
导读
- 2009年由 Salvatore Sanfilippo(Redis之父)发布初始版本。
- 2013年5月之前,由VMare赞助。
- 2013年5月-2015年6月,由Pivotal赞助。
- 2015年6月起,由Redis Labs赞助。

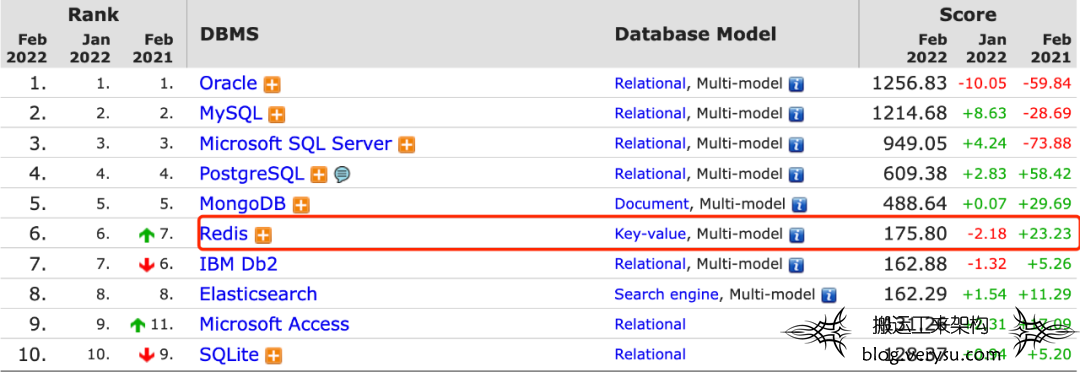
图2 Redis在db-engineer.com上的排名
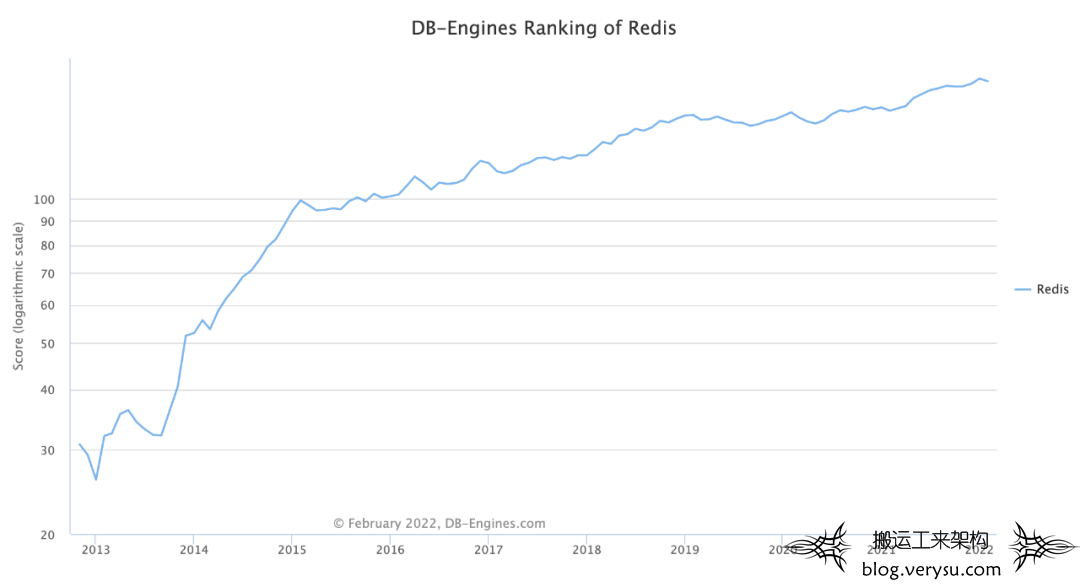
图3 Redis每年的受欢迎程度
Redis主要版本
- 2009年5月发布Redis初始版本;
- 2012年发布Redis 2.6.0;
- 2013年11月发布Redis 2.8.0;
- 2015年4月发布Redis 3.0.0,在该版本Redis引入集群;
- 2017年7月发布Redis 4.0.0,在该版本Redis引入了模块系统;
- 2018年10月发布Redis 5.0.0,在该版本引入了Streams结构;
- 2020年5月2日发布 6.0.1(稳定版),在该版本中引入多线程、RESP3协议、无盘复制副本;
- 2022年1月31日发布 7.0 RC1,在该版本中主要是对性能和内存进行优化,新的AOF模式。
Redis 有多快?
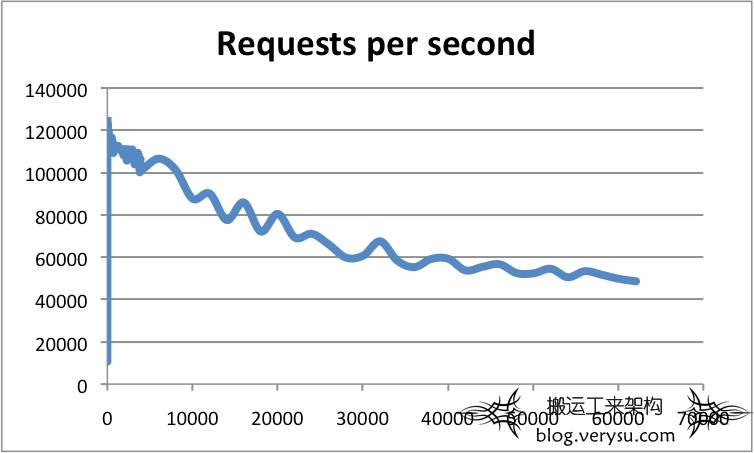
根据官方的文档,Redis 已经在超过 60000 个连接上进行了基准测试,并且在这些条件下仍然能够维持 50000 q/s。同样的请求量如果打到MySQL上,那很可能直接崩掉。
- With high-end configurations, the number of client connections is also an important factor. Being based on epoll/kqueue, the Redis event loop is quite scalable. Redis has already been benchmarked at more than 60000 connections, and was still able to sustain 50000 q/s in these conditions. As a rule of thumb, an instance with 30000 connections can only process half the throughput achievable with 100 connections. Here is an example showing the throughput of a Redis instance per number of connections;
Redis为什么可以这么快?
那是什么原因造就了Redis可以具有如此高的性能?主要分为以下几个方面:
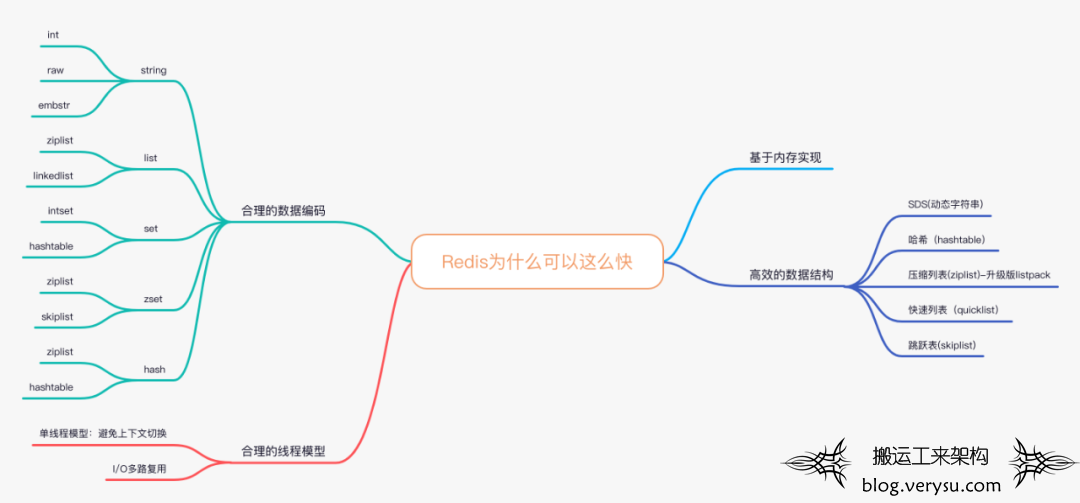
图5 Redis为什么这么快-思维导图
Mysql的数据存储持久化是存储到磁盘上的,读取数据是内存中如果没有的话,就会产生磁盘I/O,先把数据读取到内存中,再读取数据。而Redis则是直接把数据存储到内存中,减少了磁盘I/O造成的消耗。
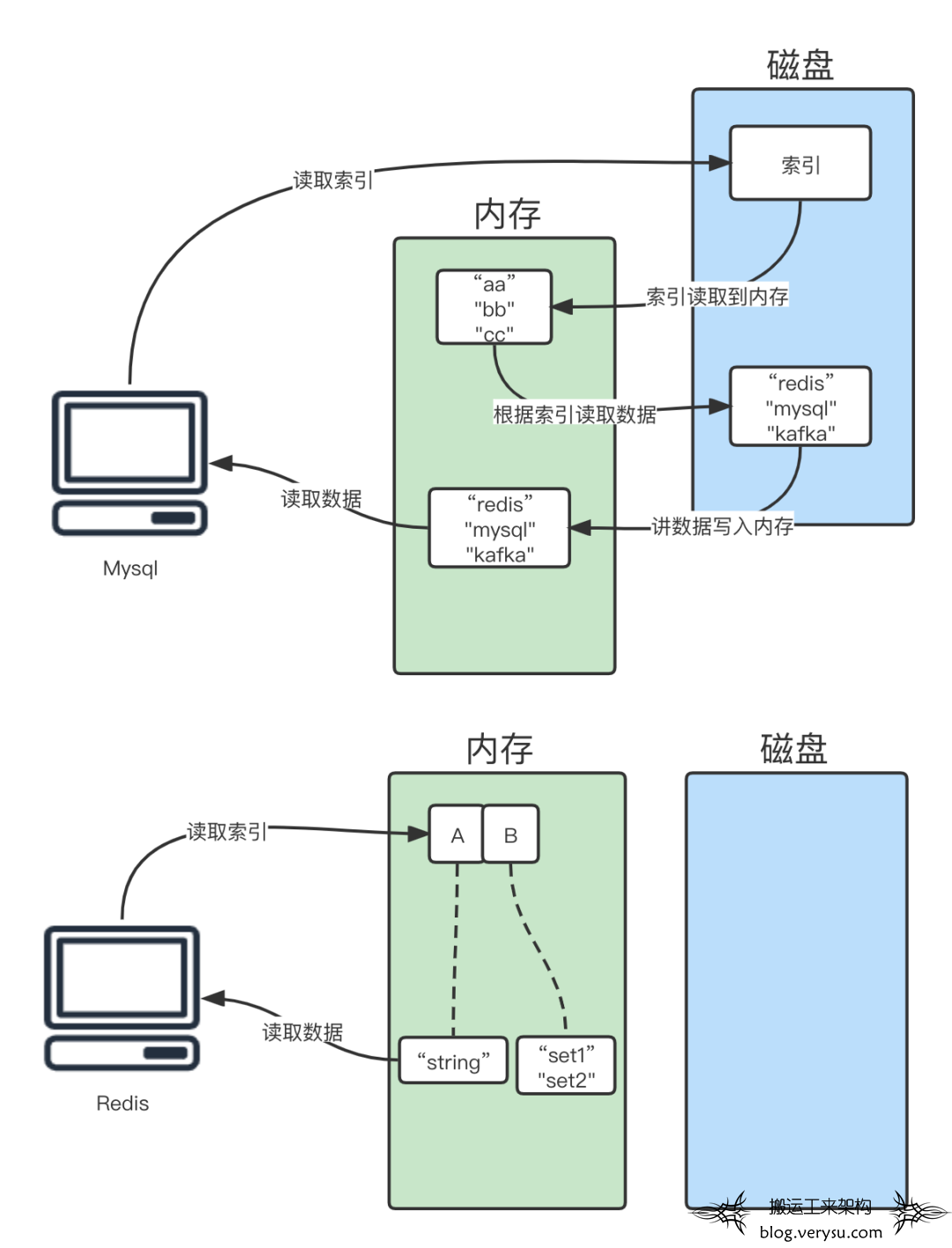
图6 Redis与Mysql存储方式区别
合理的数据结构,就是可以让应用/程序更快。Mysql索引为了提高效率,选择了B+树的数据结构。先看下Redis的数据结构&内部编码图:
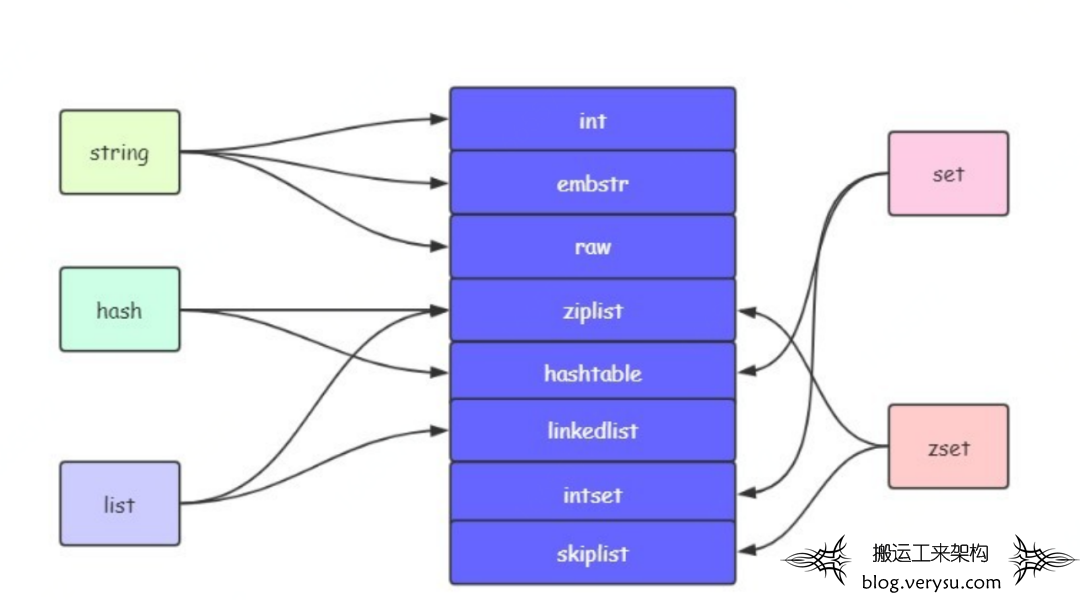
图7 Redis底层数据结构
4.2.1 SDS简单动态字符串
Redis没有采用原生C语言的字符串类型而是自己实现了字符串结构-简单动态字符串(simple dynamic string)。

图8 C语言字符串类型
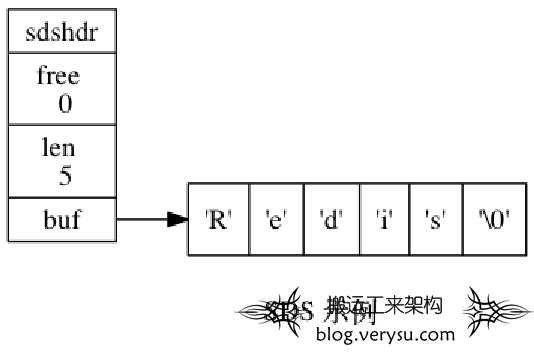
图9 SDS字符串类型
SDS与C语言字符串的区别:
- 获取字符串长度:C字符串的复杂度为O(N),而SDS的复杂度为O(1)。
- 杜绝缓冲区溢出(C语言每次需要手动扩容),如果C字符串想要扩容,在没有申请足够多的内存空间下,会出现内存溢出的情况,而SDS记录了字符串的长度,如果长度不够的情况下会进行扩容。
- 减少修改字符串时带来的内存重分配次数。
-
- 空间预分配,
- 规则1:修改后长度< 1MB,预分配同样大小未使用空间,free=len;
- 规则2:修改后长度 >= 1MB,预分配1MB未使用空间。
- 惰性空间释放,SDS 缩短时,不是回收多余的内存空间,而是free记录下多余的空间,后续有变更,直接使用free中记录的空间,减少分配。
- 空间预分配,
4.2.2 embstr & raw
Redis 的字符串有两种存储方式,在长度特别短时,使用 emb 形式存储(embeded),当长度超过 44 时,使用 raw 形式存储。
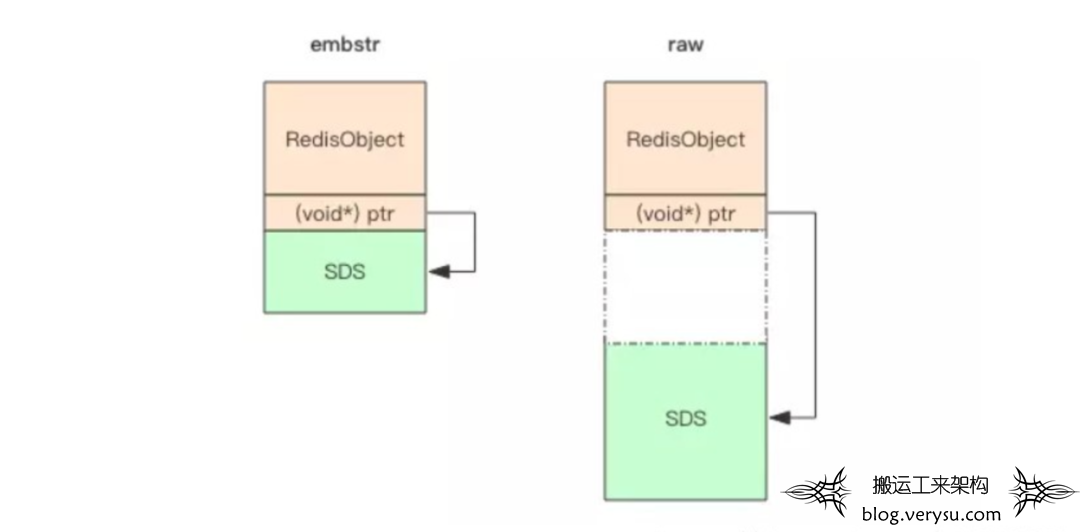
图10 embstr和raw数据结构
为什么分界线是 44 呢?
在CPU和主内存之间还有一个高速数据缓冲区,有L1,L2,L3三级缓存,L1级缓存时距离CPU最近的,CPU会有限从L1缓存中获取数据,其次是L2,L3。
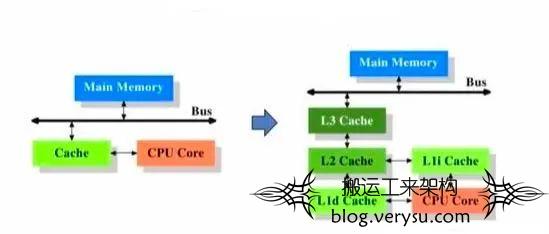
图11 CPU三级缓存
L1最快但是其存储空间也是有限的,大概64字节,抛去对象固定属性占用的空间,以及‘�’,剩余的空间最多是44个字节,超过44字节L1缓存就会存不下。

图12 SDS在L1缓存中的存储方式
4.2.3 字典(DICT)
Redis 作为 K-V 型内存数据库,所有的键值就是用字典来存储。字典就是哈希表,比如HashMap,通过key就可以直接获取到对应的value。而哈希表的特性,在O(1)时间复杂度就可以获得对应的值。
【Objective-c】
//字典结构数据
typedef struct dict {
dictType *type; //接口实现,为字典提供多态性
void *privdata; //存储一些额外的数据
dictht ht[2]; //两个hash表
long rehashidx. //渐进式rehash时记录当前rehash的位置
} dict;
两个hashtable通常情况下只有一个hashtable是有值的,另外一个是在进行rehash的时候才会用到,在扩容时逐渐的从一个hashtable中迁移至另外一个hashtable中,搬迁结束后旧的hashtable会被清空。
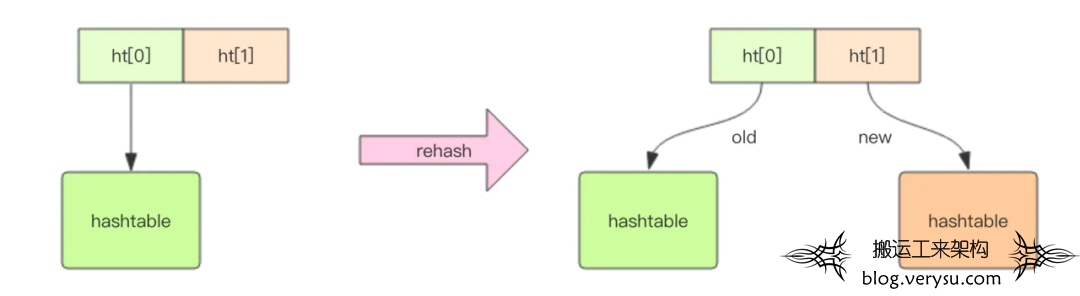
图13 Redis hashtable
【Objective-c】
//hashtable的结构如下:
typedef struct dictht {
dictEntry **table; //指向第一个数组
unsigned long size; //数组的长度
unsigned long sizemask; //用于快速hash定位
unsigned long used; //数组中元素的个数
} dictht;
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d; //用于zset,存储score值
} v;
struct dictEntry *next;
} dictEntry;
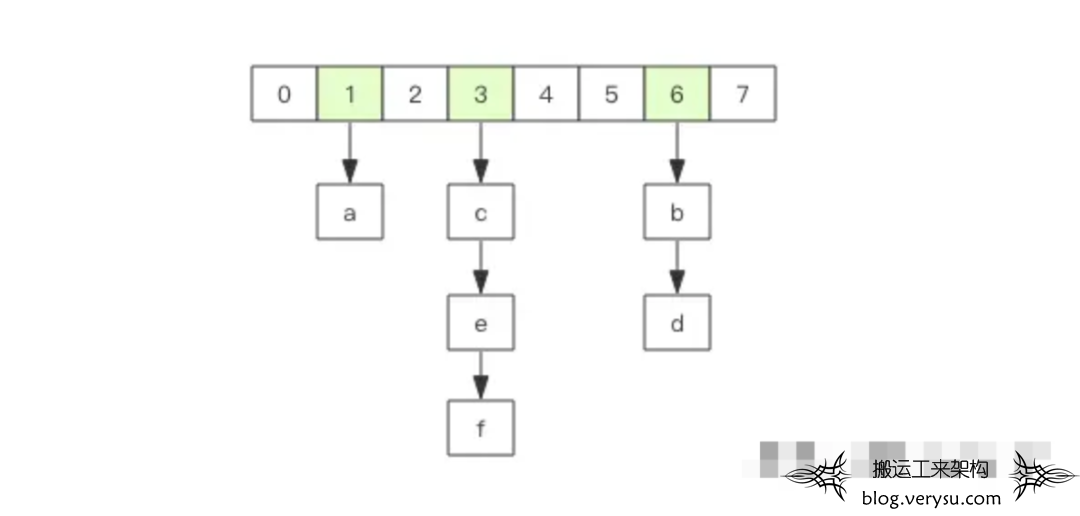
图14 Redis hashtable
4.2.4 压缩列表(ziplist)
redis为了节省内存空间,zset和hash对象在数据比较少的时候采用的是ziplist的结构,是一块连续的内存空间,并且支持双向遍历。
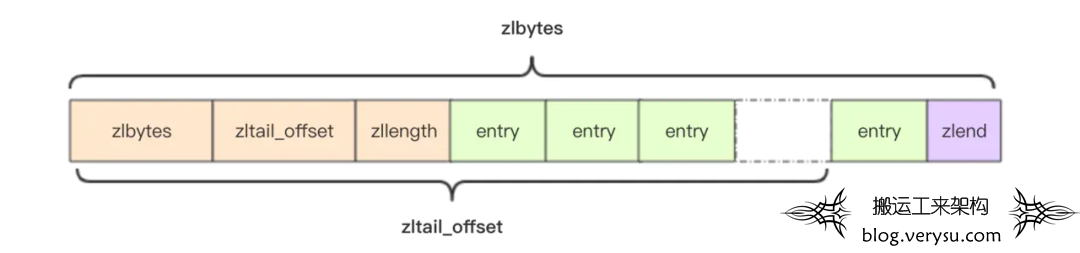
图15 ziplist数据结构
4.2.5 跳跃表
- 跳跃表是Redis特有的数据结构,就是在链表的基础上,增加多级索引提升查找效率。
- 跳跃表支持平均 O(logN),最坏 O(N)复杂度的节点查找,还可以通过顺序性操作批量处理节点。
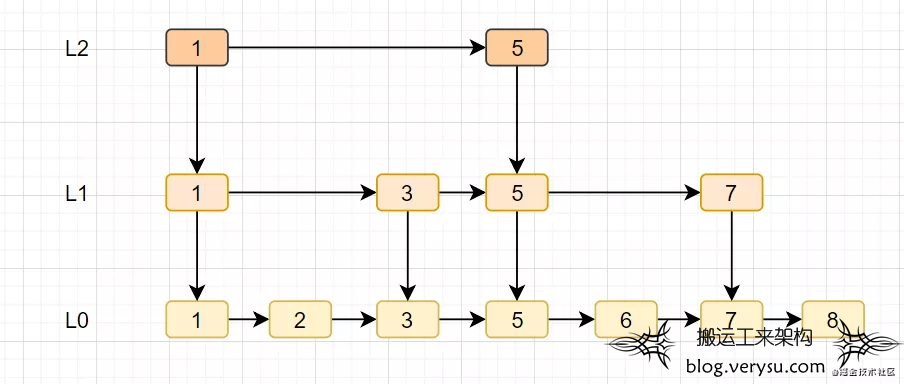
图16 跳跃表数据结构
-
String:如果存储数字的话,是用int类型的编码;如果存储非数字,小于等于39字节的字符串,是embstr;大于39个字节,则是raw编码。 -
List:如果列表的元素个数小于512个,列表每个元素的值都小于64字节(默认),使用ziplist编码,否则使用linkedlist编码。 -
Hash:哈希类型元素个数小于512个,所有值小于64字节的话,使用ziplist编码,否则使用hashtable编码。 -
Set:如果集合中的元素都是整数且元素个数小于512个,使用intset编码,否则使用hashtable编码。 -
Zset:当有序集合的元素个数小于128个,每个元素的值小于64字节时,使用ziplist编码,否则使用skiplist(跳跃表)编码
首先是单线程模型-避免了上下文切换造成的时间浪费,单线程指的是网络请求模块使用了一个线程,即一个线程处理所有网络请求,其他模块仍然会使用多线程;在使用多线程的过程中,如果没有一个良好的设计,很有可能造成在线程数增加的前期吞吐率增加,后期吞吐率反而增长没有那么明显了。
多线程的情况下通常会出现共享一部分资源,当多个线程同时修改这一部分共享资源时就需要有额外的机制来进行保障,就会造成额外的开销。
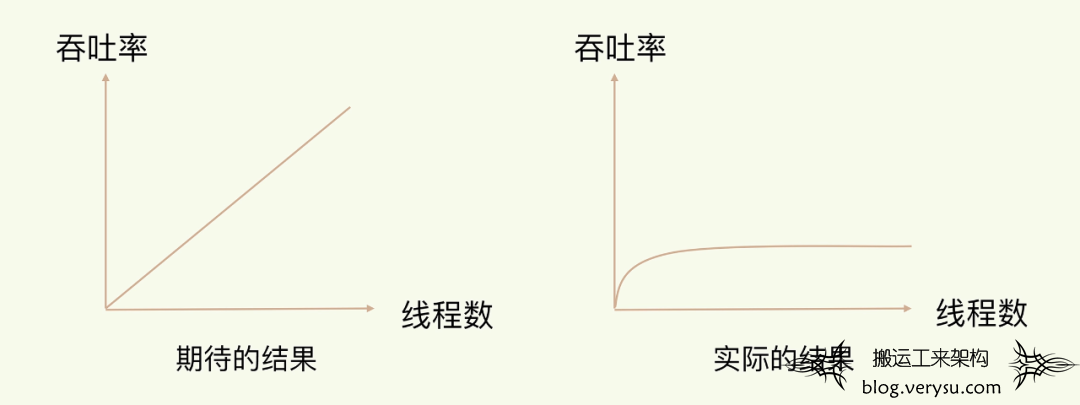
-
第一种:安排一个老师,按顺序逐个检查。先检查A,然后是B,之后是C、D...这中间如果有一个学生卡住,全班都会被耽误。这种模式就好比用循环挨个处理socket,根本不具有并发能力。这种方式只需要一个老师,但是耗时时间会比较长。 -
第二种:安排30个老师,每个老师检查一个学生的作业。这种类似于为每一个socket创建一个进程或者线程处理连接。这种方式需要30个老师(最消耗资源),但是速度最快。 -
第三种:安排一个老师,站在讲台上,谁解答完谁举手。这时C、D举手,表示他们作业做完了,老师下去依次检查C、D的答案,然后继续回到讲台上等。此时E、A又举手,然后去处理E和A。这种方式可以在最小的资源消耗的情况下,最快的处理完任务。
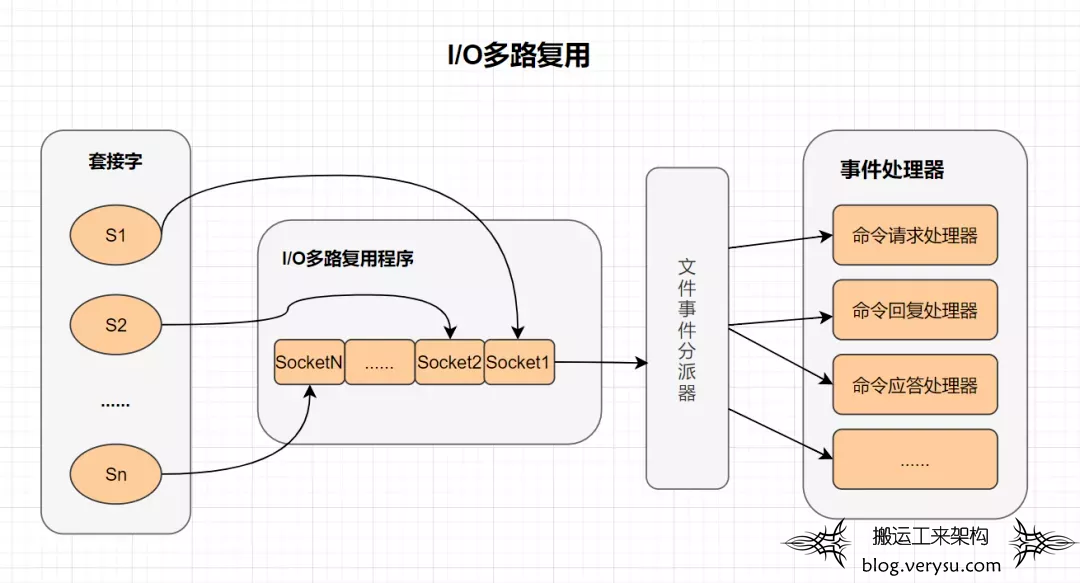
图18 I/O多路复用
使用场景
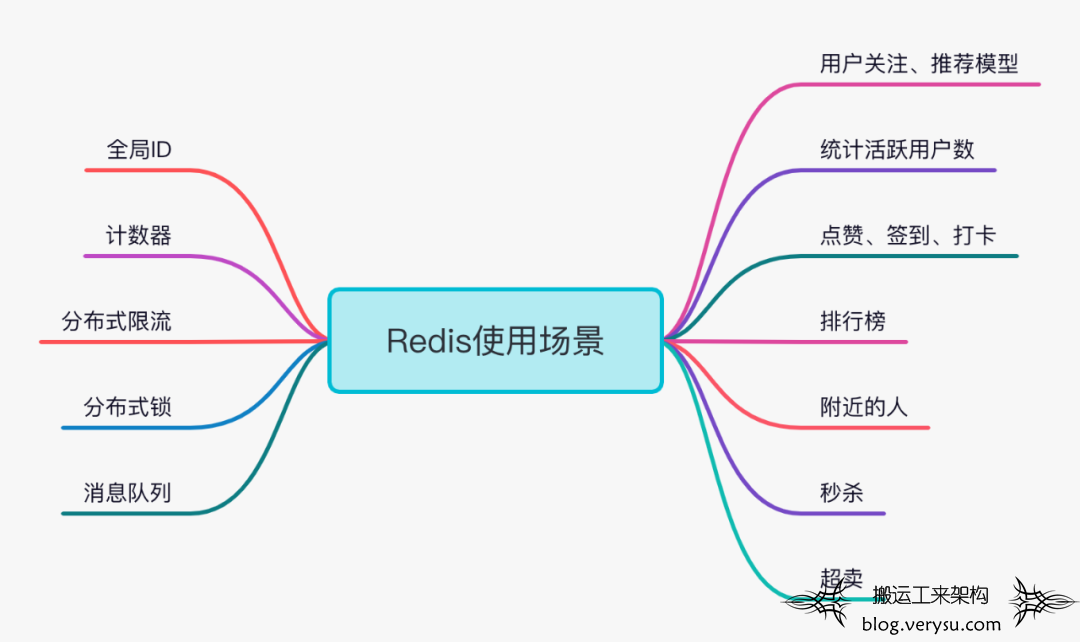
总结
- 纯内存操作,内存的访问是非常迅速的;
- 多路复用的I/O模型,可以高并发的处理更多的请求;
- 精心设计的高效的数据结构;
- 合理的内部数据编码,对内存空间的高效实用。


求点赞
求在看
本文仅供学习!所有权归属原作者。侵删!文章来源: 京东技术



文章评论