
One day I watched a YouTube video about a software engineer who worked in FAANG and mentioned how most of his days consisted of meetings, bug fixes, and hardly writing any new code.
有一天,我在YouTube上看了一个视频,讲述了一位在FAANG工作的软件工程师,他提到他的大部分时间都是开会、修复错误,几乎不写任何新代码。
The more senior you become, the more code you write. I was utterly wrong. Since then, I started looking at my occupation as a software engineer much differently.
你变得越高级,你写的代码就越多。我完全错了。从那以后,我开始以不同的方式看待我作为软件工程师的职业。
What am I being hired to do?
我被雇用是为了做什么?
What is system design? 什么是系统设计?
System design defines the architecture, components, interfaces, and data for a system to satisfy the specified requirements. It involves identifying and defining the functional and non-functional requirements of the system, as well as the constraints and trade-offs that must be made during the development process.
系统设计定义了系统的体系结构、组件、接口和数据,以满足指定的要求。它涉及识别和定义系统的功能和非功能需求,以及在开发过程中必须做出的约束和权衡。
The goal of system design is to create a system that is efficient, reliable, and easy to maintain while also meeting the needs of the users and stakeholders. This process typically involves a combination of both top-down and bottom-up approaches, emphasizing modularity, scalability, and reusability.
系统设计的目标是创建一个高效、可靠且易于维护的系统,同时满足用户和利益相关者的需求。此过程通常涉及自上而下和自下而上方法的组合,强调模块化、可伸缩性和可重用性。
Proper system design considers the users' location, the technology being used, and the content shared throughout the network it lives in.
正确的系统设计会考虑用户的位置、正在使用的技术以及在其所在的网络中共享的内容。
System design in software is essential for several reasons.
出于几个原因,软件中的系统设计至关重要。
- It helps to ensure that the final product meets the needs of the users and stakeholders. By clearly defining the requirements and constraints of the system, designers can ensure that the software will be usable, efficient, and effective.
它有助于确保最终产品满足用户和利益相关者的需求。通过明确定义系统的要求和约束,设计人员可以确保软件可用、高效和有效。 - System design allows for the creation of a scalable and modular architecture. This makes it easier to add new features or make changes to the system in the future without disrupting the existing functionality. It also enables the reuse of code and components across different projects, saving time and resources.
系统设计允许创建可扩展的模块化架构。这样可以更轻松地在将来添加新功能或对系统进行更改,而不会中断现有功能。它还支持在不同项目中重用代码和组件,从而节省时间和资源。 - System design plays a crucial role in the maintainability of the software. A well-designed system is easier to understand, test, and debug, reducing the likelihood of introducing new bugs and making fixing existing ones easier.
系统设计在软件的可维护性中起着至关重要的作用。设计良好的系统更易于理解、测试和调试,从而降低引入新错误的可能性,并使修复现有错误更容易。 - System design is essential for creating efficient and high-performing software. By carefully considering the performance and scalability requirements during the design process, designers can ensure that the final product will meet the demands of the users and not cause bottlenecks or fail under heavy load.
系统设计对于创建高效和高性能的软件至关重要。通过在设计过程中仔细考虑性能和可扩展性要求,设计人员可以确保最终产品满足用户的需求,而不会在重负载下造成瓶颈或故障。
Questions to ask before designing a software system
设计软件系统之前要问的问题
It’s important to note that these are just a few examples of the questions that a software engineer should consider when creating a large-scale system. The questions will depend on the system's requirements and the domain it operates in.
重要的是要注意,这些只是软件工程师在创建大规模系统时应考虑的问题的几个例子。这些问题将取决于系统的要求及其运行的领域。
What are the goals and requirements of the system?
系统的目标和要求是什么?What are the expected traffic and usage patterns for the system?
系统的预期流量和使用模式是什么?How should the system handle failures and errors?
系统应如何处理故障和错误?How should the system handle scalability and performance?
系统应如何处理可伸缩性和性能?How should the system handle security and access control?
系统应如何处理安全性和访问控制?How should the system handle data storage and retrieval?
系统应如何处理数据存储和检索?How should the system handle data consistency and integrity?
系统应如何处理数据的一致性和完整性?How should the system handle data backups and recovery?
系统应如何处理数据备份和恢复?How should the system handle monitoring and logging?
系统应如何处理监视和日志记录?How should the system handle updates and maintenance?
系统应如何处理更新和维护?How should the system handle integration with other systems and services?
系统应如何处理与其他系统和服务集成?How should the system handle regulatory compliance and data privacy?
系统应如何处理法规遵从性和数据隐私?How should the system handle disaster recovery and business continuity?
系统应如何处理灾难恢复和业务连续性?How should the system handle user experience and usability?
系统应该如何处理用户体验和可用性?
This article’s primary purpose is to help developers understand system design concepts. This is not a tutorial but more of an overview of this topic.
本文的主要目的是帮助开发人员理解系统设计概念。这不是教程,而是本主题的更多概述。
Now, let’s dive deeper! 现在,让我们更深入地了解一下!
Load Balancers 负载均衡器
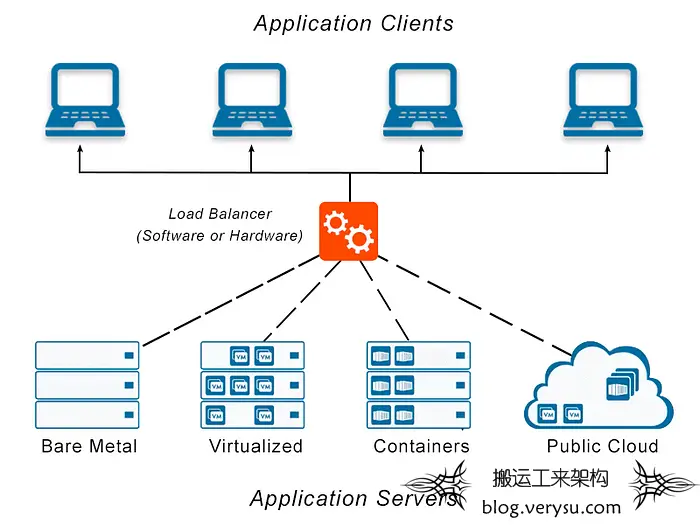
A load balancer is a device or service that distributes network or application traffic across multiple servers. A load balancer's primary purpose is to increase applications' availability and scalability by distributing the workload evenly across multiple servers. This ensures that no single server becomes a bottleneck and that the system can handle a high traffic volume.
负载均衡器是在多个服务器之间分配网络或应用程序流量的设备或服务。负载均衡器的主要用途是通过在多个服务器之间均匀分布工作负载来提高应用程序的可用性和可伸缩性。这可确保没有单个服务器成为瓶颈,并且系统可以处理高流量。
Think of trying to empty a large water tank. A load balancer helps empty the water tank by adding more holes at the bottom to increase water flow so that incoming water won't overflow out of the reservoir.
想想试图清空一个大水箱。负载均衡器通过在底部添加更多孔来增加水流量,以便进水不会溢出水箱,从而帮助清空水箱。
Load balancers use various algorithms to determine how to distribute the traffic, such as round-robin, where requests are sent to each server in turn, or least connections, where requests are sent to the server with the fewest active connections. Load balancers can also monitor each server's health, and if a server becomes unavailable, the load balancer will redirect traffic to the other available servers.
负载均衡器使用各种算法来确定如何分配流量,例如轮询,其中请求依次发送到每个服务器,或最少连接,其中请求发送到活动连接最少的服务器。负载均衡器还可以监视每个服务器的运行状况,如果服务器不可用,负载均衡器会将流量重定向到其他可用服务器。
DNS load balancers DNS 负载均衡器
DNS load balancing is another popular method of distributing network traffic across multiple servers using the Domain Name System (DNS). It configures various IP addresses for a single domain name. Then it uses a DNS server to distribute incoming traffic to one of the IP addresses based on a load-balancing algorithm.
DNS 负载平衡是使用域名系统 (DNS) 在多个服务器之间分配网络流量的另一种流行方法。它为单个域名配置各种 IP 地址。然后,它使用 DNS 服务器根据负载平衡算法将传入流量分配到其中一个 IP 地址。
Geographic-based load balancing
基于地理位置的负载平衡
Another method is geographic-based load balancing, where the DNS server routes the traffic to the closest server based on the client's location, making the request. This can improve performance and reduce latency for users as they are directed to the server closest to them.
另一种方法是基于地理位置的负载平衡,其中 DNS 服务器根据客户端的位置将流量路由到最近的服务器,从而发出请求。这可以提高性能并减少用户被定向到离他们最近的服务器的延迟。
Caching 缓存
Caching is a technique used in system design to improve the performance and scalability of a system by storing frequently accessed data in a temporary storage location, known as a cache. There are several benefits of caching in system design:
缓存是系统设计中使用的一种技术,通过将经常访问的数据存储在临时存储位置(称为缓存)来提高系统的性能和可伸缩性。缓存在系统设计中有几个好处:
- Reduced Latency: Caching data locally can significantly reduce the time it takes to access the data, as it eliminates the need to retrieve the data from a remote location. This can result in faster response times for the end user.
减少延迟:在本地缓存数据可以显著减少访问数据所需的时间,因为它消除了从远程位置检索数据的需要。这可以为最终用户带来更快的响应时间。 - Increased Throughput: Caching can also increase the number of requests a system can handle simultaneously, as it reduces the number of requests that need to be sent to the backend server. This can help prevent the system from becoming overwhelmed during high-traffic periods.
增加吞吐量:缓存还可以增加系统可以同时处理的请求数量,因为它减少了需要发送到后端服务器的请求数量。这有助于防止系统在高流量期间不堪重负。 - Reduced Load on Backend Servers: Caching can also reduce the load on backend servers by reducing the number of requests they need to handle. This can improve the overall performance and scalability of the system.
减少后端服务器上的负载:缓存还可以通过减少后端服务器需要处理的请求数量来减少后端服务器上的负载。这可以提高系统的整体性能和可伸缩性。 - Offline Access: Caching data locally can also enable offline access to the data, even when the backend server is unavailable. This can be particularly useful for mobile or IoT applications where connectivity is only sometimes guaranteed.
脱机访问:在本地缓存数据还可以启用对数据的脱机访问,即使后端服务器不可用也是如此。这对于移动或物联网应用特别有用,在这些应用中,连接性有时只能得到保证。 - Cost-effective: Caching can reduce the costs associated with scaling a system by reducing the load on backend servers and the need for additional hardware or network bandwidth.
经济高效:缓存可以通过减少后端服务器上的负载以及对额外硬件或网络带宽的需求来降低与扩展系统相关的成本。
In memory caching 内存缓存
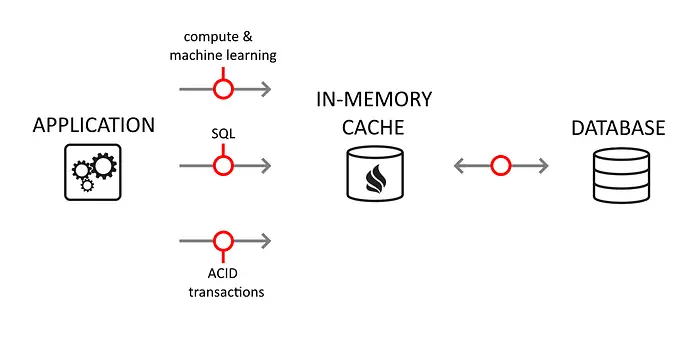
In-memory caching is a type of caching that stores data in the system’s main memory (RAM) rather than on disk. This allows for faster access to the cached data, as data stored in memory can be accessed much more quickly than stored on disk.
内存中缓存是一种将数据存储在系统主内存 (RAM) 而不是磁盘中的缓存。这允许更快地访问缓存的数据,因为存储在内存中的数据可以比存储在磁盘上更快地访问。
The main advantage of in-memory caching is its high performance. Since data is stored in RAM, it can be accessed much faster than data stored on disk. This can significantly improve the response times of a system, especially for frequently accessed data.
内存中缓存的主要优点是其高性能。由于数据存储在 RAM 中,因此访问速度比存储在磁盘上的数据快得多。这可以显著缩短系统的响应时间,尤其是对于经常访问的数据。
Another advantage of in-memory caching is that it doesn’t require disk I/O operations, which can be slow and resource-intensive. This can help to reduce the load on the system and improve overall performance.
内存中缓存的另一个优点是它不需要磁盘 I/O 操作,这可能很慢且占用大量资源。这有助于减少系统负载并提高整体性能。
In-memory caching can be implemented using various tools and libraries, such as Memcached, Redis, and Hazelcast. These tools provide a simple interface for storing and retrieving data from memory, and they can also be used to implement distributed caching across multiple servers.
内存缓存可以使用各种工具和库来实现,例如Memcached,Redis和Hazelcast。这些工具提供了用于存储和从内存中检索数据的简单界面,还可用于实现跨多个服务器的分布式缓存。
It’s worth noting that in-memory caching has limitations; mainly, the available RAM's size of the data that can be stored in memory is limited. Also, the data stored in memory is volatile, meaning it will be lost if the system is rebooted or crashes.
值得注意的是,内存中缓存有局限性;主要是,可以存储在内存中的数据的可用RAM大小是有限的。此外,存储在内存中的数据是易失性的,这意味着如果系统重新启动或崩溃,它将丢失。
CDNs 内容分发网络
Content Delivery Networks (CDNs) are a distributed network of servers that deliver content, such as web pages, images, and videos, to users based on their geographic location. CDNs can help with software caching by providing a way to cache and distribute content closer to the end-users, reducing the latency and improving the system's performance.
内容交付网络 (CDN) 是服务器的分布式网络,根据用户的地理位置向用户交付内容,例如网页、图像和视频。CDN 可以通过提供一种在更靠近最终用户的位置缓存和分发内容的方法来帮助软件缓存,从而减少延迟并提高系统性能。
When a user requests content from a website or application, the request is first sent to the closest CDN server, an “edge server.” The edge server checks its cache to see if the requested content is stored locally. If the content is found in the stock, it is delivered to the user immediately. If the content is not found in the cache, the edge server retrieves it from the origin server and caches it locally for future requests.
当用户从网站或应用程序请求内容时,请求首先发送到最近的 CDN 服务器,即“边缘服务器”。边缘服务器检查其缓存以查看请求的内容是否存储在本地。如果在库存中找到内容,则会立即交付给用户。如果在缓存中找不到内容,边缘服务器将从源服务器检索该内容,并将其缓存在本地以供将来请求。
By caching content locally on the edge servers, CDNs can reduce the load on the origin server and reduce the latency for the end user. This can be especially beneficial for websites and applications that serve many users or for users located far away from the origin server.
通过在边缘服务器上本地缓存内容,CDN 可以减少源服务器上的负载并减少最终用户的延迟。这对于为许多用户提供服务的网站和应用程序或远离源服务器的用户尤其有用。
Additionally, CDNs can also help to improve the security and availability of the system by providing DDoS protection, SSL termination, and load balancing.
此外,CDN 还可以通过提供 DDoS 保护、SSL 终止和负载平衡来帮助提高系统的安全性和可用性。
Databases 数据库
Database Schema Design 数据库架构设计
Database schema design is creating a blueprint for a database, which defines the structure of the data and the relationships between different data elements. This includes defining the tables, fields, keys, indexes, and constraints that make up the database.
数据库架构设计是为数据库创建蓝图,该蓝图定义了数据的结构以及不同数据元素之间的关系。这包括定义构成数据库的表、字段、键、索引和约束。
A good database schema design is essential for ensuring the database is efficient, flexible, and easy to maintain. It should be based on a clear understanding of the requirements and goals of the system, and it should be designed to be scalable, secure, and reliable.
良好的数据库架构设计对于确保数据库高效、灵活且易于维护至关重要。它应基于对系统要求和目标的清晰理解,并且应设计为可伸缩、安全可靠。
The process of database schema design typically involves several steps, including:
数据库架构设计过程通常涉及几个步骤,包括:
- Defining the entities and their relationships
定义实体及其关系 - Identifying the attributes and data types for each entity
标识每个实体的属性和数据类型 - Defining the keys and constraints for each table
定义每个表的键和约束 - Creating indexes to improve query performance
创建索引以提高查询性能 - Normalizing the database to eliminate redundancy and improve data integrity
规范化数据库以消除冗余并提高数据完整性 - Testing and documenting the schema for ease of use
测试和记录架构以使其易于使用
It’s also important to note that design is an ongoing process, as the database needs to change and adapt over time.
同样重要的是要注意,设计是一个持续的过程,因为数据库需要随着时间的推移而变化和适应。
Database Indexes 数据库索引
A database index is a data structure that improves the speed of data retrieval operations on a database table. It allows the database management system to quickly find and retrieve specific rows of data from the table. Indexes are created on one or more columns of a table, and the data in those columns is stored in a specific way (such as in a B-tree or hash table) to optimize lookup performance.
数据库索引是一种数据结构,用于提高对数据库表执行数据检索操作的速度。它允许数据库管理系统快速查找和检索表中的特定数据行。索引是在表的一个或多个列上创建的,这些列中的数据以特定方式(例如在 B 树或哈希表中)存储,以优化查找性能。
Regarding system design, indexes can significantly improve a database-driven application's performance by reducing the time it takes to retrieve data from the table. This can be especially important in large and complex systems where there is a lot of data to be retrieved or where multiple users frequently access the data. Using indexes can also reduce the load on the database server, as the server does not need to scan the entire table to find the desired data.
关于系统设计,索引可以通过减少从表中检索数据所需的时间来显著提高数据库驱动的应用程序的性能。这在需要检索大量数据或多个用户频繁访问数据的大型复杂系统中尤其重要。使用索引还可以减少数据库服务器上的负载,因为服务器不需要扫描整个表来查找所需的数据。
It is important to note that creating indexes can also have negative impacts, such as increased disk space and update costs, so it is essential to be selective and strategic when creating indexes. It is always recommended to test the performance of your system with and without indexes, monitor the impact of indexes on your system, and adjust accordingly.
请务必注意,创建索引还会产生负面影响,例如增加磁盘空间和更新成本,因此在创建索引时必须有选择性和战略性。始终建议测试带和不带索引的系统性能,监视索引对系统的影响,并相应地进行调整。
Database Sharding 数据库分片
Database sharding is a technique used to horizontally partition a large database into smaller, more manageable pieces called shards. Each shard is a separate, independent data store that contains a subset of the data from the original database. The data within each shard is typically organized by some key, such as a user ID, to ensure that all the data for a specific user is in the same shard.
数据库分片是一种技术,用于将大型数据库水平分区为更小、更易于管理的部分,称为分片。每个分片都是一个单独的独立数据存储,其中包含原始数据库中数据的子集。每个分片中的数据通常按某个键(如用户 ID)进行组织,以确保特定用户的所有数据都位于同一分片中。
Sharding can be useful in a number of different scenarios, such as when a database has grown too large to be efficiently managed by a single server, or when a high volume of read or write requests is causing performance issues. By distributing the data across multiple servers, sharding can improve the scalability and performance of a database-driven application.
分片在许多不同的场景中都很有用,例如当数据库变得太大而无法由单个服务器有效管理时,或者当大量读取或写入请求导致性能问题时。通过跨多个服务器分布数据,分片可以提高数据库驱动应用程序的可伸缩性和性能。
Several techniques can be used to implement sharding, such as:
可以使用多种技术来实现分片,例如:
-Range-based sharding: the data is partitioned based on a range of values, such as a user ID range,
-基于范围的分片:根据一系列值对数据进行分区,例如用户 ID 范围、
-Hash-based sharding: the data is partitioned based on a hash function applied to a key value, such as a user ID,
-基于哈希的分片:数据根据应用于键值的哈希函数进行分区,例如用户 ID,
-List-based sharding: the data is partitioned based on a predefined list of values, such as a country or region.
-基于列表的分片:根据预定义的值列表(例如国家或地区)对数据进行分区。
It is important to note that sharding requires a shard key, which is a field used to determine which shard a particular record belongs to. Also, it is essential to consider that sharding adds complexity to the system, so it should be considered as a last resort when other solutions, such as indexing, caching, and query optimization, are exhausted.
需要注意的是,分片需要一个分片键,这是一个用于确定特定记录属于哪个分片的字段。此外,必须考虑到分片会增加系统的复杂性,因此当其他解决方案(如索引、缓存和查询优化)用尽时,应将其视为最后的手段。
API Design 接口设计
API (Application Programming Interface) design involves planning and creating a set of interfaces, protocols, and tools for building software and applications. The goal of API design is to provide a consistent and efficient way for different software systems to communicate and share data. This typically involves defining the methods, inputs, outputs, and other specifications for the API, as well as testing and documenting the API for ease of use.
API(应用程序编程接口)设计涉及规划和创建一组用于构建软件和应用程序的接口、协议和工具。API 设计的目标是为不同的软件系统提供一致且高效的方式来通信和共享数据。这通常涉及定义 API 的方法、输入、输出和其他规范,以及测试和记录 API 以便于使用。
Slave-Master Replications
从主复制
In a slave-master replication setup, one database server (the master) is designated as the primary source of data, and one or more other servers (the slaves) are configured to replicate the data from the master. The master server continuously updates its data and makes these changes available to the slaves, which then copy and apply these changes to their own databases.
在从主复制设置中,一个数据库服务器(主服务器)被指定为数据的主要来源,一个或多个其他服务器(从属服务器)被配置为从主服务器复制数据。主服务器不断更新其数据并将这些更改提供给从服务器,然后从服务器将这些更改复制并应用到自己的数据库中。
This type of replication is used to provide redundancy and high availability, as the slaves can be used to handle read requests and to provide failover in case the master goes down. It can also be used to scale out the read-heavy workloads.
这种类型的复制用于提供冗余和高可用性,因为从属服务器可用于处理读取请求,并在主服务器出现故障时提供故障转移。它还可用于横向扩展读取密集型工作负载。
In a master-slave replication, the master server is responsible for handling all write operations, and the slaves only replicate the data and can’t be written to. This allows the master to focus on handling writes while the slaves handle read-only queries, which can help to improve performance.
在主从复制中,主服务器负责处理所有写入操作,而从服务器仅复制数据,不能写入。这允许主站专注于处理写入,而从站处理只读查询,这有助于提高性能。
There are several different types of slave-master replication, such as statement-based, row-based or mixed replication, each with its own advantages and disadvantages, and different replication techniques, like asynchronous and semi-synchronous replication.
有几种不同类型的从属主复制,例如基于语句的复制、基于行的或混合复制,每种复制都有自己的优点和缺点,以及不同的复制技术,如异步和半同步复制。
It’s important to note that replication can introduce data inconsistencies and it’s important to design the system in a way that these are minimized and also to have a strategy for handling replication failures.
请务必注意,复制可能会引入数据不一致,因此必须以最小化这些不一致的方式设计系统,并制定处理复制失败的策略。
Final Thoughts 结语
You may feel like you are drinking from a firehouse, and that’s ok! As a software engineer, you are not expected to know everything right now. This article is just an overview of the most common topics related to system design.
你可能会觉得你在消防站喝水,这没关系!作为一名软件工程师,你现在不需要知道一切。本文只是与系统设计相关的最常见主题的概述。
I plan on making more articles related to this. Any feedback is appreciated so I can provide more value to you.
我计划制作更多与此相关的文章。任何反馈都值得赞赏,这样我就可以为您提供更多价值。
Thanks for reading! 感谢您的阅读!
Author:Christopher Clemmons 克里斯托弗·克莱蒙斯
From:https://medium.com/nerd-for-tech/understanding-system-design-like-a-senior-engineer-dc33b864e263



文章评论