

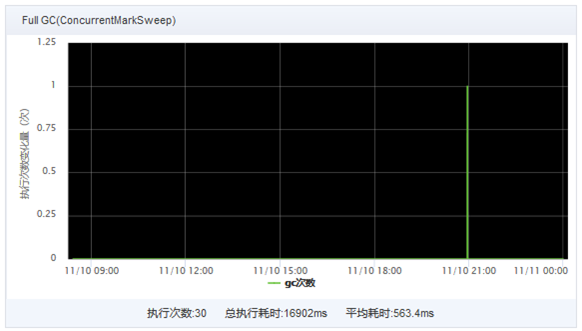
大促期间,某接口超时次数增多,FullGC达500ms以上。
-
容器:8C12G;
-
JVM配置:-XX:+UseConcMarkSweepGC -Xms6144m -Xmx6144m -Xmn2048m -XX:ParallelGCThreads=8 -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=70 -XX:+ParallelRefProcEnabled;
-
数据库类型:MySQL;
-
数据库连接池:DBCP;
1、GC耗时过长,说明内存中垃圾对象很多。
2、首先怀疑是否有内存泄漏,观察FullGC后堆内存回收情况,尚属正常,暂时排除内存泄漏原因。
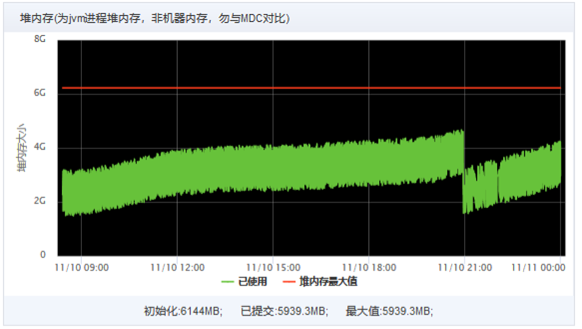
3、推断FullGC耗时过长是否因为老年代有大量死亡对象,遂导出FullGC前后堆内存dump,通过比对“保留大小”,发现FullGC后大量数据库相关对象被回收。
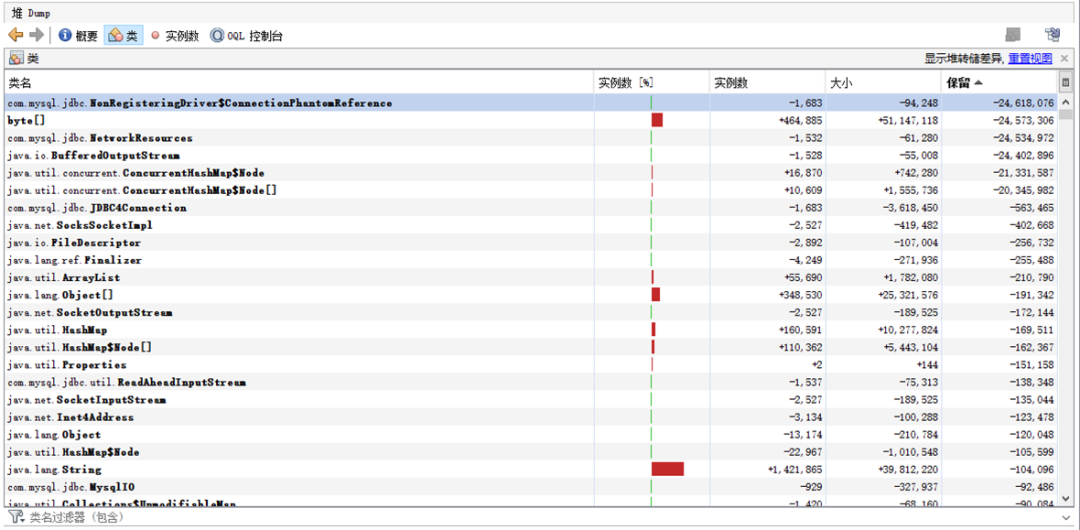
4、数据库连接正常应该不会频繁创建和断开,进入老年代后,正常不应该被回收,通过堆dump内容OQL分析每个数据库连接数量,发现很多库连接数都大于“maxActive”数量,可以肯定有很多失效连接。
5、初步判断直接原因是很多失效数据库连接进入老年代,导致FullGC耗时过长。
6、怀疑连接池验证周期过长,导致数据库因空闲过长关闭连接,将连接池参数“timeBetweenEvictionRunsMillis”由1分钟调整到10秒,问题依旧。
7、阅读DBCP源码,发现是通过org.apache.commons.pool.impl.GenericObjectPool.Evictor定时任务,按照timeBetweenEvictionRunsMillis配置的周期定时驱逐失效连接,驱逐条件:若连接空闲时间大于“minEvictableIdleTimeMillis”,则会驱逐连接,等待垃圾回收。若开启“testWhileIdle”则会执行“validationQuery”。进一步阅读代码,发现执行“validationQuery”后,连接空闲时间并不会重新计算,导致连接在业务低谷时很容易被淘汰,而数据库连接会关联大量对象,创建、回收成本昂贵,并且影响GC。
8、反向思考,为何只有在大促期间才发生问题?

可以看到平时由于业务量小,GC不频繁,过期连接没有达到进入老年代阈值,在年轻代被回收。而大促时业务量大,GC频繁,连接在进入老年代以后才过期,导致老年代FullGC时间过长。
9、至此,基本可以肯定问题原因是数据库连接池不具备“保活”能力,导致连接不断淘汰和新建,在业务高峰时段,连接进入老年代然后失效,造成FullGC耗时过长,最终导致接口超时次数增多。
方案1:改为G1回收器;
方案2:minEvictableIdleTimeMillis设置为0;
数据库连接池并不具备通常理解的“保活”能力,数据库连接在业务不活跃的应用中,会不断淘汰和重连,而连接会通过虚引用方式(com.mysql.jdbc.NonRegisteringDriver$ConnectionPhantomReference)携带大量对象,如果连接存活时间内YGC次数达到寿命阈值,则会进入老年代,老年代是使用“标记-清除”算法,回收成本更高,进而造成FullGC耗时过长。
1、Druid连接池同样存在不能“保活”问题,较新版本提供“KeepAlive”选项(未验证);
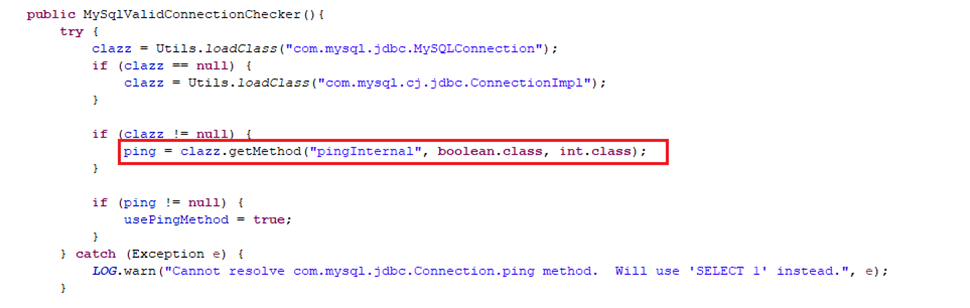
2、Druid连接池配置的“validationQuery”语句通常并不会被执行,MySqlValidConnectionChecker在检查连接有效性时,会判断驱动是否实现pingInternal方法,如果实现则会通过此方法验证有效性。MySQL的JDBC驱动实现了该方法,因此“validationQuery”配置的语句通常不会执行;
3、DBCP和Druid连接池默认都是FILO,如果业务不繁忙,会导致只有最前边的连接被使用-归还-使用,后边连接基本都在无谓的驱逐、重建连接;
4、虚引用对GC的影响:这些引用只有经过两次GC才能被回收掉,如果进入老年代,则必须经过两次FullGC才能释放内存。本例中由于不断有新的虚引用对象在老年代失效,导致FullGC后,内存水位仍然偏高,会加剧GC压力。新版本JVM已对此做了优化,一次GC可以回收掉;
5、类似的影响还有finalize方法;
6、CMS回收器默认MaxTenuringThreshold为6,而ParallelGC和G1均默认15;
来源: 京东零售技术



文章评论