CREATE TABLE `t1`(a int NOT NULL,b int DEFAULT NULL,c int DEFAULT NULL,d int DEFAULT NULL,e varchar(20) DEFAULT NULL, PRIMARYKEY(a) )ENGINE=InnoDB
插入一些数据:
insert into test.t1 values(4,3,1,1,'d');
insert into test.t1 values(1,1,1,1,'a');
insert into test.t1 values(8,8,8,8,'h');
insert into test.t1 values(2,2,2,2,'b');
insert into test.t1 values(5,2,3,5,'e');
insert into test.t1 values(3,3,2,2,'c');
insert into test.t1 values(7,4,5,5,'g');
insert into test.t1 values(6,6,4,4,'f');
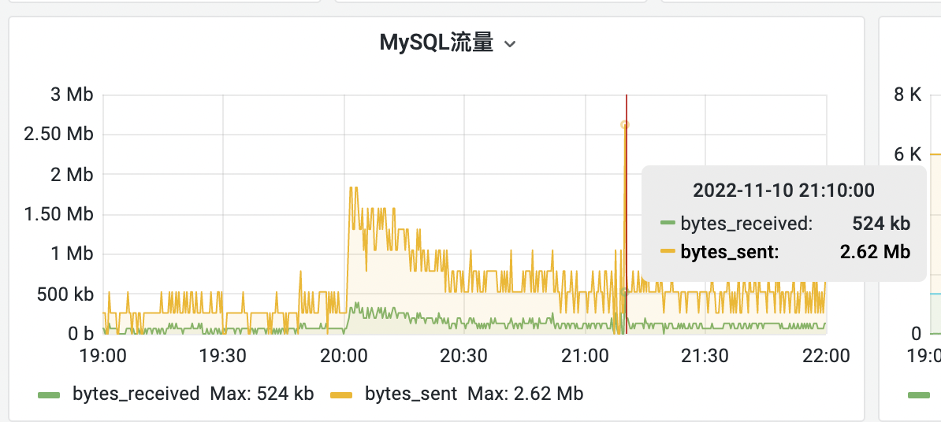
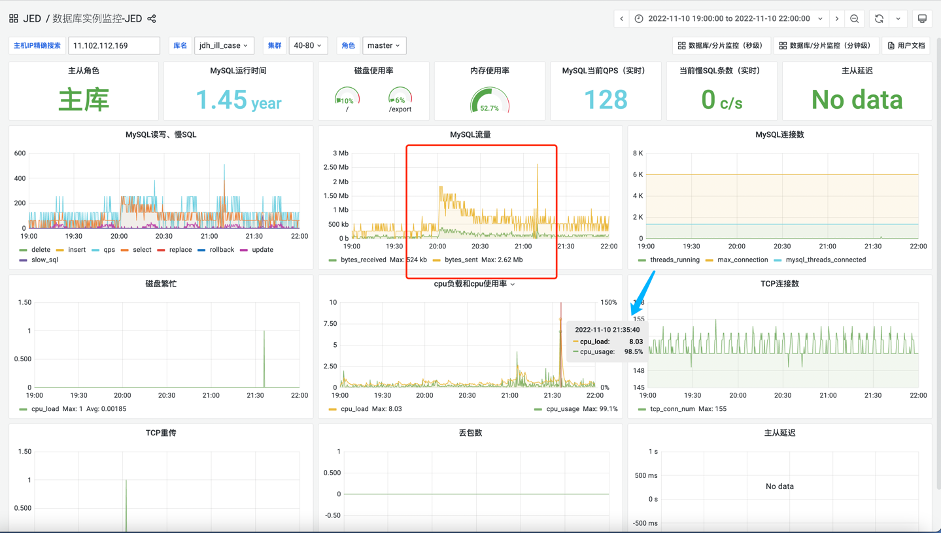
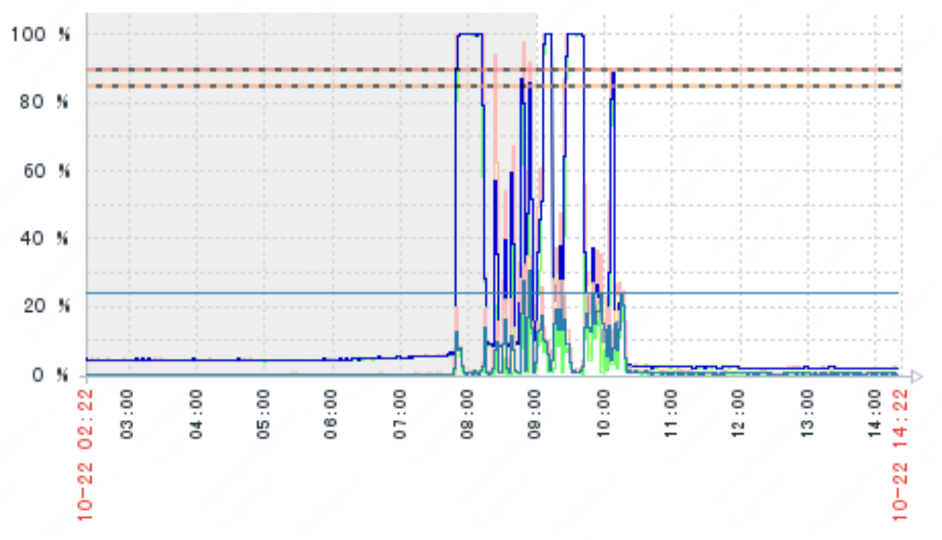
在建设互联网医院系统中,问诊单表当时量级23万左右,其中有一个business_id字符串字段,这个字段用来记录外部订单的ID,并且在该字段上也加了索引,但是'根据该ID查询详情'的SQL语句却总是时好时坏,性能不稳定,快则10ms,慢则2秒左右,SQL大体如下:select 字段1、字段2、字段3 from nethp_diag where business_Id = ? 因为business_id是记录第三方系统的订单ID,为了兼容不同的第三方系统,因而设计成了字符串类型,但如果传入的是一个数字类型是无法使用索引的,因为MySQL只能将字符串转数字,而不能将数字转字符串,由于外部的ID有的是数字有的是字符串,因而导致索引一会可以走到,一会走不到,最终导致了性能的不稳定。案例2: 在某次大促的当天,突然接到DBA运维的报警,说数据库突然流量激增,CPU也打到100%了,影响了部分线上功能和体验,遇到这种情况当时大部分人都比较紧张,下图为当时的数据库流量情况:
图9、图10 数据库流量情况相关SQL语句:
<!--统计医患下过去24小时内开的电子病历总数-->
<select id="getCountByDPAndTime" resultType="integer">
select count(1) from jdhe_medical_record
where status = 1 and is_test = #{isTest,jdbcType=INTEGER} and electric_medical_record_status in (2,3)
<if test="patientId != null"> and patient_id = #{patientId,jdbcType=BIGINT} </if>
<if test="doctorPin != null"> and doctor_pin = #{doctorPin,jdbcType=VARCHAR} </if>
and created >#{dateStart,jdbcType=TIMESTAMP};
</select>
图13 CPU异常报警当时的SQL语句:select rx_id, rx_create_time from nethp_rx_info where rx_status = 5 and status = 1 and rx_product_type = 0 and (parent_rx_id = 0 or parent_rx_id is null) and business_type != 7 and vender_id = 8888 order by rx_create_time asc limit 1;当时的索引情况:









文章评论