笔者在这个系列的第一篇文章《一文看懂”ParNew+CMS”
垃圾回收器》中详细介绍了”ParNew+CMS”垃圾回收器的工作原理。文章最后笔者提到CMS垃圾回收器有两个比较显著的问题,一个是长时间运行无法避免Full
GC,一个是Remark阶段STW时间较长。正是因为这两个问题的存在,CMS垃圾回收器在JDK9被标记弃用,慢慢开始退出历史舞台。有走的,就有来的,JVM重新设计了另一款垃圾回收器G1,有效地解决了CMS垃圾回收器遇到的上述两大问题。那么,这篇文章我们就详细探讨一下G1垃圾回收器是如何解决上述两大问题的。
和上篇文章介绍”ParNew+CMS”垃圾回收器一样,笔者会从G1垃圾回收器最基础的数据结构和算法出发,深入分析它的工作原理,对其中的一些关键机制进行剖析。
为什么CMS垃圾回收器长时间运行无法避免FGC?本质是因为CMS垃圾回收器中老年代采用标记清理算法,这种算法会产生较多内存碎片,当内存碎片很碎无法给对象分配出连续空间的时候,JVM就会触发FGC整理老年代。那有些同学就会问为什么不在每次老年代GC的时候执行整理操作呢?这主要是因为老年代如果很大的话,整理一次STW的时间会不可控。那怎么破这个局呢?JVM设计者提出了一个思路:老年代不是很大吗,那就将老年代划分成很多小的格子,在此基础上GC算法基本不变,还是先标记,不过在标记完成后,按照优先级选择部分格子使用复制算法进行整理,这样每次整理的内存空间是可控的,STW的时间就相对可控,而且因为使用复制算法就不再会出现内存碎片。对,这就是G1垃圾回收器的核心设计思想。
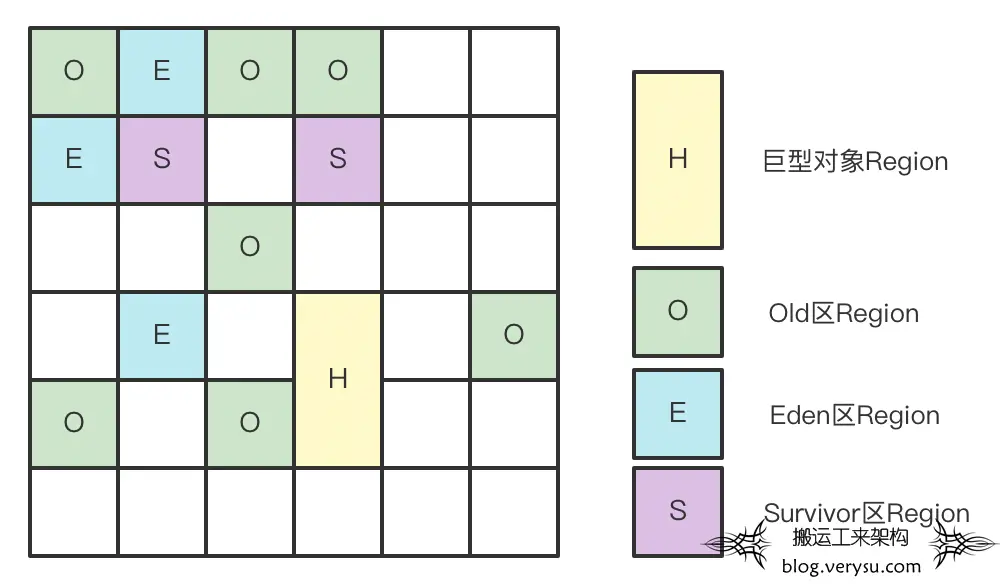
G1 是一个分代回收器,它依然保留了”ParNew+CMS”垃圾回收器中新生代和老年代的分代逻辑。但与”ParNew+CMS”回收器不同的是,它引入了一个新的数据结构 – Region,也就是上文中笔者提到的小格子。G1垃圾回收器会把整个堆划分成一个个大小相等的Region,每个Region的大小可以通过参数设置,通常大小在1~32M之间,默认大小取决于总堆的大小。下图是G1回收器堆划分的示意图:
上图中整个堆区会被划分为新生代以及老年代,其中新生代又分为Eden区和Survivor区,这和”ParNew+CMS”回收器是相同的。不同的主要有两点:
- G1回收器不要求新生代或者老年代的Region连续分布,换言之,这些Region可以随意分布在整个堆区,它和新生代或者老年代的隶属关系属于逻辑隶属。
- 如果一个对象大小超过Region大小的一半,就会被视为巨型对象(Humongous Object),巨型对象会被分配到Humongous Region。
1.2 RememberedSet(RSet)和Card Table
《一文看懂”ParNew+CMS”垃圾回收器》文章在介绍对象标记的时候重点说明了一个对象跨代引用的问题。比如YGC阶段标记新生代对象的时候,不仅需要扫描GC Roots标记其直接引用的新生代对象,还需要扫描所有老年代对象,查看其是否引用了新生代对象,如果引用了的话,对应新生代对象也是需要标记的,否则就会发生漏标。然而实际实现中,扫描整个老年代对象的代价相当大。文章中我们介绍了可以通过Card Table这种数据结构大幅降低扫描老年代对象查找跨代引用的代价,简单来说,就是通过写屏障技术在老年代对象引用新生代对象的时候将Card Table对应Card设置成”脏卡”,这样的话,查找跨代引用,只需要扫描Card Table脏卡对应的老年代区域,而不需要扫描整个老年代,大大降低了扫描代价。
根据上文介绍,G1也是一个分代回收器,也需要处理跨代引用扫描代价大的问题。为了解决这个问题,G1引用了另一种新的数据结构 – Remembered Set,简称RSet。
1. RSet是什么样的数据结构呢?
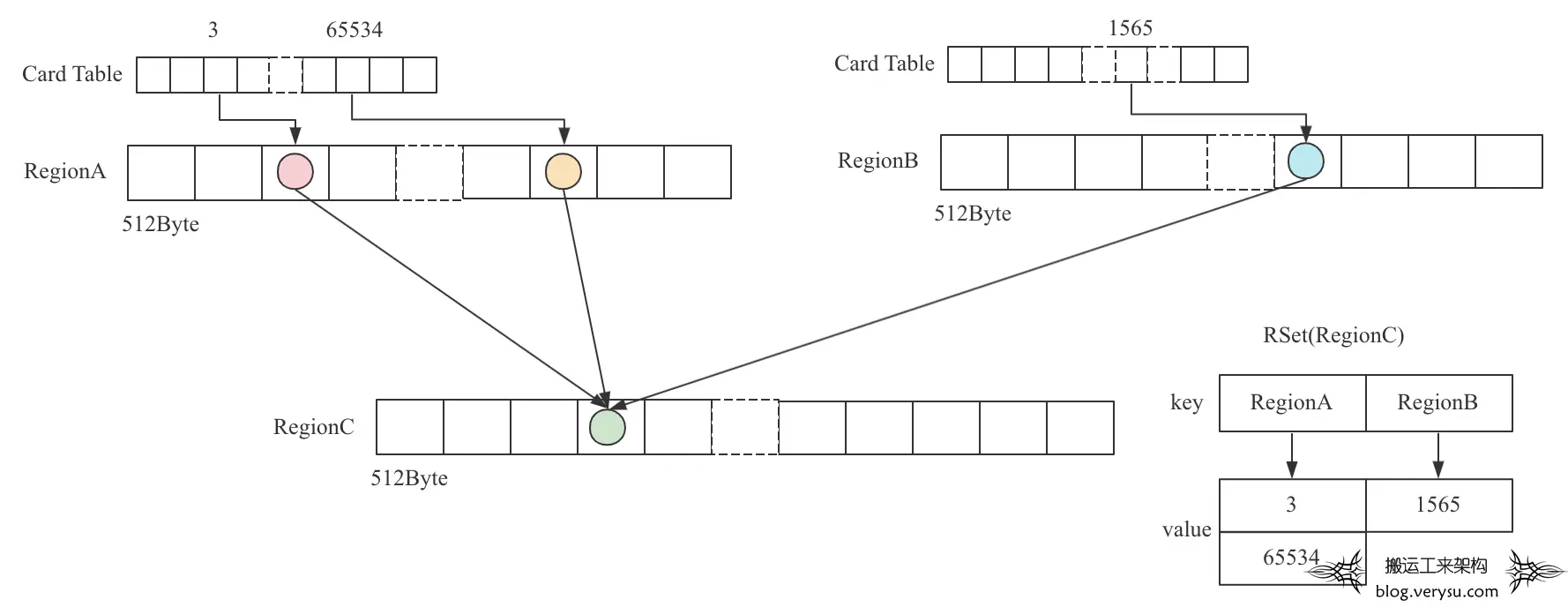
在G1实现中,每个Region会被划分成很多512Byte大小的小块,这样一个32M的Region就会被划分为65536个小块。与之大小对应的会有一个长度为65536的Card Table数组,数组的每个元素只有1Byte,对应Region的每个小块。Card Table数组这个结构和CMS垃圾回收器中Card Table是相同的。
除了Card Table数组之外,每个Region还会有一个RSet数据结构,RSet主要用来记录哪个Region的哪个Card上的对象引用了本Region中的对象。实际实现中,RSet默认是一个HashMap,Map的key是引用Region,value是一个List,List中存储引用Region中的引用Card列表。Region、Card Table以及RSet的示意图如下所示:
上图中,RegionA和RegionB中分别有对象引用RegionC中的对象,在RegionC对应的RSet就会记录这样的引用关系。该RSet中有两个KV对,第一个KV对的key是RegionA,value是一个列表,列表中有两个元素3和65534,分别代表RegionA中引用对象在对应Card Table中的下标。第二个KV对的key是RegionB,value中列表只有一个元素1565,代表RegionB中引用对象在对应Card Table中的下标。
介绍到这里,大家应该对RSet的结构有了初步的了解。与CMS回收器中Card Table相比,Card Table中的脏卡代表”我引用了别的对象”,属于一种points-out结构。而RSet记录的是哪些其他Region引用了本Region中的对象,属于points-into结构。两者是有本质区别的。
按照上述介绍,如果一个Region是热点Region,表示这个Region中的对象被大量其他Region中的对象所引用,那么RSet占用的内存空间开销就会越大。但我们要清楚一点,RSet内存开销不是为业务服务的,实际上不应该占用太多。因此为了控制RSet占用内存空间的大小,RSet会根据引用Region个数的多少,设置3种不同的实现方式(上文中介绍的是其中一种),分别称为:
- sparse per-region-table (PRT),从字面意思来看表示这个RSet是一个稀疏的集合。具体实现使用HashMap方式记录引用关系,其中Map的key是引用Region,value是一个List,List中存储引用Region中的引用Card列表。上文有过介绍。
- fine-grained PRT,还是使用HashMap方式记录引用关系,其中Map的key是引用Region,但value不再是List,而是一个bitmap,bit位为1表示对应Card是引用Card,否则不是引用Card。
- coarse-grained bitmap,从字面意思可以看出来这就是一个bitmap,不过bitmap中每个bit位引用粒度不再是Card,而是Region。如果bit位值为1,表示这个Region是引用Region,即这个Region中有对象引用了该Region中的对象。
很显然,上述3种实现方式中,spase PRT和fine-grained PRT都是精确到Card,而coarse-grained bitmap是精确到Region。
2. G1是如何管理RSet的?
G1会创建一个用于管理RSet的线程池,这些线程称为Refine线程。G1中RSet的更新不是同步完成的,G1会把所有引用关系都先放入一个队列中,称为Dirty Card Queue(DCQ),然后使用Refine线程来消费这个队列完成引用关系的记录并更新RSet。如果Refine线程忙不过来,GC线程以及应用线程也可能会协助更新RSet。
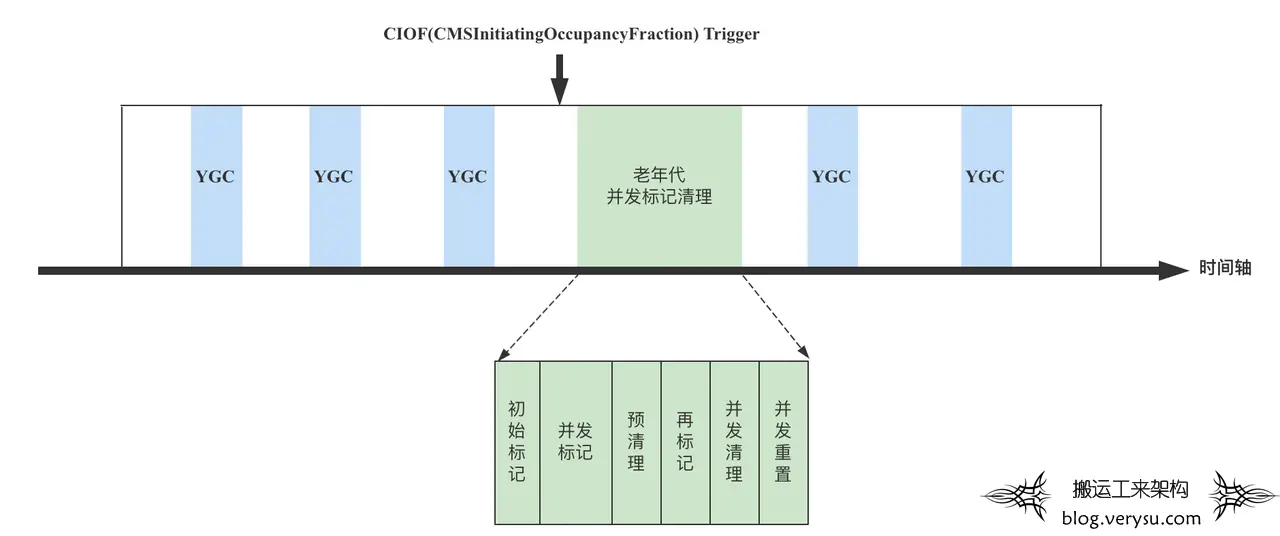
在介绍G1垃圾回收器工作流程之前,先简单回顾一下”ParNew+CMS”回收器的工作流程,具体流程不再赘述,参考下图:
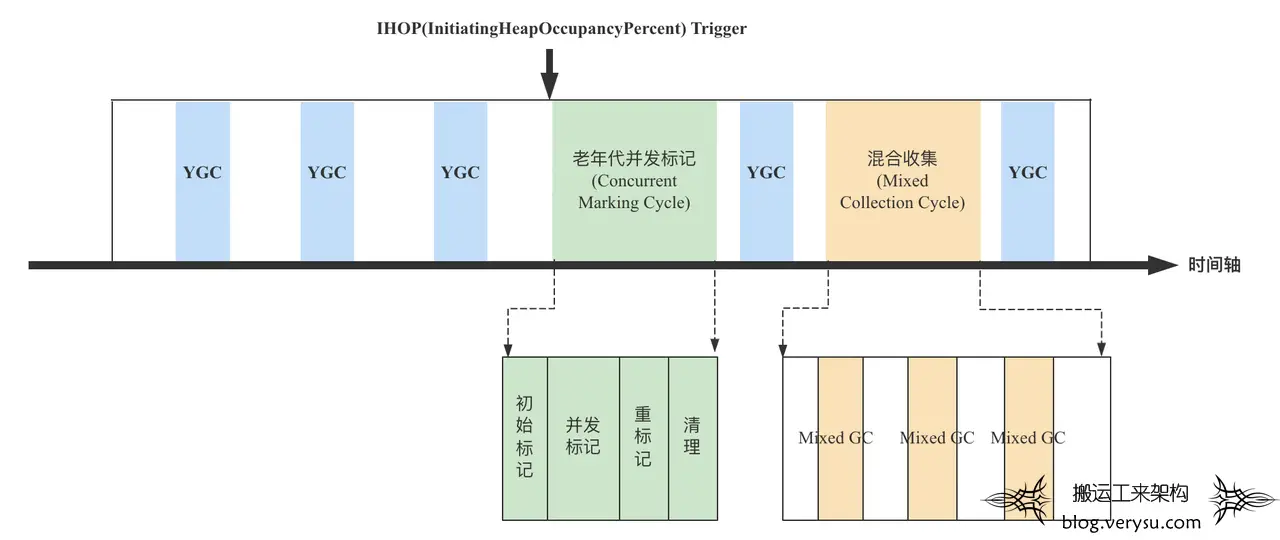
G1回收器核心工作流程与”ParNew+CMS”回收器基本相同,参考上图看下图:
对比”ParNew+CMS”回收器工作流程,G1中同样会比较频繁地进行新生代YGC,同样也有老年代并发标记周期。不同的是,G1在并发标记之后并没有直接清理全部垃圾对象,而是新增了一个混合收集周期,这个周期包含多次Mixed GC,每次Mixed GC只会回收部分Region,直至未处理Region集合占比低于特定阈值。之所以将这个周期称为”Mixed Collection Cycle”,是因为每次Mixed GC都会同时回收新生代和老生代中的Region。
上图中,IHOP(InitiatingHeapOccupancyPercent) Trigger代表”并发标记周期”触发的阈值。一旦当前JVM已使用内存/总堆内存超过这个阈值,就会触发并发标记。
虽然G1回收器的工作流程和”ParNew+CMS”回收器差的不是很多,但是每个核心步骤的具体实现却有很大的不同。接下来分别来看G1中的YGC、Concurrent Marking Cycle以及Mixed GC的一些核心实现细节。
3.1 Young GC核心流程
和”ParNew+CMS”一样,一旦Eden区满了之后,就会触发YGC。YGC只负载回收堆中新生代的所有Region,不回收老年代的Region。基本流程可以表示为如下几步:
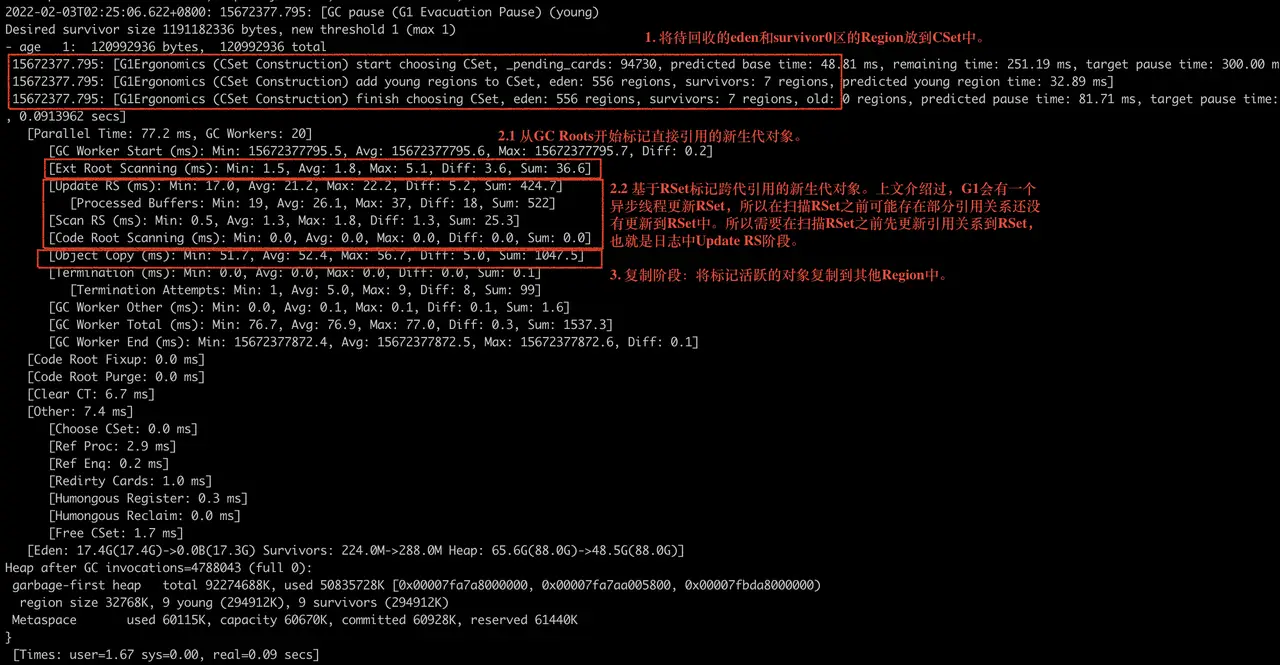
1. 将eden区和survivor区所有Region添加到CSet中准备回收。注:CSet是一个存放待回收Region的数据结构。
2. 标记阶段
- 从GC Roots开始标记直接引用的新生代对象。
- 基于RSet标记跨代引用的新生代对象。
3. 复制阶段:将标记活跃的对象复制到其他Region中。
为了更加清楚的明白上述步骤,下图是一次真实的YGC日志片段,可以对照着上述流程来看。

3.2 Concurrent Marking Cycle核心流程
根据上文介绍,一旦”JVM已使用内存/总内存”的比例超过设定阈值IHOP(InitiatingHeapOccupancyPercent)后,G1会执行一次Concurrent Marking Cycle,并在之后进行多轮Mixed GC。和CMS回收器基本一样,G1中一轮并发标记周期包含初始标记、并发标记、重新标记,再加上一个cleanup阶,这样就可以完成整堆所有Region的对象标记。下面是一段G1回收器中并发标记周期的完整日志:
- 初始标记(Initial Marking):初始化标记是伴随一次普通的YGC发生的,从GC Root开始标记直接可达的对象。
- 并发标记( Concurrent Marking):这个阶段标记线程和应用线程并发工作,遍历整堆所有可达对象并标记。这个阶段需要特别关注并发标记可能产生的”漏标”问题,G1使用Snapshot AT Begining(简称SATB)算法避免漏标问题发生,这和CMS完全不同。3.4小节深入介绍。
- 重新标记( Remark) :标记那些在并发标记阶段发生变化的对象,将被回收。
- 清理( Cleanup ):释放没有存活对象的Region。
3.3 Mixed GC核心流程
一轮并发标记之后紧接着是混合回收周期,包括多次Mixed GC,每次Mixed GC只回收部分Region。这里有三个问题:
1. 为什么这些Region需要分为多次回收?
主要原因是所有Region一起回收的话有可能会导致暂停时间比较长,尤其在内存较大的情况下。为了每次回收的暂停时间可控,就将一次大回收分成很多次小回收。
2. 每次回收Region集合的选择原则是什么?
在执行混合回收之前,G1会将所有Region按照每个Region中垃圾对象占比进行一次排序,垃圾对象占比越高,排名越靠前。排好序之后,每次Mixed GC按顺序选择部分Region进行回收,选择多少Region取决于这些Region的回收预估暂停时间不超过设置的最大暂停时间。这个回收算法称为Garbage First,也就是G1的意思。
3. 每次Mixed GC的过程是怎么样的?
具体的回收过程和上文中介绍的Young GC没有太大区别,可以参考上文介绍。
3.4 并发标记阶段对象”漏标”问题解法 – SATB算法
在介绍SATB算法之前,先简单介绍一下并发标记过程中可能出现的对象”漏标”问题。
对象漏标简介
什么是对象漏标?就是本应该被标记为活跃的对象因为某些原因最终没有被标记,被垃圾回收器认为是垃圾对象而回收掉,最终导致应用错误,很显然这种情况是不允许发生的。
并发标记阶段什么场景下会发生对象漏标?应用线程和标记线程并发执行,在下面两种场景下会出现漏标:
- 应用线程在并发标记过程中新生成的活跃对象因为某些原因没有被标记线程标记。
- 应用线程在并发标记过程中变更引用关系的时候在特定场景下会出现漏标,具体场景涉及标记算法”三色标记法”,详细可以阅读文章《【大内存服务GC实践】- 一文看懂”ParNew+CMS”垃圾回收器》。这里只简单进行描述:
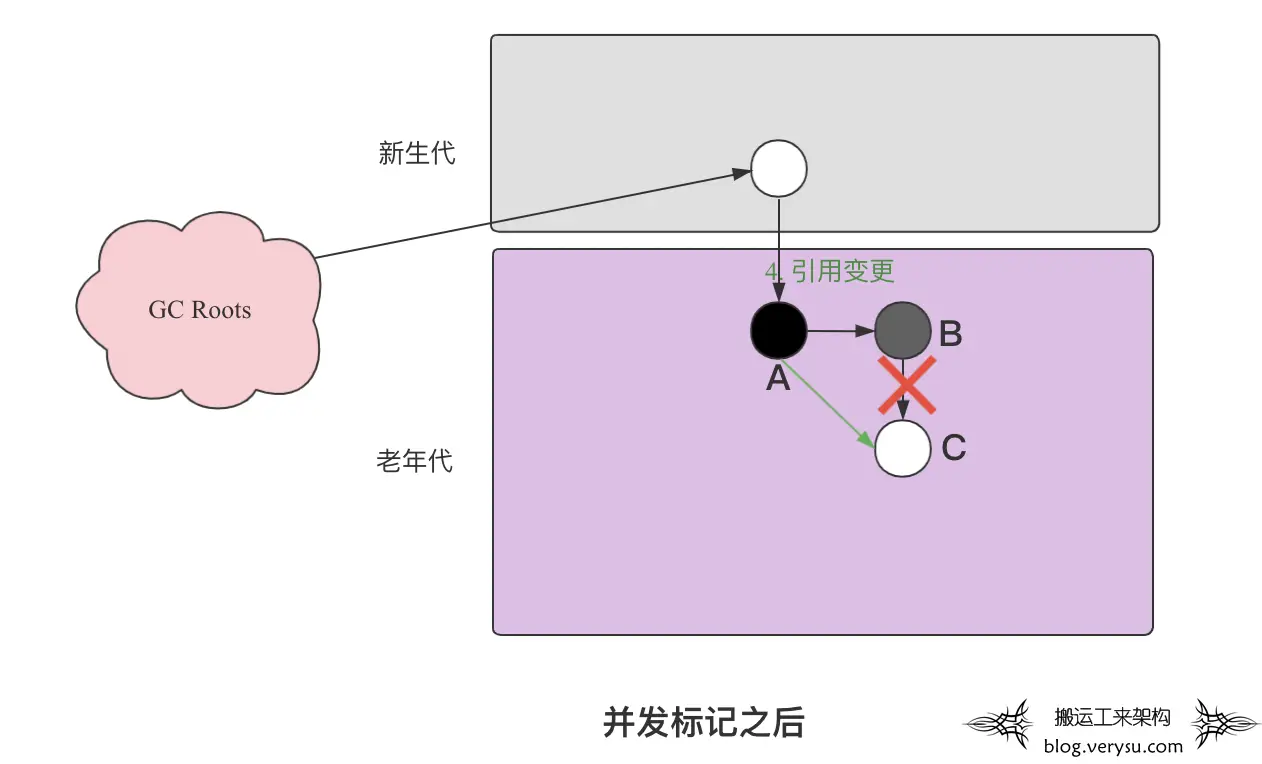
如上图所示,老年代中有三个对象A、B和C,在标记之前的引用关系是A引用B,B引用C。先分别介绍一下他们的标记情况:
- 对象A已经被标记为黑色,表示为A为活跃对象且所有它引用的对象也完成标记。
- 对象B被标记为灰色,表示B对象是活跃对象,但是它关联的对象还没有被完全标记完。
- 对象C是白色,表示还没有被标记。
在这种背景下,应用线程此时发生了一次引用关系变更,B引用C的关系被删除了且同时A引用了C,即如下所示代码:
objB.fieldC = null;
objA.filedC = C;
此时,标记线程就不再会标记对象C,因为对象A已经是黑色,表示所有它引用的对象都已经完成标记。然而实际上活跃的对象C就会被漏标最终被回收掉。
SATB算法思想简介
对象漏标介绍之后简单介绍一下SATB算法的基本思想,可以概括为如下三句话:
- 并发标记之前先给Region内存打个快照,标记线程基于这个快照独立进行标记。应用线程不会直接修改这个快照中的对象,也就是说应用线程不会干扰标记线程的工作。
- 应用线程新分配的对象都认为是活跃对象,实际在下一个并发标记周期进行标记。上文说过漏标发生的第一种场景是”应用线程在并发标记过程中新生成的活跃对象因为某些原因没有被标记线程标记”,那如果能够将标记阶段新分配的对象全都集合到一起,这些对象全部都标记为活跃对象(实际肯定会有部分垃圾对象,将垃圾对象标记为活跃对象不影响程序正确性)就可以解决这个问题。
- 并发标记过程中已存在对象的引用关系变更在Remark阶段单独进行处理。上文介绍了漏标发生的第二种场景,为了解决这个场景引入的漏标问题,可以将引用关系变更分解为旧的引用关系先删除,新的引用关系生成两个步骤,只要破坏任何一个步骤就可以防止漏标发生。因此有两种针对性解法:
- 在并发标记阶段如果有新引用关系生成,就记录下来,Remark阶段进行重标记,这个破坏了步骤二,即黑色对象重新引用了白色对象,就记录下来重新扫描黑色对象,将其引用的所有对象都标记成存活对象。这个就是CMS垃圾回收器使用的增量更新算法。
- 在并发标记阶段如果有引用关系被删除,就记录下来,Remark阶段对这些引用关系被删除的重标记,这个破坏了步骤一,即灰色对象断开了白色对象引用的时候,记录下来,后面重新把这个白色对象标记成存活对象。这个就是G1垃圾回收器使用的算法。
简单来说,SATB明确将并发标记这一个大工程分成了三个字模块,分别是对快照进行并发标记、对并发标记过程中新分配的对象全部标记为活跃、对并发标记过程中引用关系变更的对象单独进行处理。
SATB算法实现
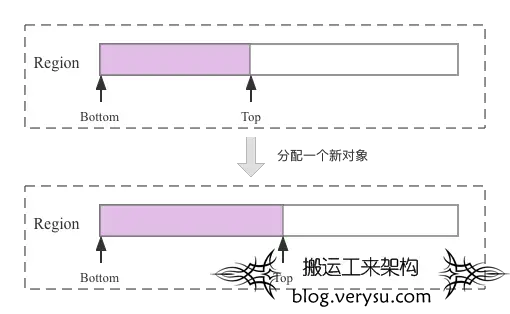
了解了SATB算法的核心思想之后,再来看看这个算法是如何实现的。G1回收器将堆内存分成一个一个Region,在Region中分配对象时,对象都是连续分配的。这里介绍两个指针:Bottom指针和Top指针,其中Bottom指针指向Region的初始位置,Top指针指向下一个对象分配的内存位置,如果有新的对象分配,就将Top指针向前移动。如下图所示:
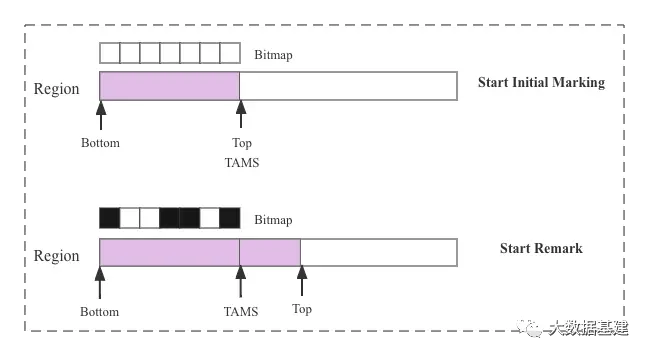
G1使用的SATB算法是基于内存快照的,那SATB算法具体怎么实现基于内存快照的标记呢?现在假设在标记之前Region如下:
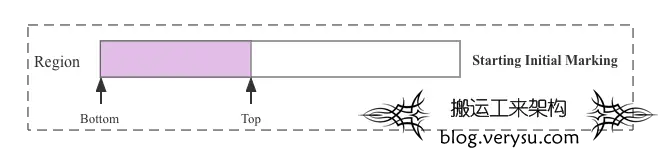
这个时候要进行一轮完整的并发标记周期,按照上面的说法是要先给这个Region打个快照,这个快照实际上就是[Bottom, Top)现在这块内存区域。但是在并发标记周期内,因为有引用线程在分配对象,所以Top指针肯定会往前移动,所以为了将标记开始前Top这个位置记录下来,需要定义另一个指针TAMS(全称Top-At-Mart-Start)指向标记前Top这个位置,从Top-At-Mark-Start这个字面含义就可以理解是标记开始时Top指针所在位置,这样快照所代表的内存区域就是[Bottom, TAMS)这块,并发标记过程中标记线程就基于这块内存对象进行标记,后面Top指针就可以随意往前移动了。所以按照正常的逻辑应该是这样:
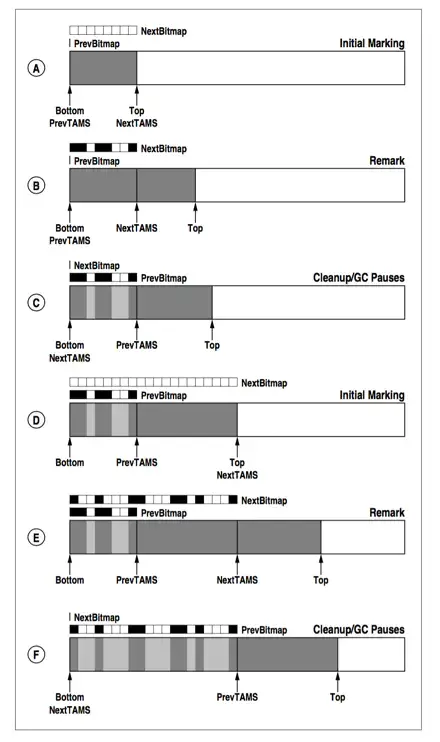
上图中Initial Marking刚开始的时候,Top指针和TAMS指针指向同一个内存位置,[Bottom, TAMS)这块内存区域有一个对应的bitmap,bitmap中每一位代表对应内存区域对象是否存活。经过并发标记之后,Remark开始的时候,Top指针因为应用线程有分配对象所以会向前移动,并发标记线程独立标记[Bottom, TAMS)这块内存区域对应的对象,标记后的结果使用bitmap表示(其中黑色方块表示对应对象被标记为活跃对象)。
在并发标记过程中新生成的对象都分配在[TAMS, Top) 这块内存区域,G1算法会将这部分新生成的对象都认为是存活对象,这轮标记不处理这部分新生成对象,留到下一轮标记处理。
现在继续来看SATB算法如何处理并发标记过程中引用关系变更问题。在并发标记阶段,引用变更发生后通过写屏障会将这些变更记录并保存在一个队列里(satb_mark_queue),在remark阶段会扫描这个队列,通过这种方式,旧的引用所指向的对象就会被标记上,其子孙也会被递归标记上,这样就不会漏标记任何对象,snapshot的完整性也就得到了保证。
实际上介绍到这里基本上已经将SATB算法实现介绍的比较清楚了。下图是完整的两轮并发标记示意图:
SATB算法 vs Incremental Update算法
G1的SATB算法在Remark阶段不需要暂停遍历整堆对象,所以避免了这个阶段可能的长耗时。但是CMS垃圾回收器中增量更新算法因为无法知道哪些对象是并发标记阶段新增的,所以在Remark阶段需要重新扫描GC Roots标记整堆对象,这就可能带来不可控的长耗时暂停。
至此,笔者基本将
G1GC的核心内容介绍完了。可以看到,G1相比CMS在很多地方都做了非常大的改动,整体思路还是比较清晰的。但是在具体实践中,因为G1的这种复杂性,导致想要用好G1,需要开发同学对期中各个参数的含义比较了解,并且要有一定的调优经验。尤其在一些大内存场景下,一旦参数调不好,很可能GC效果会非常差。因为笔者目前接触到的大数据系统都是大内存场景,所以在这些场景下用好G1,实际上还是需要不断地测试和调优。
本篇文章 (https://verysu.com)仅供学习!所有权归属原作者。侵删!文章来源:作者 http://hbasefly.com/2022/02/23/g1gc1/




文章评论