I/O多路复用(multiplexing)的本质是通过一种机制(系统内核缓冲I/O数据),让单个进程可以监视多个文件描述符,一旦某个描述符就绪(一般是读就绪或写就绪),能够通知程序进行相应的读写操作。

01
select
int select (int n, fd_set *readfds, fd_set *writefds,fd_set *exceptfds, struct timeval *timeout);// fd_set 结构体简化为:typedef struct{long int fds_bits[32];}fd_set;
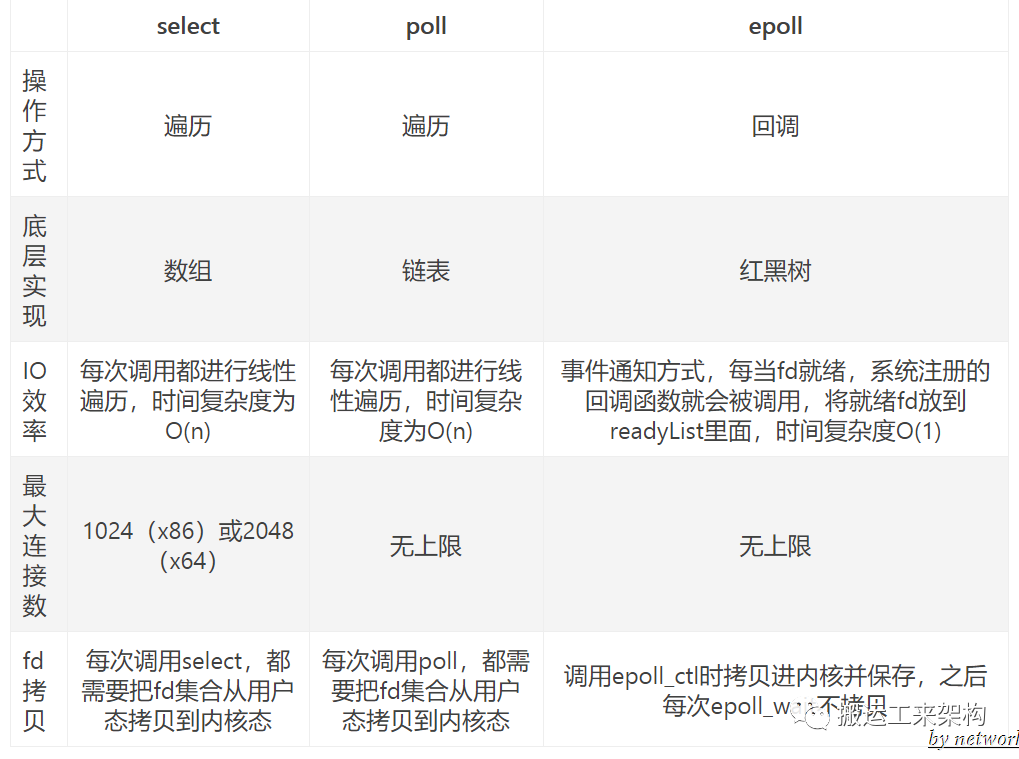
select 函数监视的文件描述符分3类,分别是writefds、readfds、和exceptfds。调用后select函数会阻塞,直到有描述符就绪(有数据 可读、可写、或者有except),或者超时(timeout指定等待时间,如果立即返回设为null即可),函数返回。当select函数返回后,可以通过遍历fdset,来找到就绪的描述符。
select本质上是通过设置或者检查存放fd标志位的数据结构来进行下一步处理。
缺点:
1、 单个进程可监视的fd数量被限制,即能监听端口的大小有限。
一般来说这个数目和系统内存关系很大,具体数目可以cat /proc/sys/fs/file-max察看。32位机默认是1024个。64位机默认是2048.
2、 对socket进行扫描时是线性扫描,即采用轮询的方法,效率较低:
当套接字比较多的时候,每次select()都要通过遍历FD_SETSIZE个Socket来完成调度,不管哪个Socket是活跃的,都遍历一遍。这会浪费很多CPU时间。如果能给套接字注册某个回调函数,当他们活跃时,自动完成相关操作,那就避免了轮询,这正是epoll与kqueue做的。
3、需要维护一个用来存放大量fd的数据结构,每次调用select时把fd集合从用户态拷贝到内核态,这样会使得用户空间和内核空间在传递该结构时复制开销大。
02
poll
int poll (struct pollfd *fds, unsigned int nfds, int timeout);struct pollfd {int fd; /* file descriptor */short events; /* requested events to watch */ // 请求监视的事件short revents; /* returned events witnessed */ // 返回发生的事件};
1、大量的fd的数组被整体复制于用户态和内核地址空间之间,而不管这样的复制是不是有意义。
2、poll还有一个特点是“水平触发”,如果报告了fd后,没有被处理,那么下次poll时会再次报告该fd。
LT模式:level trigger。当epoll_wait检测到描述符事件发生并将此事件通知应用程序,
应用程序可以不立即处理该事件。下次调用epoll_wait时,会再次响应应用程序并通知此事件。
ET模式:edge trigger。当epoll_wait检测到描述符事件发生并将此事件通知应用程序,
应用程序必须立即处理该事件。如果不处理,下次调用epoll_wait时,不会再次响应应用程序并通知此事件。
03
epoll
int epoll_create(int size);int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
epoll_create:创建一个epoll的句柄,size用来告诉内核这个监听的数目一共有多大。参数size并不是限制了epoll所能监听的描述符最大个数,只是对内核初始分配内部数据结构的一个建议。
epoll_ctl:对指定描述符fd执行op操作。
-epfd:是epoll_create()的返回值。
-op操作:对应宏:添加EPOLL_CTL_ADD,删除EPOLL_CTL_DEL,修改EPOLL_CTL_MOD,对应添加、删除和修改对fd的监听事件。
- fd:是需要监听的fd(文件描述符)。
- epoll_event:是告诉内核需要监听什么事件(读、写事件等)。
epoll_wait:等待epfd上的io事件,最多返回maxevents个事件。
-events:用来从内核得到事件的集合,
-maxevents:告之内核这个events有多大,这个maxevents的值不能大于创建epoll_create()时的size,
-timeout:是超时时间。
epoll有EPOLLLT和EPOLLET两种触发模式,LT是默认的模式,ET是“高速”模式。LT模式下,只要这个fd还有数据可读,每次 epoll_wait都会返回它的事件,提醒用户程序去操作,而在ET(边缘触发)模式中,它只会提示一次,直到下次再有数据流入之前都不会再提示了,无论fd中是否还有数据可读。所以在ET模式下,read一个fd的时候一定要把它的buffer读光,也就是说一直读到read的返回值小于请求值,或者遇到EAGAIN错误。还有一个特点是,epoll使用“事件”的就绪通知方式,通过epoll_ctl注册fd,一旦该fd就绪,内核就会采用类似callback的回调机制来激活该fd,epoll_wait便可以收到通知。
epoll为什么要有EPOLLET触发模式?
1、没有最大并发连接的限制,能打开的FD的上限远大于1024(1G的内存上能监听约10万个端口);
2、效率提升,不是轮询的方式,不会随着FD数目的增加效率下降。只有活跃可用的FD才会调用callback函数;
即Epoll最大的优点就在于它只管你“活跃”的连接,而跟连接总数无关,因此在实际的网络环境中,Epoll的效率就会远远高于select和poll。
3、 内存拷贝,利用mmap()文件映射内存加速与内核空间的消息传递;即epoll使用mmap减少复制开销。
04
区别
历史背景:
1)select出现是1984年在BSD里面实现的。
2)14年之后也就是1997年才实现了poll,其实拖那么久也不是效率问题, 而是那个时代的硬件实在太弱,一台服务器处理1千多个链接简直就是神一样的存在了,select很长段时间已经满足需求 。
3)2002, 大神 Davide Libenzi 实现了epoll。
参考资料:
https://www.cnblogs.com/Anker/p/3265058.html
https://www.cnblogs.com/aspirant/p/9166944.html
https://www.cnblogs.com/dhcn/p/12731883.html
笔记系列
笔记 | 面试官问我高并发的问题:并发编程的三大挑战
3、Kafka面试题!掌握它才说明你真正懂Kafka
4、Netty 5.0为啥被舍弃?原因竟然是...
5、中台之上——业务架构系列【汇总】

-关注搬运工来架构,与优秀的你一同进步-
原创不易,如果喜欢这篇文章可以点在看哦↘
本文仅供学习!所有权归属原作者。侵删!文章来源: 搬运工来架构



文章评论