
一
相关概念
影子,我们都知道是什么意思,百度百科:物体挡住光线后,映在地面或其他物体上的形象。如果用在我们技术领域,比如数据方面,可以理解成是数据的一份拷贝,也就是“原封不动”的进行复制。那么把“影子”用在全链路压测是怎样的呢?
影子库:实际中使用的数据库的完整数据库数据拷贝,比如进行压测数据隔离的影子数据库,与生产数据库应当使用相同的配置。
影子表:是实际业务数据表的一份拷贝,比如进行压测数据隔离的影子数据表。
影子字段:来区分是否走影子逻辑,如判断该条 SQL 是否需要路由到影子数据库。
类似地还有:影子索引,影子topic,影子文件,影子key等。
目的:主要是为了环境隔离,将数据进行隔离:数据库(实例)隔离,数据表隔离等。
在全链路压测环境下,主要实现的是压测数据和其它环境(生产)数据的隔离。
二
实现案例:ShardingSphere
2.1、影子规则的配置
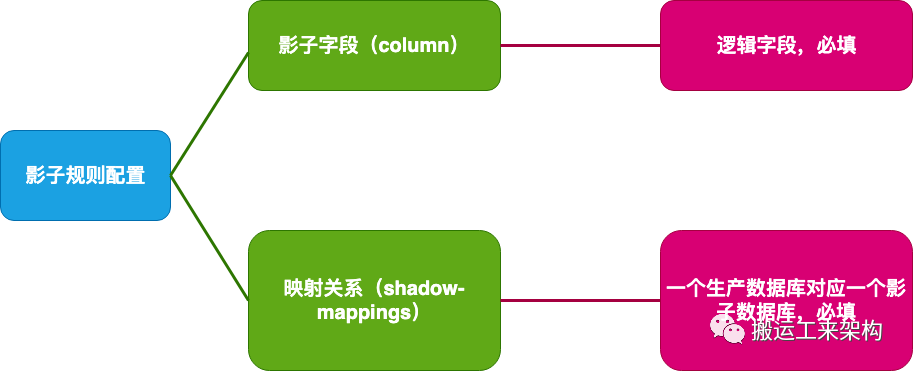
影子规则
配置文件如下:
#ds:原数据源 shadow_ds影子数据源
spring.shardingsphere.datasource.names=ds,shadow_ds
#影子字段shadow,及其映射关系
spring.shardingsphere.rules.shadow.column=shadow
spring.shardingsphere.rules.shadow.sourceDataSourceNames=ds
spring.shardingsphere.rules.shadow.shadowDataSourceNames=shadow_ds2.2、执行流程
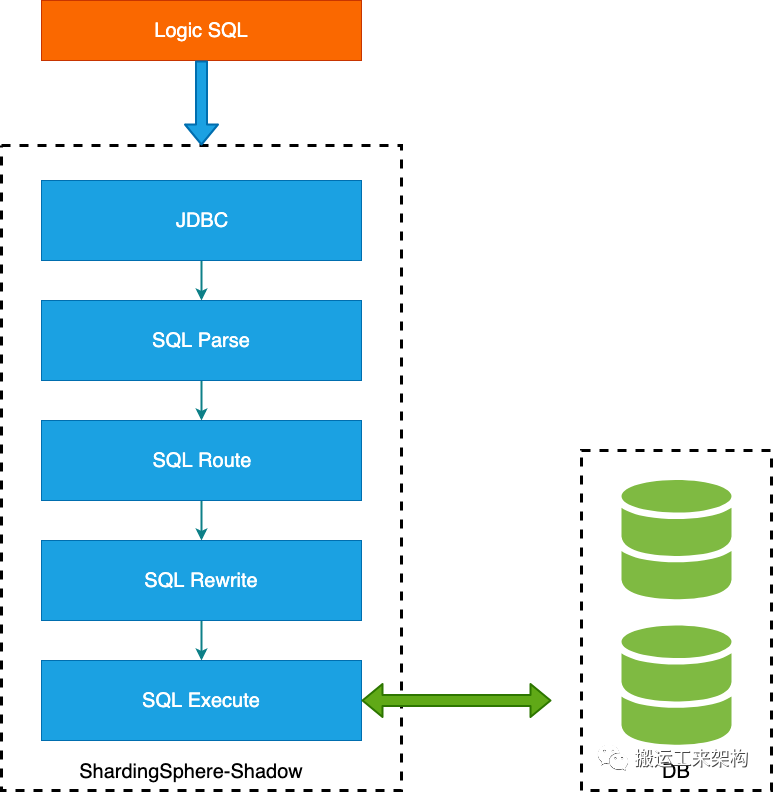
执行流程
逻辑SQL的执行需经过ShardingSphere相关模块处理的执行,首先需要将相关SQL进行解析,获得SQL的解析树和相关的字段参数等;接着根据配置的规则进行路由处理,比如路由到哪个数据源或数据表等;再接下来继续将逻辑SQL进行改写,将影子字段等进行移除等操作,最后向数据源执行真正的SQL。
2.3、处理流程
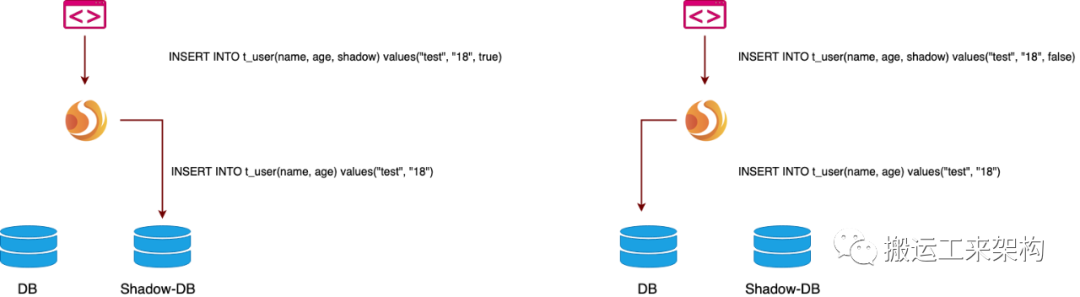
sql过程
以insert语句为例,在写入数据时,ShardingSphere 会对 SQL 进行解析,再根据配置文件中的规则,构造一条路由链。影子功能处于路由链中的最后一个执行单元,即,如果有其他需要路由的规则存在,如分片,ShardingSphere 会首先根据分片规则,路由到某一个数据库,再执行影子路由,将影子数据路由到与之对应的影子库。
接着对 SQL 进行改写,由于影子字段为逻辑字段,在数据库中实际不存在,所以在改写过程中会删除这个字段及其对应的参数。
DML 语句的处理过程同理,对于非 DML 语句,如创建数据表等,会在数据库与影子数据库分别执行。
2.4、源码剖析
ShardingSphere版本为5.0.0.-RC1,springboot的使用例子:shadow-spring-boot-example。
以insert过程为例,了解下ShardingSphere是如何处理的。
insert例子数据:
insert into t_shadow_user (pwd, shadow, user_name, user_id) values (pwd_jpa_1, false, test_jpa_1, 1) ;
insert into t_shadow_user (pwd, shadow, user_name, user_id) values (pwd_jpa_2, true, test_jpa_2, 2) ;
1)配置初始化ShadowRuleConfiguration
由于当前是使用springboot项目,所以在application.properties上配置了如上1的影子规则,解析完配置信息后初始化ShadowRuleConfiguration。
1public final class ShadowRuleConfiguration implements RuleConfiguration {
2 // 影子字段
3 private final String column;
4 // 原数据源
5 private final List<String> sourceDataSourceNames;
6 // 影子数据源
7 private final List<String> shadowDataSourceNames;
8}影子字段column不能为空,一般可以定义为shadow;原数据源和影子数据源都不能为空,需要一一对应,即个数要一致。
2)构建影子规则映射关系
1public final class ShadowRuleBuilder implements FeatureRuleBuilder, SchemaRuleBuilder<ShadowRule, ShadowRuleConfiguration> {
2 @Override
3 public ShadowRule build(final String schemaName, final Map<String, DataSource> dataSourceMap, final DatabaseType databaseType, final ShadowRuleConfiguration ruleConfig) {
4 return new ShadowRule(ruleConfig);
5 }
6 @Override
7 public int getOrder() {
8 // 60
9 return ShadowOrder.ORDER;
10 }
11 @Override
12 public Class<ShadowRuleConfiguration> getTypeClass() {
13 return ShadowRuleConfiguration.class;
14 }
15}
16
17public final class ShadowRule implements FeatureRule, SchemaRule {
18 private final Map<String, String> shadowMappings;
19 private final String column;
20 public ShadowRule(final ShadowRuleConfiguration shadowRuleConfig) {
21 column = shadowRuleConfig.getColumn();
22 shadowMappings = new HashMap<>(shadowRuleConfig.getShadowDataSourceNames().size());
23 for (int i = 0; i < shadowRuleConfig.getSourceDataSourceNames().size(); i++) {
24 // 原数据源与影子数据源进行关联
25 shadowMappings.put(shadowRuleConfig.getSourceDataSourceNames().get(i), shadowRuleConfig.getShadowDataSourceNames().get(i));
26 }
27 }
28}
使用ShadowRuleBuilder构建影子规则ShadowRule,将原数据源和影子数据源之间的映射关系存储在shadowMappings。
3)parse:SQL解析
SQL解析:ANTLR
ShardingSphere的SQL解析引擎经历了三个版本的演化:druid -> 自研 -> antlr。
1)第一代 SQL 解析器:druid
为了追求性能与快速实现,在 1.4.x 之前的版本使用 Druid 作为 SQL 解析器。经实际测试,它的性能远超其它解析器。
2)第二代 SQL 解析器:自研
1.5.x 版本开始,ShardingSphere 重新实现了一个简化版 SQL 解析引擎。因为ShardingSphere 并不需要像druid那样将 SQL 转为完整的AST,所以采用对 SQL 半理解的方式,仅提炼数据分片需要关注的上下文,在满足需要的前提下,SQL 解析的性能和兼容性得到了进一步的提高。
3)第三代 SQL 解析器:ANTLR
从 3.0.x 版本开始,尝试使用 ANTLR 作为 SQL 解析引擎的生成器,并采用 Visit 的方式从 AST 中获取 SQL Statement。从 5.0.x 版本开始,解析引擎的架构已完成重构调整, 同时通过将第一次解析的得到的 AST 放入缓存,方便下次直接获取相同 SQL的解析结果,来提高解析效率。因此我们建议用户采用 PreparedStatement 这种 SQL 预编译的方式来提升性能。
以上关于SQL解析器内容来自ShardingSphere官网,当前最新版本已经基于ANTLR,此处不进行深入了解,有兴趣的读者请自行查阅。
4)内核处理器KernelProcessor,编排SQL的核心处理流程:路由、改写。
1public final class KernelProcessor {
2 // 生成执行上下文
3 public ExecutionContext generateExecutionContext(final LogicSQL logicSQL, final ShardingSphereMetaData metaData, final ConfigurationProperties props) {
4 RouteContext routeContext = route(logicSQL, metaData, props);
5 SQLRewriteResult rewriteResult = rewrite(logicSQL, metaData, props, routeContext);
6 ExecutionContext result = createExecutionContext(logicSQL, metaData, routeContext, rewriteResult);
7 logSQL(logicSQL, props, result);
8 return result;
9 }
10 // SQL路由处理
11 private RouteContext route(final LogicSQL logicSQL, final ShardingSphereMetaData metaData, final ConfigurationProperties props) {
12 return new SQLRouteEngine(metaData.getRuleMetaData().getRules(), props).route(logicSQL, metaData);
13 }
14 // SQL改写处理
15 private SQLRewriteResult rewrite(final LogicSQL logicSQL, final ShardingSphereMetaData metaData, final ConfigurationProperties props, final RouteContext routeContext) {
16 return new SQLRewriteEntry(
17 metaData.getSchema(), props, metaData.getRuleMetaData().getRules()).rewrite(logicSQL.getSql(), logicSQL.getParameters(), logicSQL.getSqlStatementContext(), routeContext);
18 }
19 // 创建执行上下文
20 private ExecutionContext createExecutionContext(final LogicSQL logicSQL, final ShardingSphereMetaData metaData, final RouteContext routeContext, final SQLRewriteResult rewriteResult) {
21 return new ExecutionContext(logicSQL.getSqlStatementContext(), ExecutionContextBuilder.build(metaData, rewriteResult, logicSQL.getSqlStatementContext()), routeContext);
22 }
23 // 打印日志:开关
24 private void logSQL(final LogicSQL logicSQL, final ConfigurationProperties props, final ExecutionContext executionContext) {
25 if (props.<Boolean>getValue(ConfigurationPropertyKey.SQL_SHOW)) {
26 SQLLogger.logSQL(logicSQL, props.<Boolean>getValue(ConfigurationPropertyKey.SQL_SIMPLE), executionContext);
27 }
28 }
29}
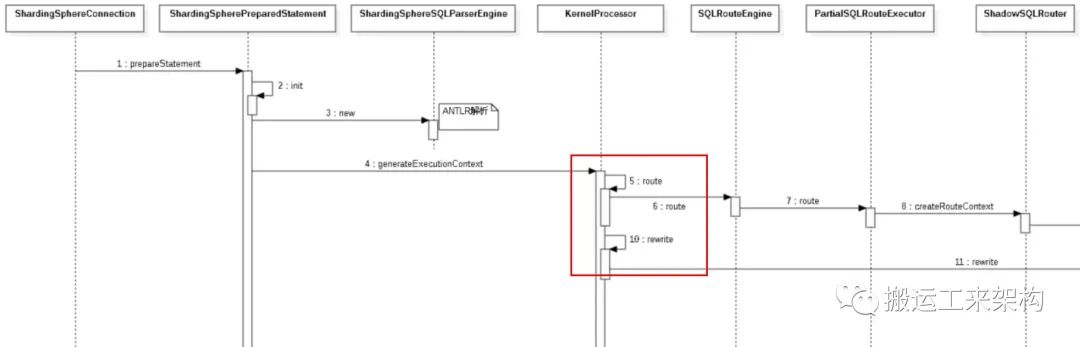
编排SQL核心处理器
由KernelProcessor得知,优先进行SQL路由处理,即使用SQL路由引擎进行SQL的路由处理。
回复公众号【资料】获得干货资料集锦:技术ppt、IT大会资料、架构、分布式资料等。
5)route:SQL路由引擎
1// SQL路由引擎
2public final class SQLRouteEngine {
3 public RouteContext route(final LogicSQL logicSQL, final ShardingSphereMetaData metaData) {
4 SQLRouteExecutor executor = isNeedAllSchemas(logicSQL.getSqlStatementContext().getSqlStatement()) ? new AllSQLRouteExecutor() : new PartialSQLRouteExecutor(rules, props);
5 return executor.route(logicSQL, metaData);
6 }
7}如果是show tables等DDL则SQL路由执行器为AllSQLRouteExecutor,否则(DML)是PartialSQLRouteExecutor。也就是说我们这里关注的是具体的SQL执行情况,insert属于DML,则需要关注PartialSQLRouteExecutor。
1public final class PartialSQLRouteExecutor implements SQLRouteExecutor {
2 public PartialSQLRouteExecutor(final Collection<ShardingSphereRule> rules, final ConfigurationProperties props) {
3 this.props = props;
4 // SPI
5 routers = OrderedSPIRegistry.getRegisteredServices(rules, SQLRouter.class);
6 }
7
8 @Override
9 public RouteContext route(final LogicSQL logicSQL, final ShardingSphereMetaData metaData) {
10 RouteContext result = new RouteContext();
11 for (Entry<ShardingSphereRule, SQLRouter> entry : routers.entrySet()) {
12 if (result.getRouteUnits().isEmpty()) {
13 // 创建路由上下文
14 result = entry.getValue().createRouteContext(logicSQL, metaData, entry.getKey(), props);
15 } else {
16 // 已有路由单元,则装饰路由上下文
17 entry.getValue().decorateRouteContext(result, logicSQL, metaData, entry.getKey(), props);
18 }
19 }
20 // 单数据源处理
21 if (result.getRouteUnits().isEmpty() && 1 == metaData.getResource().getDataSources().size()) {
22 String singleDataSourceName = metaData.getResource().getDataSources().keySet().iterator().next();
23 result.getRouteUnits().add(new RouteUnit(new RouteMapper(singleDataSourceName, singleDataSourceName), Collections.emptyList()));
24 }
25 return result;
26 }
27}
使用SPI机制,根据Rule获取SQLRouter具体的实现,SQL路由实现已有:ShardingSQLRouter、ReadwriteSplittingSQLRouter、DatabaseDiscoverySQLRouter、ShadowSQLRouter。当前Rule为ShadowRule,显然我们知道对应的SQL影子路由实现为:ShadowSQLRouter。ShardingSQLRouter(分片路由)的order为0,ReadwriteSplittingSQLRouter(读写分离路由)的order为10,DatabaseDiscoverySQLRouter(数据库发现路由)的order为20,ShadowSQLRouter的order为60,由此可知,影子路由的执行顺序是在执行分片规则之后,路由到某一个数据库,再执行影子路由,将影子数据路由到与之对应的影子库。
1public final class ShadowSQLRouter implements SQLRouter<ShadowRule> {
2 @Override
3 public RouteContext createRouteContext(final LogicSQL logicSQL, final ShardingSphereMetaData metaData, final ShadowRule rule, final ConfigurationProperties props) {
4 RouteContext result = new RouteContext();
5 // 逻辑SQL不是DML语句(如DDL),则添加对应的路由单元。我们当前是insert语句,所以不走这里的逻辑
6 if (!(logicSQL.getSqlStatementContext().getSqlStatement() instanceof DMLStatement)) {
7 rule.getShadowMappings().forEach((key, value) -> {
8 result.getRouteUnits().add(new RouteUnit(new RouteMapper(key, key), Collections.emptyList()));
9 result.getRouteUnits().add(new RouteUnit(new RouteMapper(value, value), Collections.emptyList()));
10 });
11 return result;
12 }
13 // SQL是DML语句,并且判断是否为影子SQL
14 // ShadowMappings: ds -> shadow_ds
15 if (isShadow(logicSQL.getSqlStatementContext(), logicSQL.getParameters(), rule)) {
16 // 添加路由单元:shadow_ds 影子数据源
17 rule.getShadowMappings().values().forEach(each -> result.getRouteUnits().add(new RouteUnit(new RouteMapper(each, each), Collections.emptyList())));
18 } else {
19 // 添加路由单元:ds 原数据源,即不走影子路由。路由单元映射中,逻辑数据源是ds,实际数据源也是ds
20 // RouteUnit(dataSourceMapper=RouteMapper(logicName=ds, actualName=ds), tableMappers=[])
21 rule.getShadowMappings().keySet().forEach(each -> result.getRouteUnits().add(new RouteUnit(new RouteMapper(each, each), Collections.emptyList())));
22 }
23 return result;
24 }
25 // 根据是否包含参数获取得对应影子数据源判断引擎来判断是否是影子路由
26 // 由于insert语句包含了参数,所以我们关注PreparedShadowDataSourceJudgeEngine
27 private boolean isShadow(final SQLStatementContext<?> sqlStatementContext, final List<Object> parameters, final ShadowRule rule) {
28 ShadowDataSourceJudgeEngine shadowDataSourceRouter = parameters.isEmpty()
29 ? new SimpleShadowDataSourceJudgeEngine(rule, sqlStatementContext) : new PreparedShadowDataSourceJudgeEngine(rule, sqlStatementContext, parameters);
30 return shadowDataSourceRouter.isShadow();
31 }
32}
接下来观察数据源是否是影子数据源,即当前关注预处理影子数据源判断引擎PreparedShadowDataSourceJudgeEngine:
1public final class PreparedShadowDataSourceJudgeEngine implements ShadowDataSourceJudgeEngine {
2 @Override
3 public boolean isShadow() {
4 if (sqlStatementContext instanceof InsertStatementContext) {
5 Collection<ColumnSegment> columnSegments = (((InsertStatementContext) sqlStatementContext).getSqlStatement()).getColumns();
6 int count = 0;
7 for (ColumnSegment each : columnSegments) {
8 // 根据rule判断当前字段是否走影子逻辑,即当前字段给的值是否为true或1
9 // insert t(id,name,shadow) values(1,'n1',false); 不走影子数据源
10 // insert t(id,name,shadow) values(2,'n2',true); 走影子数据源
11 if (each.getIdentifier().getValue().equals(shadowRule.getColumn())) {
12 return ShadowValueJudgeUtil.isShadowValue(parameters.get(count));
13 }
14 count++;
15 }
16 return false;
17 }
18 ......
19 }
20}
由此可见,根据insert语句插入的shadow值是否为1或true来判断当前我们插入的数据保存在影子数据源。
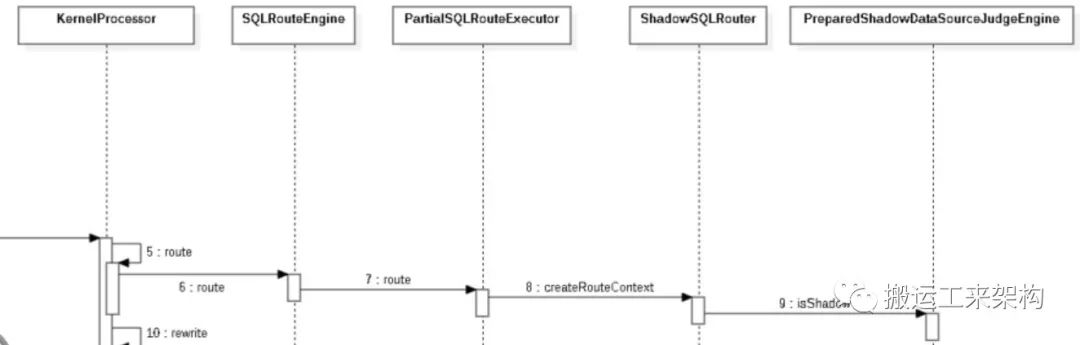
6)rewrite:SQL改写
KernelProcessor#rewrite:
2 // SQL改写处理
3 private SQLRewriteResult rewrite(final LogicSQL logicSQL, final ShardingSphereMetaData metaData, final ConfigurationProperties props, final RouteContext routeContext) {
4 return new SQLRewriteEntry(metaData.getSchema(), props, metaData.getRuleMetaData().getRules())
5 .rewrite(logicSQL.getSql(), logicSQL.getParameters(), logicSQL.getSqlStatementContext(), routeContext);
6 }
7
8/**
9 * SQL rewrite entry.
10 */
11public final class SQLRewriteEntry {
12 public SQLRewriteResult rewrite(final String sql, final List<Object> parameters, final SQLStatementContext<?> sqlStatementContext, final RouteContext routeContext) {
13 SQLRewriteContext sqlRewriteContext = createSQLRewriteContext(sql, parameters, sqlStatementContext, routeContext);
14 return routeContext.getRouteUnits().isEmpty()
15 ? new GenericSQLRewriteEngine().rewrite(sqlRewriteContext)
16 : new RouteSQLRewriteEngine().rewrite(sqlRewriteContext, routeContext);
17 }
18
19 private SQLRewriteContext createSQLRewriteContext(final String sql, final List<Object> parameters, final SQLStatementContext<?> sqlStatementContext, final RouteContext routeContext) {
20 // 创建一个初始SQL改写上下文
21 SQLRewriteContext result = new SQLRewriteContext(schema, sqlStatementContext, sql, parameters);
22 // 进行装饰器处理,其实就是根据Statement上下文,生成一系列的Token生成器
23 decorate(decorators, result, routeContext);
24 // 运行各Token生成器,解构出对应的Token
25 result.generateSQLTokens();
26 return result;
27 }
28
29 // 装饰器处理,当前也是通过SPI机制获取shadow对应的装饰类:ShadowSQLRewriteContextDecorator
30 private void decorate(final Map<ShardingSphereRule, SQLRewriteContextDecorator> decorators, final SQLRewriteContext sqlRewriteContext, final RouteContext routeContext) {
31 decorators.forEach((key, value) -> value.decorate(key, props, sqlRewriteContext, routeContext));
32 }
33}
SQLRewriteEntry是SQL改写的入口。创建SQL改写上下文SQLRewriteContext,根据路由上下文是否包含路由单元来创建对应的改写引擎:GenericSQLRewriteEngine和RouteSQLRewriteEngine。接着根据装饰器来生成相关的Token生成器,当前的装饰器,也是通过SPI机制获取shadow对应的装饰类:ShadowSQLRewriteContextDecorator。
1public final class ShadowSQLRewriteContextDecorator implements SQLRewriteContextDecorator<ShadowRule> {
2 @Override
3 public void decorate(final ShadowRule shadowRule, final ConfigurationProperties props, final SQLRewriteContext sqlRewriteContext, final RouteContext routeContext) {
4 // 获取参数改写器,然后依次对SQL改写上下文中的参数构造器parameterBuilder进行改写操作,影子功能下主要是影子参数
5 for (ParameterRewriter each : new ShadowParameterRewriterBuilder(shadowRule).getParameterRewriters(sqlRewriteContext.getSchema())) {
6 if (!sqlRewriteContext.getParameters().isEmpty() && each.isNeedRewrite(sqlRewriteContext.getSqlStatementContext())) {
7 each.rewrite(sqlRewriteContext.getParameterBuilder(), sqlRewriteContext.getSqlStatementContext(), sqlRewriteContext.getParameters());
8 }
9 }
10 // 添加影子功能下对应的Token生成器
11 sqlRewriteContext.addSQLTokenGenerators(new ShadowTokenGenerateBuilder(shadowRule).getSQLTokenGenerators());
12 }
13 ......
14}
15
16// 影子参数改写器
17public final class ShadowParameterRewriterBuilder implements ParameterRewriterBuilder {
18 private final ShadowRule shadowRule;
19 @Override
20 public Collection<ParameterRewriter> getParameterRewriters(final ShardingSphereSchema schema) {
21 Collection<ParameterRewriter> result = getParameterRewriters();
22 for (ParameterRewriter each : result) {
23 ((ShadowRuleAware) each).setShadowRule(shadowRule);
24 }
25 return result;
26 }
27
28 private Collection<ParameterRewriter> getParameterRewriters() {
29 Collection<ParameterRewriter> result = new LinkedList<>();
30 result.add(new ShadowPredicateParameterRewriter());// 影子谓词参数改写器
31 result.add(new ShadowInsertValueParameterRewriter());// 影子insert value参数改写器
32 return result;
33 }
34}
从上面可知,影子参数改写器:ShadowPredicateParameterRewriter与ShadowInsertValueParameterRewriter。
1public final class ShadowPredicateParameterRewriter extends ShadowParameterRewriter<SQLStatementContext> {
2 @Override
3 protected boolean isNeedRewriteForShadow(final SQLStatementContext sqlStatementContext) {
4 // 不管什么SQL,都会进行判断
5 return true;
6 }
7 @Override
8 public void rewrite(final ParameterBuilder parameterBuilder, final SQLStatementContext sqlStatementContext, final List<Object> parameters) {
9 // 使用影子条件引擎来替换影子参数(WHERE条件语句),当前insert语句不包含谓词条件,则不处理。
10 new ShadowConditionEngine(getShadowRule()).createShadowCondition(sqlStatementContext).ifPresent(
11 shadowCondition -> replaceShadowParameter(parameterBuilder, shadowCondition.getPositionIndexMap()));
12 }
13 // 替换影子参数
14 private void replaceShadowParameter(final ParameterBuilder parameterBuilder, final Map<Integer, Integer> positionIndexes) {
15 if (!positionIndexes.isEmpty()) {
16 for (Entry<Integer, Integer> entry : positionIndexes.entrySet()) {
17 ((StandardParameterBuilder) parameterBuilder).addRemovedParameters(entry.getValue());
18 }
19 }
20 }
21}
22
23public final class ShadowInsertValueParameterRewriter extends ShadowParameterRewriter<InsertStatementContext> {
24 @Override
25 protected boolean isNeedRewriteForShadow(final SQLStatementContext sqlStatementContext) {
26 // insert语句,并且包含影子列
27 return sqlStatementContext instanceof InsertStatementContext
28 && ((InsertStatementContext) sqlStatementContext).getInsertColumnNames().contains(getShadowRule().getColumn());
29 }
30 @Override
31 public void rewrite(final ParameterBuilder parameterBuilder, final InsertStatementContext insertStatementContext, final List<Object> parameters) {
32 String columnName = getShadowRule().getColumn(); // 影子列名
33 int columnIndex = getColumnIndex((GroupedParameterBuilder) parameterBuilder, insertStatementContext, columnName);
34 int count = 0;
35 for (List<Object> each : insertStatementContext.getGroupedParameters()) {
36 if (!each.isEmpty()) {
37 StandardParameterBuilder standardParameterBuilder = ((GroupedParameterBuilder) parameterBuilder).getParameterBuilders().get(count);
38 // 将影子下标保存在即将移除的参数里
39 standardParameterBuilder.addRemovedParameters(columnIndex);
40 }
41 count++;
42 }
43 }
44
45 private int getColumnIndex(final GroupedParameterBuilder parameterBuilder, final InsertStatementContext insertStatementContext, final String shadowColumnName) {
46 List<String> columnNames;
47 if (parameterBuilder.getDerivedColumnName().isPresent()) {
48 columnNames = new ArrayList<>(insertStatementContext.getColumnNames());
49 columnNames.remove(parameterBuilder.getDerivedColumnName().get());
50 } else {
51 columnNames = insertStatementContext.getColumnNames();
52 }
53 return columnNames.indexOf(shadowColumnName);
54 }
55}
接下来看下影子token生成器:ShadowInsertValuesTokenGenerator、RemoveShadowColumnTokenGenerator、ShadowPredicateColumnTokenGenerator。
1// 影子token生成构造器
2public final class ShadowTokenGenerateBuilder implements SQLTokenGeneratorBuilder {
3 private final ShadowRule shadowRule;
4 @Override
5 public Collection<SQLTokenGenerator> getSQLTokenGenerators() {
6 // 构造token生成器,并将其设置影子规则
7 Collection<SQLTokenGenerator> result = buildSQLTokenGenerators();
8 for (SQLTokenGenerator each : result) {
9 ((ShadowRuleAware) each).setShadowRule(shadowRule);
10 }
11 return result;
12 }
13
14 private Collection<SQLTokenGenerator> buildSQLTokenGenerators() {
15 Collection<SQLTokenGenerator> result = new LinkedList<>();
16 result.add(new ShadowInsertValuesTokenGenerator());// insert value Token生成器
17 result.add(new RemoveShadowColumnTokenGenerator());// 移除影子列Token生成器
18 result.add(new ShadowPredicateColumnTokenGenerator());// 影子谓词列表Token他生成器
19 return result;
20 }
21}
运行各Token生成器,解构出对应的Token:
1public final class SQLRewriteContext {
2 ...
3 // 生成tokens
4 public void generateSQLTokens() {
5 sqlTokens.addAll(sqlTokenGenerators.generateSQLTokens(sqlStatementContext, parameters, schema));
6 }
7}
8// token生成器
9public final class SQLTokenGenerators {
10 public List<SQLToken> generateSQLTokens(final SQLStatementContext sqlStatementContext, final List<Object> parameters, final ShardingSphereSchema schema) {
11 List<SQLToken> result = new LinkedList<>();
12 for (SQLTokenGenerator each : sqlTokenGenerators) {
13 setUpSQLTokenGenerator(each, parameters, schema, result);
14 if (!each.isGenerateSQLToken(sqlStatementContext)) {
15 // ShadowPredicateColumnTokenGenerator/RemoveTokenGenerator
16 continue;
17 }
18 if (each instanceof OptionalSQLTokenGenerator) {
19 // ShadowInsertValuesTokenGenerator -> InsertValuesToken: (?,?,?)
20 SQLToken sqlToken = ((OptionalSQLTokenGenerator) each).generateSQLToken(sqlStatementContext);
21 if (!result.contains(sqlToken)) {
22 result.add(sqlToken);
23 }
24 } else if (each instanceof CollectionSQLTokenGenerator) {
25 // RemoveShadowColumnTokenGenerator -> RemoveToken: ""
26 result.addAll(((CollectionSQLTokenGenerator) each).generateSQLTokens(sqlStatementContext));
27 }
28 }
29 return result;
30 }
31 .....
32}
默认创建RemoveTokenGenerator,那么当前总的token生成器集合有:RemoveTokenGenerator、ShadowInsertValuesTokenGenerator、RemoveShadowColumnTokenGenerator、ShadowPredicateColumnTokenGenerator。在当前例子上真正起作用的只有:RemoveTokenGenerator和ShadowInsertValuesTokenGenerator。
我们重点看下ShadowInsertValuesTokenGenerator:
1public final class ShadowInsertValuesTokenGenerator extends BaseShadowSQLTokenGenerator implements OptionalSQLTokenGenerator<InsertStatementContext>, PreviousSQLTokensAware {
2 @Override
3 protected boolean isGenerateSQLTokenForShadow(final SQLStatementContext sqlStatementContext) {
4 return sqlStatementContext instanceof InsertStatementContext && ((InsertStatementContext) sqlStatementContext).getInsertColumnNames().contains(getShadowRule().getColumn());
5 }
6 @Override
7 public InsertValuesToken generateSQLToken(final InsertStatementContext insertStatementContext) {
8 Optional<SQLToken> insertValuesToken = findPreviousSQLToken(InsertValuesToken.class);
9 if (insertValuesToken.isPresent()) {
10 processPreviousSQLToken(insertStatementContext, (InsertValuesToken) insertValuesToken.get());
11 return (InsertValuesToken) insertValuesToken.get();
12 }
13 return generateNewSQLToken(insertStatementContext);
14 }
15 // 生成新的SQL token (?, ?, ?, ?) -> (?, ?, ?)
16 private InsertValuesToken generateNewSQLToken(final InsertStatementContext insertStatementContext) {
17 Collection<InsertValuesSegment> insertValuesSegments = insertStatementContext.getSqlStatement().getValues();
18 InsertValuesToken result = new ShadowInsertValuesToken(getStartIndex(insertValuesSegments), getStopIndex(insertValuesSegments));
19 for (InsertValueContext each : insertStatementContext.getInsertValueContexts()) {
20 InsertValue insertValueToken = new InsertValue(each.getValueExpressions());
21 // insert语句降序列名
22 Iterator<String> descendingColumnNames = insertStatementContext.getDescendingColumnNames();
23 while (descendingColumnNames.hasNext()) {
24 String columnName = descendingColumnNames.next();
25 // 是影子列 则移除
26 if (getShadowRule().getColumn().equals(columnName)) {
27 removeValueToken(insertValueToken, insertStatementContext, columnName);
28 }
29 }
30 result.getInsertValues().add(insertValueToken);
31 }
32 return result;
33 }
34 private void removeValueToken(final InsertValue insertValueToken, final InsertStatementContext insertStatementContext, final String columnName) {
35 int columnIndex = insertStatementContext.getColumnNames().indexOf(columnName);
36 insertValueToken.getValues().remove(columnIndex);
37 }
38 ......
39}
从上面知道,insert语句会将对应的影子列去掉,从而保证在插入数据时不将影子列值进行赋值。
接下来看改写引擎RouteSQLRewriteEngine:
1public final class RouteSQLRewriteEngine {
2 // 改为SQL与参数
3 public RouteSQLRewriteResult rewrite(final SQLRewriteContext sqlRewriteContext, final RouteContext routeContext) {
4 Map<RouteUnit, SQLRewriteUnit> result = new LinkedHashMap<>(routeContext.getRouteUnits().size(), 1);
5 for (RouteUnit each : routeContext.getRouteUnits()) {
6 // 通过RouteSQLBuilder构造生成最终SQL
7 result.put(each, new SQLRewriteUnit(new RouteSQLBuilder(sqlRewriteContext, each).toSQL(), getParameters(sqlRewriteContext.getParameterBuilder(), routeContext, each)));
8 }
9 return new RouteSQLRewriteResult(result);
10 }
11 .....
12}
13
14RouteSQLBuilder->AbstractSQLBuilder
15public abstract class AbstractSQLBuilder implements SQLBuilder {
16 private final SQLRewriteContext context;
17 @Override
18 public final String toSQL() {
19 if (context.getSqlTokens().isEmpty()) {
20 return context.getSql();
21 }
22 // 按照Token的起始位置排序
23 Collections.sort(context.getSqlTokens());
24 StringBuilder result = new StringBuilder();
25 // context.getSql():insert into t_shadow_user (pwd, shadow, user_name, user_id) values (?, ?, ?, ?)
26 result.append(context.getSql(), 0, context.getSqlTokens().get(0).getStartIndex());
27 // result:insert into t_shadow_user (pwd
28 for (SQLToken each : context.getSqlTokens()) {
29 // 添加Token对应的SQL片段
30 result.append(each instanceof ComposableSQLToken ? getComposableSQLTokenText((ComposableSQLToken) each) : getSQLTokenText(each));
31 // 添加Token之间的连接字符 result:insert into t_shadow_user (pwd, user_name, user_id) values
32 result.append(getConjunctionText(each));
33 }
34 // result:insert into t_shadow_user (pwd, user_name, user_id) values (?, ?, ?)*
35 return result.toString();
36 }
37 ......
38}
从上面的改写引擎得知,最终将insert语句从
insert into t_shadow_user (pwd, shadow, user_name, user_id)
values (?, ?, ?, ?)
改写为:
insert into t_shadow_user (pwd, user_name, user_id) values (?, ?, ?)
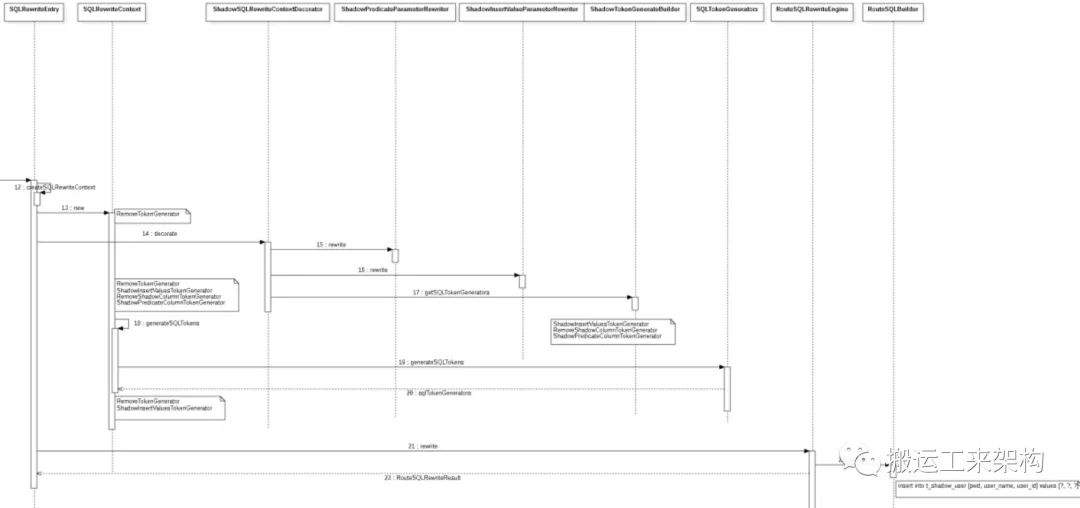
SQL改写:rewrite
最后,看下insert语句的执行日志:
Insert SQL: insert into t_shadow_user (pwd, shadow, user_name, user_id) values (pwd_jpa_1, false, test_jpa_1, 1)
Logic SQL: insert into t_shadow_user (pwd, shadow, user_name, user_id) values (?, ?, ?, ?)
Actual SQL: ds ::: insert into t_shadow_user (pwd, user_name, user_id) values (?, ?, ?) ::: [pwd_jpa_1, test_jpa_1, 1]
Insert SQL: insert into t_shadow_user (pwd, shadow, user_name, user_id) values (pwd_jpa_2, true, test_jpa_2, 2)
Logic SQL: insert into t_shadow_user (pwd, shadow, user_name, user_id) values (?, ?, ?, ?)
Actual SQL: shadow_ds ::: insert into t_shadow_user (pwd, user_name, user_id) values (?, ?, ?) ::: [pwd_jpa_2, test_jpa_2, 2]
可以看出来,shadow=false,则数据源为ds;shadow=true,则数据源为影子数据源shaodow_ds,并且不会将shadow进行设值。
最后,就是将最终的SQL在对应的数据源进行执行,完毕。
2.5、总结
从上面的ShardingSphere源码剖析的过程来看,大概知道其实现压测影子库流程:
-> init-mapping 初始化配置及构建影子映射关系
-> parse 使用ANTLR解析SQL
-> 使用内核处理器KernelProcessor来编排核心功能:路由和改写
-> route 路由引擎处理
路由到具体的数据源:原数据源还是影子数据源。
-> rewrite 改写引擎处理
生成参数改写器和SQL token生成器,最后生成经过处理后去执行的真正SQL。
整体时序流程如下:
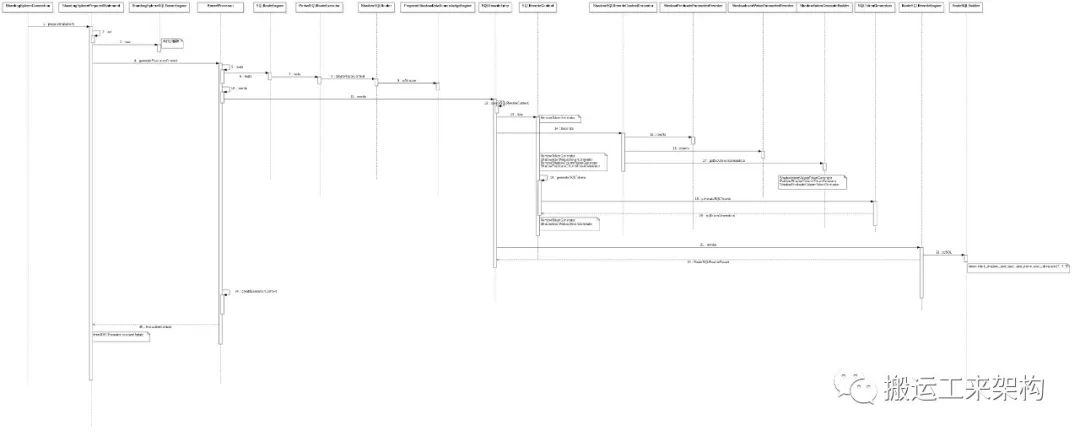
ShardingSphere-shadow
由于公众号图片压缩,出现不清晰,可 回复公众号【资料】上述时序流程图 获取。
参考:ShardingSphere 官网

4、Netty 5.0为啥被舍弃?原因竟然是...
5、中台之上——业务架构系列【汇总】

-关注搬运工来架构,与优秀的你一同进步-
如果喜欢这篇文章可以点在看哦↘
本文仅供学习!所有权归属原作者。侵删!文章来源: 搬运工来架构



文章评论