面对高并发调用的调用场景,针对不同的业务场景,处理方式往往各有不同,本文针对实际的业务场景,通过实际业务场景分析,调用量分析,最终采用合理的技术方案,完成实际的业务场景。
前言
在今年的敏捷团队建设中,我通过Suite执行器实现了一键自动化单元测试。Juint除了Suite执行器还有哪些执行器呢?由此我的Runner探索之旅开始了!
物流合约中心是京东物流合同管理的唯一入口。为商家提供合同的创建,盖章等能力,为不同业务条线提供合同的定制,归档,查询等功能。由于各个业务条线众多,为各个业务条线提供高可用查询能力是物流合约中心重中之重。同时计费系统在每个物流单结算时,都需要查询合约中心,确保商家签署的合同内容来保证计费的准确性。
业务场景
理解,首先 MCube 会依据模板缓存状态判断是否需要网络获取最新模板,当获取到模板后进行模板加载,加载阶段会将产物转换为视图树的结构,转换完成后将通过表达式引擎解析表达式并取得正确的值,通过事件解析引擎解析用户自定义事件并完成事件的绑定,完成解析赋值以及事件绑定后进行视图的渲染,最终将目标页面展示到屏幕。
从业务调用的来源来看,合同的调用大部分是计费系统在每个物流单计费的时候,需要调用合约中心来判断,该商家是否签署合同。
 图1.业务调用来源
图1.业务调用来源
从业务调用的入参来看,绝大部分是多个条件来查询合同,但基本都是查询某个商家,或通过商家的某个属性(例如业务账号)来查询合同。
从调用的结果来看,40%的查询是没有结果的,其中绝大部分是因为商家没有签署过合同,导致查询为空。其余的查询结果,每次返回的数量较少,一般一个商家只有3到5个合同。
调用量
目前合同的调用量,大概是在每天2000W次。
一天的调用量统计:
图2.一天的调用量统计
调用时间
每天高峰期为上班时间,最高峰为4W/min。
一个月的调用量统计:
图3.一个月的调用量统计
由上可以看出,合同每日的调用量比较平均,主要集中在9点到12点和13点到18点,也就是上班时间,整体调用量较高,基本不存在调用暴增的情况。
总体分析来看,合约中心的查询,调用量较高,且较平均,基本都是随机查询,也并不存在热点数据,其中无效查询占比较多,每次查询条件较多,返回数据量比不大。
方案设计
理解,首先 MCube 会依据模板缓存状态判断是否需要网络获取最新模板,当获取到模板后进行模板加载,加载阶段会将产物转换为视图树的结构,转换完成后将通过表达式引擎解析表达式并取得正确的值,通过事件解析引擎解析用户自定义事件并完成事件的绑定,完成解析赋值以及事件绑定后进行视图的渲染,最终将目标页面展示到屏幕。
从整体业务场景分析来看,决定做三层防护来保证调用量的支撑,同时需要对数据一致性做好处理。第一层是布隆过滤器,来拦截绝大部分无效的请求。第二层是redis缓存数据,来保证各种查询条件的查询尽量命中redis。第三层是直接查询数据库的兜底方案。同时再保证数据一致性的问题,借助于广播mq来实现。
图4.三层防护示意
由于近一半的查询都是空,首先想到这是缓存穿透的现象。
缓存穿透(cache penetration)是用户访问的数据既不在缓存当中,也不在数据库中。出于容错的考虑,如果从底层数据库查询不到数据,则不写入缓存。这就导致每次请求都会到底层数据库进行查询,缓存也失去了意义。当高并发或有人利用不存在的Key频繁攻击时,数据库的压力骤增,甚至崩溃,这就是缓存穿透问题。
由于存在缓存穿透问题,首先想到用商家的唯一标识来做布隆过滤器以解决缓存穿透问题。至于布隆过滤器是由一个长度为 M 比特的位数组(bit array)与 K 个哈希函数(hash function) 组成的数据结构。布隆过滤器主要用于用于检索一个元素是否在一个集合中,原理不再阐述。
图5.布隆过滤器示意
-
不需要存储数据,只用比特表示,因此在空间占用率上有巨大的优势
-
检索效率高,插入和查询的时间复杂度都为 O(K)(K 表示哈希函数的个数)
-
哈希函数之间相互独立,可以在硬件指令层次并行计算,因此效率较高。
-
存在不确定的因素,无法判断一个元素是否一定存在,所以不适合要求 100% 准确率的场景。
-
布隆过滤器分析:面对优点,完全符合诉求,针对缺点1,会有极少的数据穿透对系统来说并无压力。针对缺点2,合同的数据,本来就是不可删除的。如果合同过期,可以查出单个商家的所有合同,从合同的结束时间来判断合同是否有效,并不需要去删除布隆过滤器里的元素。
考虑到调用redis布隆过滤器,会走一次网络,而查询近一半都是无效查询,故决定使用本地布隆过滤器,这样就可以减少一次网络请求。但是如果是本地布隆过滤器,在更新时,就需要对所有机器的本地布隆过滤器更新。监听合同的状态来更新,通过mq的广播模式,来对布隆过滤器插入元素,这样就做到了所有机器上的布隆过滤器统一元素插入。
引入缓存,就要考虑缓存穿透,缓存击穿,缓存雪崩的三大问题。
其中缓存穿透,已在第一层防护中处理,这里只解决缓存击穿,缓存雪崩的问题。
缓存击穿(Cache Breakdown)缓存雪崩是指只大量热点key同时失效的情况,如果是单个热点key,在不停的扛着大并发,在这个key失效的瞬间,持续的大并发请求就会击破缓存,直接请求到数据库,好像蛮力击穿一样。这种情况就是缓存击穿。
解决方案:使用分布式锁,针对同一个商家,只让一个线程构建缓存,其他线程等待构建缓存执行完毕,重新从缓存中获取数据。
缓存雪崩(Cache Avalanche)当缓存中大量热点缓存采用了相同的实效时间,就会导致缓存在某一个时刻同时实效,请求全部转发到数据库,从而导致数据库压力骤增,甚至宕机。从而形成一系列的连锁反应,造成系统崩溃等情况,这就是缓存雪崩。
解决方案:缓存雪崩的解决方案是将key的过期设置为固定时间范围内的一个随机数,让key均匀的失效即可。
引入缓存,就要考虑缓存数据激增及缓存淘汰策略的问题。
考虑使用redis缓存,因为每次查询的条件都不一样,返回的结果数据又比较少,就考虑限制查询都必须有一个固定的查询条件,商家编码。如果查询条件中没有查商家编码,则可以通过商家名称,商家业务账号这些条件来反查商家编码。
这样就可以缓存单个商家编码的所有合同,然后再通过代码使用filter对其他查询条件做支持,避免不同的查询条件都去缓存数据而引发的缓存数据更新、缓存数据淘汰以及缓存数据一致等问题。
同时只缓存单个商家编码的所有合同,缓存的数据量也是可控,每个缓存的大小也可控,基本不会出现redis大key的问题。
如图所示 对于商家编码维度的缓存数据,可以通过监听合同的状态,使用mq广播来删除对应商家的缓存,从而避免出现缓存和数据一致性的相关问题。
图6.避免出现缓存和数据一致性的相关问题处理方式
第三层防护,自然是数据库,如果有查询经过了第一层和第二层,那便需要直接查询数据库来返回结果,同时,对直接调用到数据库的线程进行监控。
图7.对直接调用到数据库的线程进行监控
为避免一些未知的查询大量查询涌入,导致数据库调用保证的问题,尤其是大促时,可以提前对数据库里的所有商家合同进行提前缓存。在缓存时,为避免缓存雪崩问题,可以将key的过期设置为固定时间范围内的一个随机数,让key均匀的失效。
同时,为避免依然存在意外的情况,有大量查询涌入,可以通过ducc开关控制数据库的查询,如调用量太高导致无法支撑,则直接关闭数据库的调用,保证数据库不会直接宕机导致整个业务不可用。
总结
理解,首先 MCube 会依据模板缓存状态判断是否需要网络获取最新模板,当获取到模板后进行模板加载,加载阶段会将产物转换为视图树的结构,转换完成后将通过表达式引擎解析表达式并取得正确的值,通过事件解析引擎解析用户自定义事件并完成事件的绑定,完成解析赋值以及事件绑定后进行视图的渲染,最终将目
本文主要分析了面对高并发调用的调用场景设计及的技术方案,在引入缓存的同时,也要考虑实际的调用入参及结果,面对增加的网络请求,是否可以进一步减少。面对redis缓存,是否可以通过一些手段避免所有查询条件都需要缓存,带来的缓存爆炸,缓存淘汰策略等问题,以及解决缓存与数据一致等一系列问题。
本方案是根据具体的查询业务场景设计具体的技术方案,针对不同的业务场景,对应的技术方案也是不一样的。
打造SAAS化服务的会员徽章体系,可以作为标准的产品化方案统一对外输出。结合现有平台的通用能力,实现会员行为全路径覆盖,并能结合企业自身业务特点,规划相应的会员精准营销活动,提升会员忠诚度和业务的持续增长。
底层能力:维护用户基础数据、行为数据建模、用户画像分析、精准营销策略的制定
▪功能支撑:会员成长体系、等级计算策略、权益体系、营销底层能力支持
▪用户活跃:会员关怀、用户触达、活跃活动、业务线交叉获客、拉新促活
本文仅供学习!所有权归属原作者。侵删!文章来源: 京东技术 -京东物流 :http://mp.weixin.qq.com/s/AVVWXQru0ZKqTyRxTcIyBQ

 图1.业务调用来源
图1.业务调用来源 图2.一天的调用量统计
图2.一天的调用量统计 图3.一个月的调用量统计
图3.一个月的调用量统计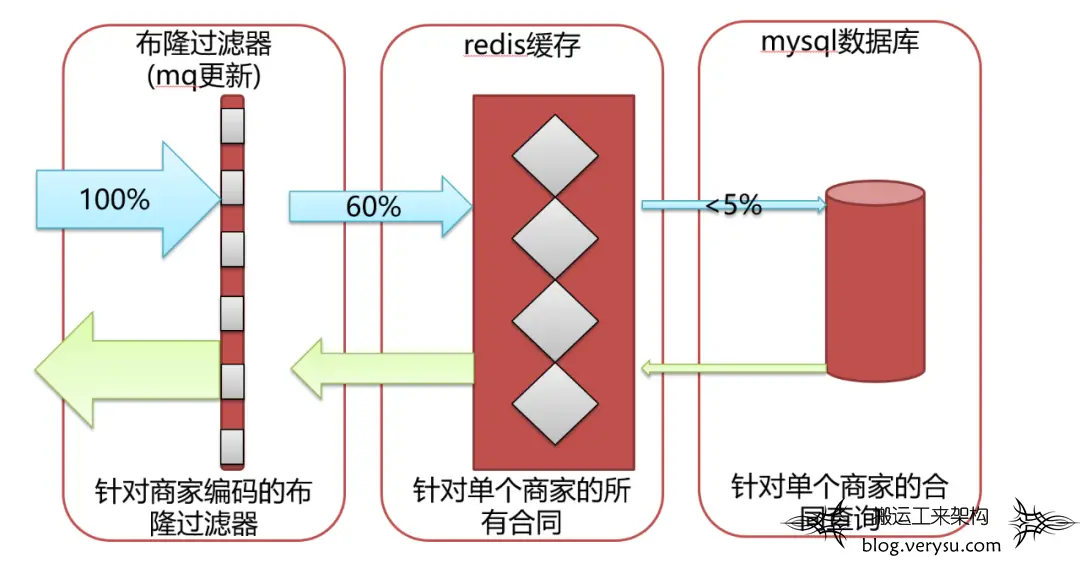 图4.三层防护示意
图4.三层防护示意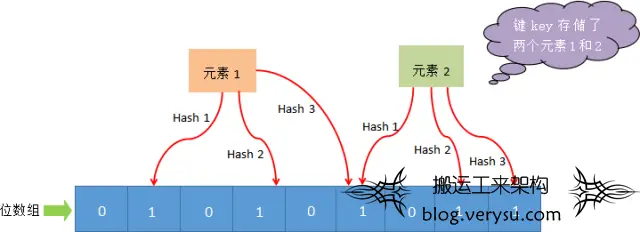 图5.布隆过滤器示意
图5.布隆过滤器示意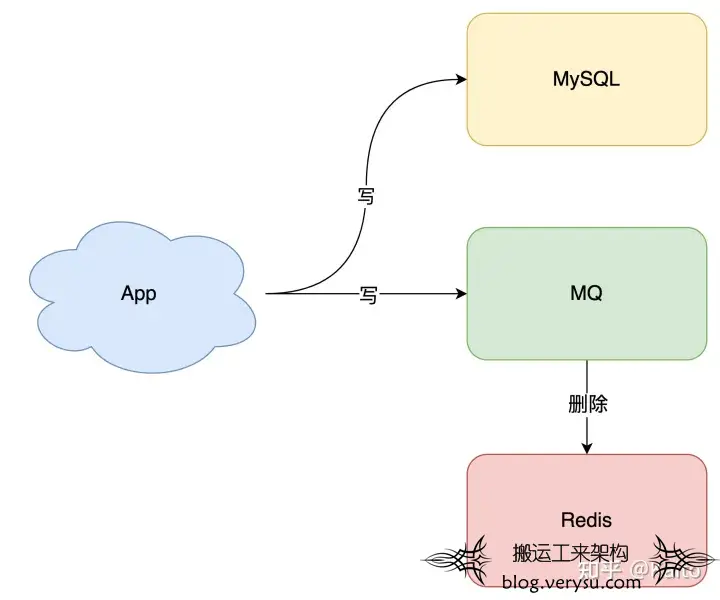 图6.避免出现缓存和数据一致性的相关问题处理方式
图6.避免出现缓存和数据一致性的相关问题处理方式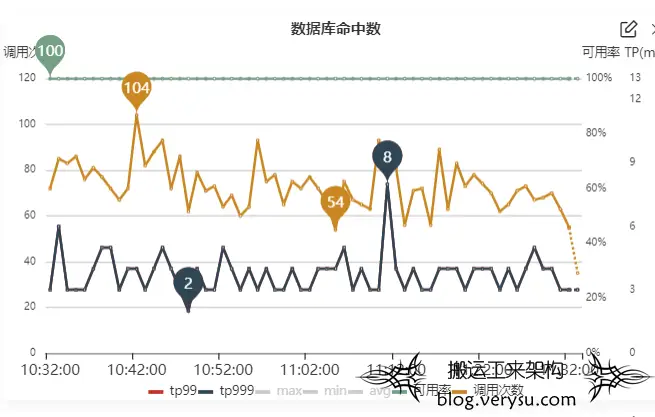 图7.对直接调用到数据库的线程进行监控
图7.对直接调用到数据库的线程进行监控


文章评论