在第一个专题中已经比较系统地介绍了JVM三种常见的垃圾回收器算法和相关实践,这篇文章会在此基础上分场景将GC相关问题再梳理一番,一方面希望能够在发生GC问题的时候可以比较系统地指导问题分析的方向,另一方面也是希望通过这篇文章介绍一些关于使用GC日志分析GC问题的思路。如果在阅读的时候需要更加深入了解背后的机制,可以回头阅读公众号前期相关GC理论文章。
场景一: 没有发生GC但是STW了很长时间
这个案例是蛮久以前发生的一件事,当时有个同学反馈HBase服务总是发生暂停,导致读写请求卡顿。RegionServer日志里面有如下片段:
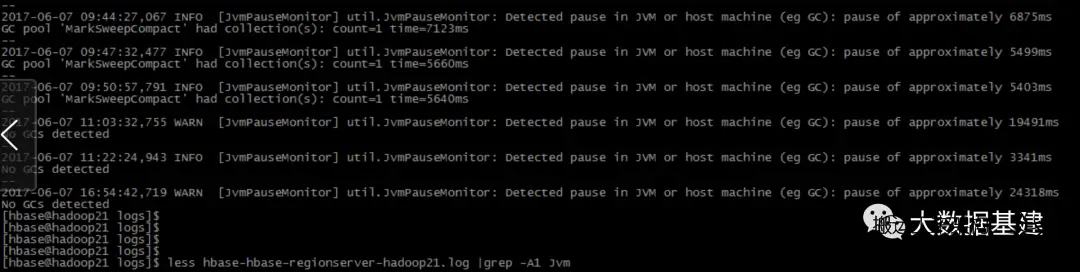
2017-05-26 18:42:10,607 WARN [JvmPauseMonitor] util.JvmPauseMonitor: Detected pause in JVM or host machine (eg GC): pause of approximately 48721ms No GCs detected 2017-05-26 19:12:10,790 WARN [JvmPauseMonitor] util.JvmPauseMonitor: Detected pause in JVM or host machine (eg GC): pause of approximately 49500ms No GCs detected
这段日志明确说明了JVM发生了暂停,但是"No GCs detected"说明暂停并不是GC引起的。当时同学给了一张jprofile的图:
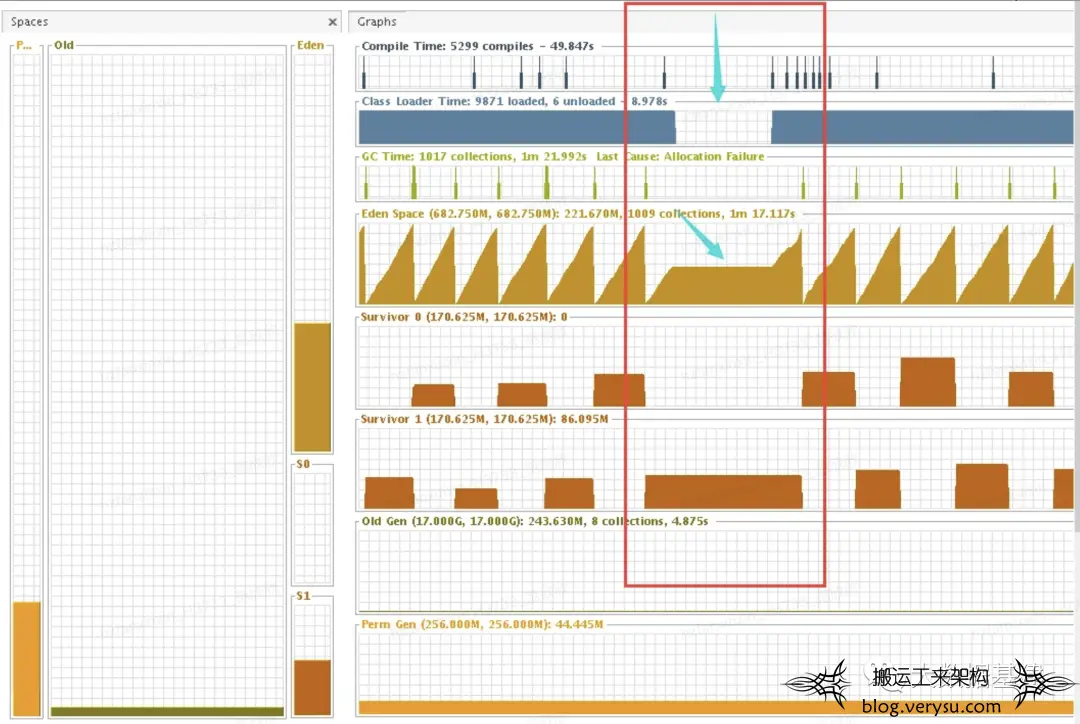
红框是JVM暂停的时间段,可以看到GC线程在那个时间段都被暂停了。经过进一步了解,怀疑这种暂停可能和JVM的safepoint机制有关,safepoint相关理论知识可以参考网上相关介绍。
如何确认暂停是否由safepoint机制导致?
如果怀疑暂停和safepoint相关,可以在JVM启动命令里面加上如下参数进行确认:
-XX:+PrintSafepointStatistics -XX: PrintSafepointStatisticsCount=1
加上这两个参数,就可以在发生暂停的时候捕获safepoint相关指标。当时加上参数后,差不多晚上7点左右,引起暂停的事件就被捕获了,如下图所示:

对上图中的各个指标简单做下解释 ,第一列为发生safepoint的时间戳,第二列vmop表示引起safepoint的操作类型,第三列为发生safepoint时的JVM内部线程概况,第四列为safepoint各阶段时间耗时。
结合服务日志可以确认JVM暂停的时间点正好对应第三行BulkRevokeBias类型的safepoint事件,暂停时间为9511ms。
safepoint引起的暂停如何处理?
关于safepoint引起暂停问题的解决方案大多是尝试取消偏向锁。偏向锁是JVM的一个配置,大概意思是说已经持有锁的线程在将来进入同步块的时候不需要再次获取对象锁,一般适合于锁竞争较少的场景,但在锁竞争比较激烈的场景下会增加系统负担(之前看到Cassendra项目有同学在社区提了一个jira要求关闭偏向锁,说可以提升5%的性能)。该功能是默认开启的,在JVM启动参数中加上-XX:+UseBiasedLocking关闭。
当时就抱着试试看的态度加上-XX:+UseBiasedLocking参数将偏向锁关闭,经过一段时间观察,发现暂停确实消失了:
场景二: 是GC但又不是GC
有时候我们发现JVM暂停了,去GC日志里面去看,发现real时间确实很久,同时也发现user时间很短,表现如下图所示:
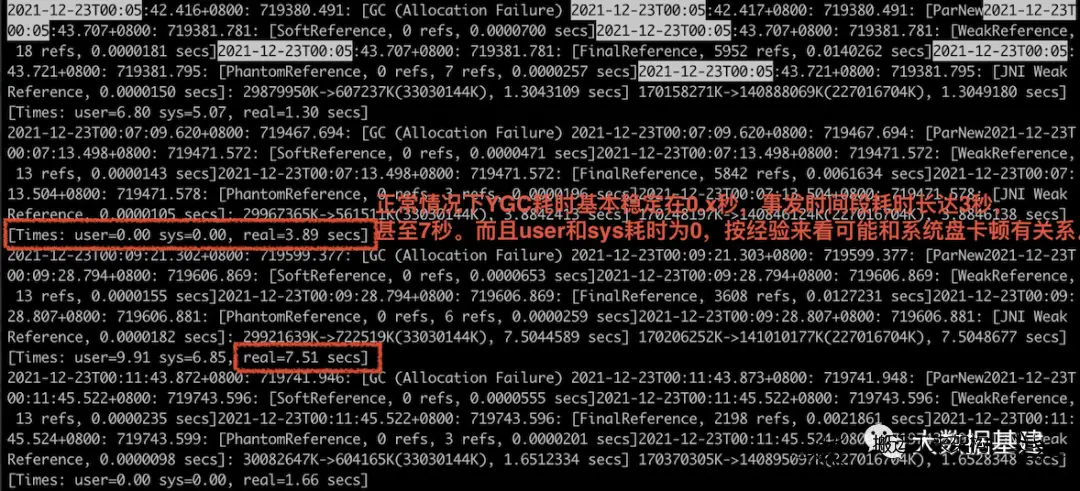
这里介绍一下GC日志中user、sys和real这三个时间元素:
1. user time指的是进行垃圾回收时,运行在用户态时花费的CPU时间,期间如果有线程阻塞或等待IO的时间,不会被计入到该时间中。
2. sys time是运行在内核态时花费的CPU时间。很多事情在用户态无法实现,比如申请内存、访问硬件等,这些操作只能在内核态才能完成。
3. real time表示从GC开始到结束,时钟走过的时间,期间任何时间消耗都要算上,比如sleep 2、等待IO完成等待等。
4. user time和sys time都是CPU时间,表示所有线程花费的总时间。而real time表示实际物理时间。这两者是有区别的。
5. 正常单核情况下,real time会比user time + sys time稍大一点。多核环境下,user time + sys time会比real time大,且一般是CPU线程数的倍数。
了解了上述基础之后,再来看问题是多核场景下real time比user time + sys time大很多,出现这类现象,大概率是因为暂停时间花费在了等待IO上,这个时候可以查看磁盘IO是否负载比较高,同时也可以观察系统是否发生了swap。
场景三: CMS GC STW场景
CMS GC过程中会发生STW暂停的场景主要包括新生代GC(YGC)、老年代GC的Initmark阶段和Remark阶段,再加上一个Full GC。 下面分别针对这几个子场景进行介绍:
3.1 YGC耗时长问题
大家知道YGC通常情况下是一个比较轻量级的动作,STW暂停时间比较短。但是在一些特殊情况下也有可能出现YGC频繁同时单次STW耗时长的情况。笔者结合排查经验发现一般在两种场景下会出现YGC耗时长的问题:
3.1.1 弱引用对象导致GC耗时长
在文章《【大内存服务GC实践】- "ParNew+CMS"实践案例 (一)- NameNode YGC诊断优化》中介绍了相关案例,这种问题具体的排查思路如下:
1. 在JVM中添加参数-XX:+PrintReferenceGC,然后在日志中查看各种Reference处理时间,确认是否是某种Reference的GC时间较长。比如如下日志所示FinalReference处理时间有异常:
2022-01-17T14:51:26.616+0800: 2061.131: [GC (Allocation Failure) 2022-01-17T14:51:26.617+0800: 2061.131: [ParNew 2022-01-17T14:51:27.115+0800: 2061.630: [SoftReference, 0 refs, 0.0000930 secs] 2022-01-17T14:51:27.115+0800: 2061.630: [WeakReference, 156 refs, 0.0000494 secs] 2022-01-17T14:51:27.115+0800: 2061.630: [FinalReference, 1348 refs, 10.2301307 secs] 2022-01-17T14:51:37.345+0800: 2071.860: [PhantomReference, 0 refs, 95 refs, 0.0000758 secs] 2022-01-17T14:51:37.346+0800: 2071.860: [JNI Weak Reference, 0.0000177 secs]: 52844281K->5134129K(53476800K), 10.7291830 secs] 90304049K->43584416K(172316096K), 10.7294849 secs] [Times: user=20.36 sys=0.17, real=10.73 secs]
2. 如果确认是某种Reference处理耗时长,这个时候需要确认具体代码哪里有问题,需要使用jmap将堆dump下来使用MAT工具进行离线分析。
3.1.2 存活对象多同时新生代设置过大
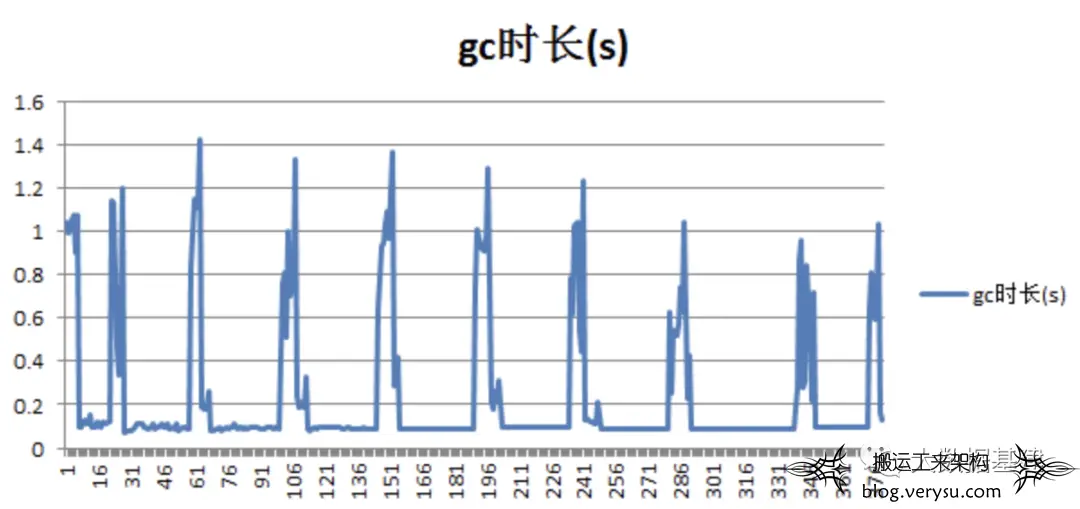
这是前些年调优HBase GC的一个案例,当时生产线上一个HBase集群毛刺比较大,平均RT延迟达到了35ms,发现对应的新生代GC暂停时间存在比较严重的周期性飙高现象,如下图所示:
GC毛刺对应的GC日志如下所示:
Desired survivor size 536870912 bytes, new threshold 15 (max 15) - age 1: 66920816 bytes, 66920816 total - age 2: 31848824 bytes, 98769640 total - age 3: 44876024 bytes, 143645664 total - age 4: 87252376 bytes, 230898040 total - age 5: 60272016 bytes, 291170056 total : 2747482K->508392K(3145728K), 1.3373170 secs] 41282080K->39351768K(74448896K), 1.3377370 secs] [Times: user=31.84 sys=0.06, real=1.33 secs]
结合上文中介绍的内容,可以知道这次YGC暂停了1.33秒,就是一个很长的GC耗时。
为什么会出现间歇性的严重GC现象?
回答这个问题之前需要对GC日志进行深入的分析,对GC日志细节分析将是这段内容的重点,也是笔者当时收获最大的地方。
这里需要介绍一下GC日志的一个知识点,建议生产线集群JVM添加一个参数:-XX:+PrintTenuringDistribution,添加该参数之后再观察GC日志,就会看到如下发生严重GC现场的相关日志:
...... //segment 1 2018-03-27T01:39:56.173+0800: 494.766: [GC2018-03-27T01:39:56.173+0800: 494.766: [ParNew Desired survivor size 268435456 bytes, new threshold 15 (max 15) - age 1: 16781920 bytes, 16781920 total - age 2: 20228208 bytes, 37010128 total - age 3: 4759904 bytes, 41770032 total ... - age 14: 27684368 bytes, 243160448 total - age 15: 13575512 bytes, 256735960 total : 1349201K->294951K(1572864K), 0.0758960 secs] 13669843K->12627095K(66584576K), 0.0763200 secs] [Times: user=2.04 sys=0.01, real=0.08 secs] //segment 2 2018-03-27T01:39:56.723+0800: 495.316: [GC2018-03-27T01:39:56.723+0800: 495.316: [ParNew Desired survivor size 268435456 bytes, new threshold 7 (max 15) - age 1: 188232096 bytes, 188232096 total - age 2: 14764616 bytes, 202996712 total - age 3: 24422312 bytes, 227419024 total ... - age 14: 20641680 bytes, 397494384 total - age 15: 23489976 bytes, 420984360 total : 1343527K->457857K(1572864K), 0.5613020 secs] 13675671K->12801211K(66584576K), 0.5617420 secs] [Times: user=15.59 sys=0.02, real=0.56 secs] //segment 3 2018-03-27T01:39:57.727+0800: 496.320: [GC2018-03-27T01:39:57.727+0800: 496.320: [ParNew Desired survivor size 268435456 bytes, new threshold 2 (max 15) - age 1: 118418040 bytes, 118418040 total - age 2: 176955776 bytes, 295373816 total - age 3: 18896624 bytes, 314270440 total - age 4: 20169880 bytes, 334440320 total - age 5: 4523304 bytes, 338963624 total - age 6: 4637048 bytes, 343600672 total - age 7: 16234008 bytes, 359834680 total : 1506433K->439961K(1572864K), 0.6325930 secs] 13849787K->12918739K(66584576K), 0.6330230 secs] [Times: user=17.08 sys=0.13, real=0.63 secs]
笔者将上述日志分为3个segment,其中segment 1对应的YGC耗时0.08s比较正常,segment 2和segment3对应的YGC耗时分别为0.56s和0.63s,暂停时间就比较久。接下来分析为什么segment2和segment3的YGC耗时久。
在分析之前有必要补充两点知识:
1. GC日志中age的概念:大家知道,YGC使用复制算法,每进行一次YGC,依然存活的对象的age就会加1,如果age超过15还没有被回收的对象就会被晋升到老年代。观察segment2中age为1的对象大小为188232096 bytes:
- age 1: 188232096 bytes, 188232096 total
2. YGC使用复制算法,整个暂停中耗时最长的阶段是存活对象复制。R大之前介绍过这块知识(参考):

有了这两点知识之后我们再来看,segment2中age1的对象大小为188MB左右,表示这一波进来的对象经过GC之后依然有188MB左右对象存活,要拷贝188M存活对象耗时就会很长。相比segment1(age1为1的对象大小为16MB)就更能体现了。
同样,对于segment3,age1的对象是118M左右,age2的对象是176M左右,age2的对象表示从上一次age1的对象集合经过一次YGC之后还存活的对象,所以就是188M对象经过一次GC之后还存活176M,可见一次GC确实没有回收多少垃圾,大多数对象都是存活对象。那这次GC只看age1和age2的话就要拷贝将近300M左右对象了,耗时肯定会很长。
分析到这里可以看出,这个案例YGC耗时长的原因是应用中存活对象比较多,如果新生代很大的话,存活对象每次在YGC过程中拷贝一次就比较耗时。所以这种场景下建议减少新生代大小,理论上新生代减少之后,GC频率会相对快一些,存活时间长的对象会更快晋升到老年代。
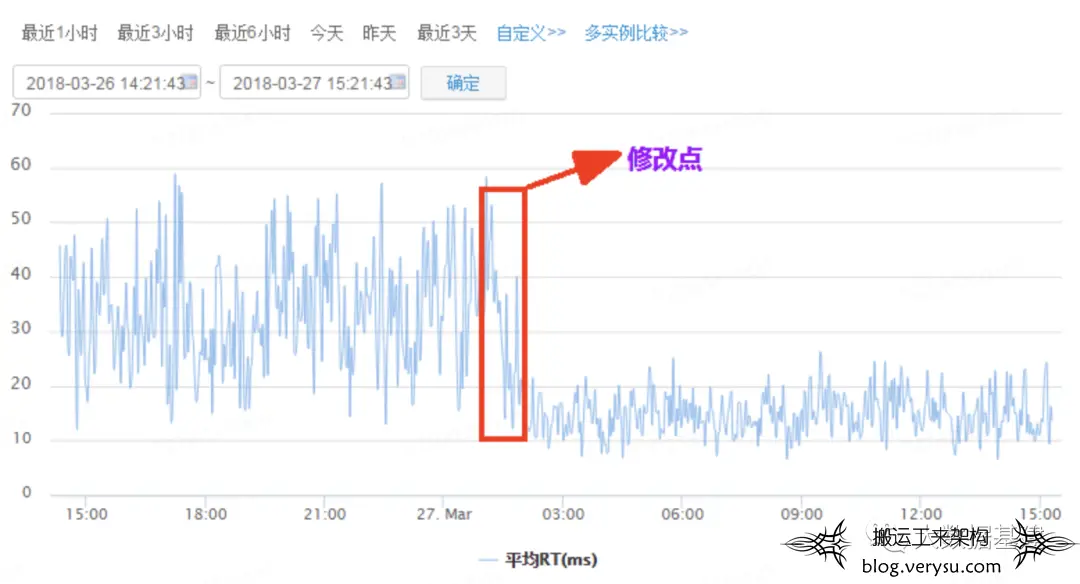
这个案例当时将新生代大小降低一倍之后,GC毛刺现象就明显减少了,对应HBase的读写请求RT延迟也降低了很多:
3.2 老年代GC频繁
老年代GC的触发条件是老年代使用内存占总堆大小超过阈值-XX:CMSInitiatingOccupancyFraction,所以如果老年代GC非常频繁的话,可以从两个方面进行分析:
1. -XX:CMSInitiatingOccupancyFraction阈值设置是否太小?在有些场景下为了防止FGC产生,运维会将该阈值调小。根据笔者经验,这个值设置在80%左右比较合理。
2. 通过观察GC日志,确认进入老生代对象的规律。如果老年代GC非常频繁,有可能是因为年轻代对象没有经过充分的GC,就将大量临时对象晋升到老年代,导致老年代内存使用很快达到阈值。
我们通过GC日志可以观察老年代对象的晋升规律,如下图所示:
2023-02-26T10:37:16.933+0800: 227753.150: [GC2023-02-26T10:37:16.933+0800: 227753.150: [ParNew Desired survivor size 268435456 bytes, new threshold 5 (max 15) - age 1: 57523184 bytes, 57523184 total - age 2: 80236520 bytes, 137759704 total - age 3: 73226496 bytes, 210986200 total - age 4: 50318392 bytes, 261304592 total - age 5: 63166384 bytes, 324470976 total - age 6: 240 bytes, 324471216 total : 1268903K->305311K(1572864K), 0.0840620 secs] 26598675K->25635082K(66584576K), 0.0844700 secs] [Times: user=1.82 sys=0.08, real=0.08 secs]
上述日志片段分三部分进行解释:
第一部分:基本信息区,主要有两点需要重点关注,其一是Desired survivor size 268435456 bytes,表示Survivor区大小为256M;其二是new threshold 5 (max 15),其中max表示对象晋级老生代的最大阈值为15,new threshold表示下一次YGC新的最大阈值为5(这里注意因为动态年龄判断,并不是每次GC都要求对象的最大年龄超过15才能晋升)。
第二部分:不同age对象分布区,第一列表示该Young区共分布有age在1~6的对象;第二列表示所在age含有的对象集所占内存大小,比如age为2的所有对象总大小为80236520 bytes;第三列表示小于对应age的所有对象占用内存的累加值,比如age2对应第二列137759704 total表示age为1和age为2的所有对象总大小;
第三部分:内存回收信息区,第一列表示Young区的内存回收情况,1268903K->305311K表示Young区回收前内存为1268903K,回收后变为305311K;第二列表示Jvm Heap的内存回收情况,26598675K->25635082K(66584576K) 表示当前Jvm总分配内存为66584576K,回收前对象占用内存为26598675K,回收后对象占用内存为25635082K;第三列表示回收时间,其中real表示本次gc所消耗的STW时间,即用户业务暂停时间。
了解到这个基础知识之后,如果我们发现新生代大量的对象在age较小的时候就晋升了(比如上述案例中age大于5的对象就全部晋升了,实际上很多场景下可能age大于2的对象就全部晋升了,这种情况下就要关注了),那说明有可能新生代设置太小,或者survivor区设置太小,很多对象没有经过充分淘汰就进入老生代,这种情况需要增大新生代或者survivor区内存。
3.3 老年代GC remark阶段耗时长
remark阶段GC日志如下图所示:
2021-11-17T18:33:09.820+0800: 179227.136: [Rescan (parallel) , 0.4236529 secs] 2021-11-17T18:33:10.244+0800: 179227.560: [weak refs processing, 93.3276296 secs] 2021-11-17T18:34:43.571+0800: 179320.888: [class unloading, 0.0895056 secs] 2021-11-17T18:34:43.661+0800: 179320.977: [scrub symbol table, 0.0107147 secs] 2021-11-17T18:34:43.671+0800: 179320.988: [scrub string table, 0.0025554 secs] [1 CMS-remark: 415575980K(566231040K)] 416281199K(618659840K), 94.1390159 secs] [Times: user=107.70 sys=10.29, real=94.14 secs]
1. 如果remark阶段过长是rescan耗时过长,可以开启-XX:+CMSScavengeBeforeRemark选项,强制remark之前开始一次minor gc,减少remark的暂停时间,但是在remark之后也将立即开始又一次minor gc。
2. 如果remark阶段过长是因为weak refs processing 处理时间太长,可以加上参数-XX:+PrintReferenceGC打印各种Reference的个数和处理时间。这种场景下可以采取的优化主要有两个:其一是开启并行remark: -XX:+CMSParallelRemarkEnabled。另一个是使用MAT分析堆内存中reference较多的根本原因。
3.4 Full GC频繁且耗时长
Full GC一般有两种模式:Concurrent Mode Failure和Promotion Mode Failure ,这两种模式表现出来都是长时间FGC,简单介绍一下这两种模式:
Concurrent Mode Failure
这种场景比较简单,假如现在系统正在执行CMS回收老生代空间,在回收的过程中新生代来了一批对象进来,不巧的是,老生代已经没有空间再容纳这些对象了。这种场景下,CMS回收器会停止继续工作,系统进入 "stop-the-world" 模式,并且回收算法会退化为单线程复制算法,重新分配整个堆内存的存活对象到S0中,释放所有其他空间。很显然,整个过程会非常漫长。生产线上碰到的FGC,一般都是这种模式,类似:
2019-09-04T17:51:42.762+0800: 1047152.983: [Full GC (Allocation Failure) 2019-09-04T17:51:42.762+0800: 1047152.983: [CMS2019-09-04T17:52:03.574+0800: 1047173.795: [CMS-concurrent-mark: 39.342/39.379 secs] [Times: user=353.41 sys=27.41, real=39.38 secs] (concurrent mode failure): 50331647K->50331647K(50331648K), 330.9755125 secs] 65431167K->61075996K(65431168K), [Metaspace: 126882K->126882K(133120K)], 330.9759323 secs] [Times: user=434.62 sys=63.52, real=330.98 secs]
这类问题一般两个解决思路:
1. 堆比较小,需要扩容堆大小
2. 堆扩容之后依然频繁FGC的话,需要使用jmap工具将堆内存dump下来进行离线分析,大概率是存在内存泄漏问题。
Promotion Mode Failure
假设此时设置XX:CMSInitiatingOccupancyFraction=80,但是在已使用内存还没有达到总内存80%的时候,已经没有空间容纳从新生代迁移的对象了。怎么会这样?罪魁祸首就是内存碎片,CMS算法会产生大量碎片,当碎片容量积累到一定大小之后就会造成上面的场景。这种场景下,CMS回收器一样会停止工作,进入漫长的 "stop-the-world" 模式。JVM也提供了参数 -XX: UseCMSCompactAtFullCollection来减少碎片的产生,这个参数表示会在每次CMS回收垃圾之后执行一次碎片整理,很显然,这个参数会对性能有比较大的影响,
通常这种情况下解决思路:将CMS换成G1GC。
场景四: G1GC STW场景
关于G1GC,之前也和一些遇到问题的小伙伴聊过,大多集中在FGC层面。在大家的认识里,G1GC不应该发生长时间的FGC,但实际上并不是如此。G1相关问题排查方法在公众号前期文章中已经介绍过,在此不再赘述。
本文仅供学习!所有权归属原作者。侵删!文章来源: 大数据基建 -子和 :http://mp.weixin.qq.com/s/AB8lw3o1vlDYO0ZDdN0BUA



文章评论