
最近一周线上另一个集群Hive Metastore运维反馈频繁出现FGC现象,同时伴随MySQL负载飙升,MySQL 负载飙升主要是因为执行了每秒上万次select请求。如下图所示:
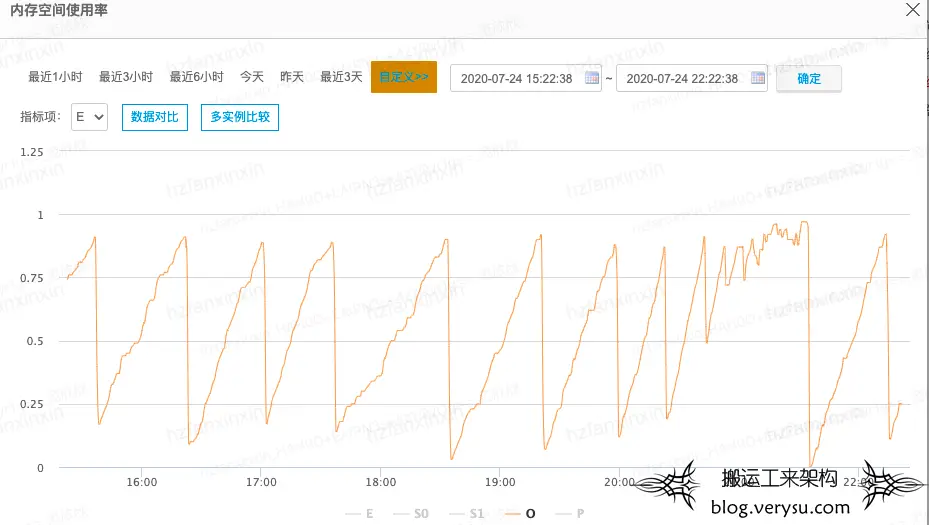
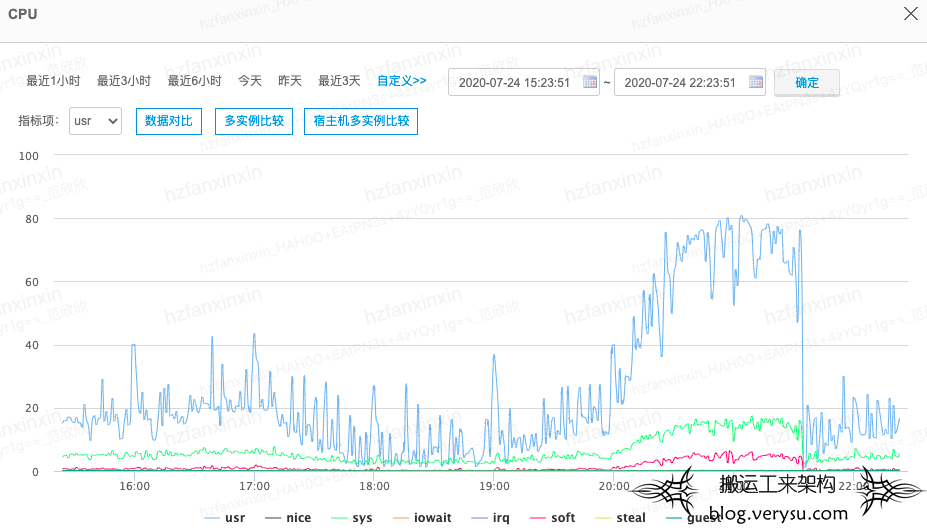
基本上可以确认Metastore向MySQL下发了大量的查询SQL导致MySQL负载升高,出口带宽飙升,同时自身内存暴涨而且释放不掉。
和上一个案例相似,这次排查需要先从内存升高这个表象关联到可疑的Metastore命令,再通过可疑Metastore命令关联到用户执行的可疑任务。
- 排查一:排查了Metastore的metrics指标,无明显异常。通过jmap排查存活对象,没有非常有用的信息。
- 排查二:直接排查事发时间窗口的Metastore API执行频次曲线图,没有发现非常高频的API调用。排查到这里,发现和上个案例的情况还不太相同,无法复用上次的排查思路。那怎么分析这个问题呢?可以换个方式,通过arthas自带的async-profiler查看此Metastore中什么执行逻辑占用内存最多,这样的话应该可以直接将内存飙升和对应的执行命令关联上。
- 排查三:使用async-profiler查看内存使用情况,得到如下内存使用火焰图:

根据上图可以看到,get_partitions_ps_with_auth命令占用的内存最多,初步怀疑这个命令比较可疑。好了,这次发现可以直接用async_profiler工具将内存飙升这个现象和对应的执行命令直接关联上,不用绕很大的弯子。
到了这一步,就要开始第二阶段的排查了。使用平台提供的监控排查问题时间窗口所有get_partitions_ps_with_auth命令的执行情况,如下图所示:
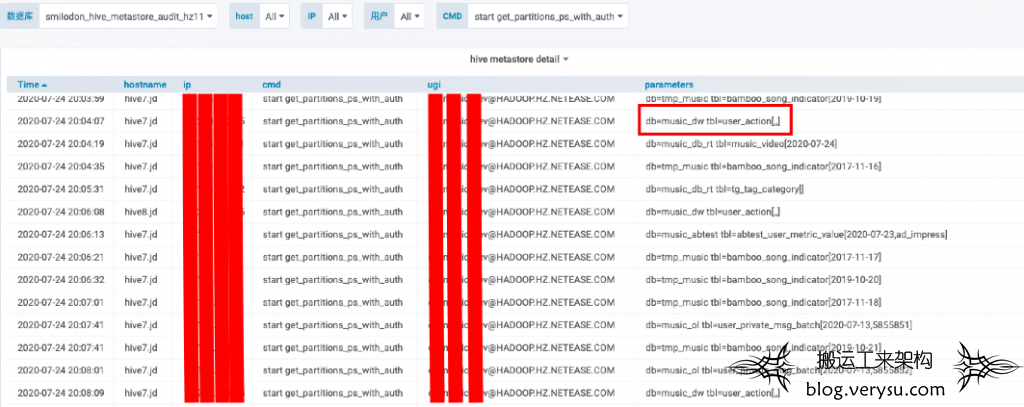
排查发现一个新情况:这个时间段发生了多次扫描user_action全表分区的get_partitions_ps_with_auth请求,需要说明的一点是user_action这个表是云音乐最大的一张表,包含几百万分区,所以强烈怀疑这样的请求有问题,同时也发现这些请求都来自于同一个ip,于是通过这个ip过滤,发现在事发窗口每隔几分钟就会执行一次这个命令,如下:
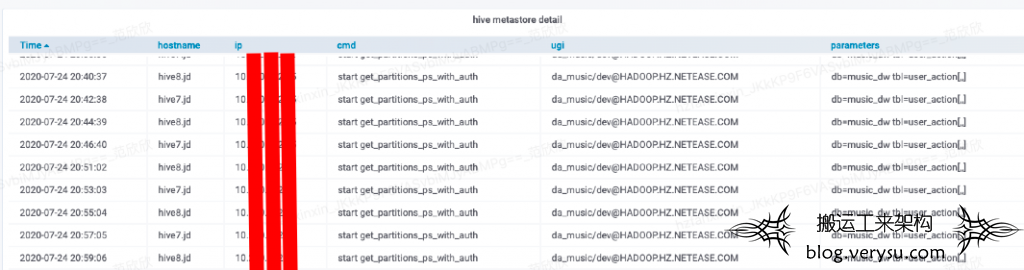
同时发现其他正常时间窗口这个命令就基本没有下发,现在基本可以得到进一步的信息是:在这个节点上有任务每隔2分钟就下发一次扫描user_action全表分区的命令到Metastore,导致Metastore内存飙涨。
带着这样的信息和音乐相关数据开发同学沟通,先通过时间排查时间窗口执行的所有任务,再review这些任务中对表user_action的操作,最终发现有一些任务SQL代码有问题,导致会全量查找user_action的所有分区。另外,发现业务并不是每隔几分钟请求一次,而是hive客户端超时重试逻辑。
排查出问题之后,业务将相关的逻辑进行了修改,重新上线。同时将hive客户端超时重试逻辑进行修改,将重试次数从10次降低到2次。修改之后,Metastore内存和MySQL负载飙升问题都得到了解决:
本文主要总结了线上Hive Metastore组件发生FGC之后的一些排查思路,重点介绍了一些基础手段和方法。这里面重点提到了如何使用arthas自带的async-profiler工具排查这类内存占用很大的问题,async-profiler是一个非常有用的工具,在生产线上排查了多次内存/CPU异常问题,在此向各位进行推介。当然,arthas还有很多非常有用的命令,可以帮助我们解决很多奇怪的问题,后面文章会分别进行介绍。
本文(https://verysu.com)仅供学习!所有权归属原作者。侵删!文章来源:作者 http://hbasefly.com/2022/01/13/gc-practise-parnew-cms-metastore-fullgc/



文章评论