# Scanning the entire keyspace to find biggest keys as well as
# average sizes per key type. You can use -i 0.01 to sleep 0.01 sec
# per SCAN command (not usually needed).
-------- 第一部分start -------
[00.00%] Biggest string found so far 'key-419' with 3 bytes
[05.14%] Biggest list found so far 'mylist' with 100004 items
[35.77%] Biggest string found so far 'counter:__rand_int__' with 6 bytes
[73.91%] Biggest hash found so far 'myobject' with 3 fields
-------- 第一部分end -------
-------- summary -------
-------- 第二部分start -------
Sampled 506 keys in the keyspace!
Total key length in bytes is 3452(avg len 6.82)
Biggest string found 'counter:__rand_int__' has 6 bytes
Biggest list found 'mylist' has 100004 items
Biggest hash found 'myobject' has 3 fields
-------- 第二部分end -------
-------- 第三部分start -------
504 strings with 1403bytes(99.60% of keys, avg size 2.78)
1 lists with 100004items(00.20% of keys, avg size 100004.00)
0 sets with 0members(00.00% of keys, avg size 0.00)
1 hashs with 3fields(00.20% of keys, avg size 3.00)
0 zsets with 0members(00.00% of keys, avg size 0.00)
-------- 第三部分end -------
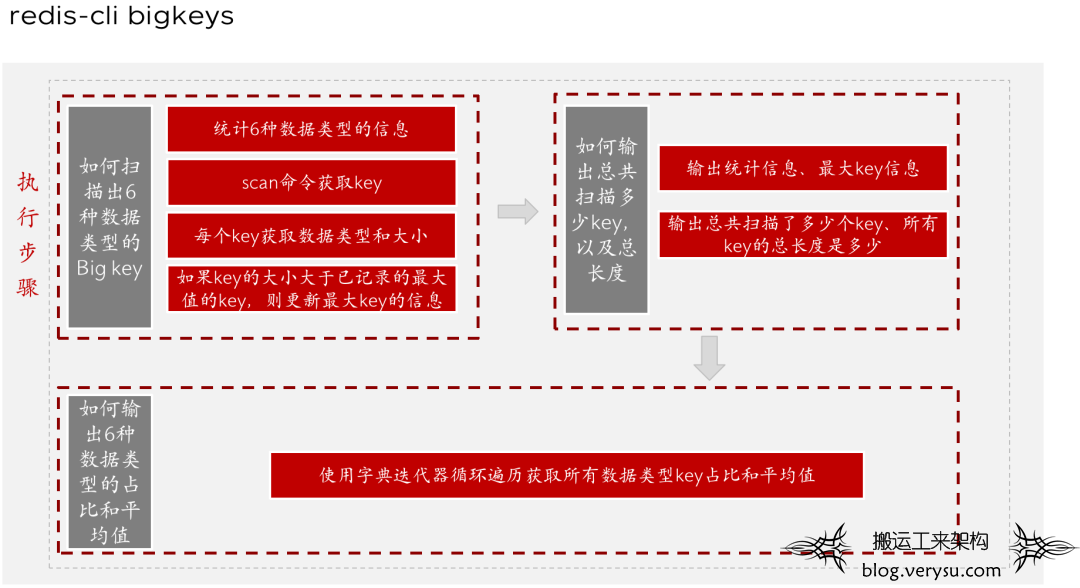
$ redis-cli --bigkeys
# Scanning the entire keyspace to find biggest keys as well as
# average sizes per key type. You can use -i 0.01 to sleep 0.01 sec
# per SCAN command (not usually needed).
-------- 第一部分start -------
[00.00%] Biggest string found so far 'key-419' with 3 bytes
[05.14%] Biggest list found so far 'mylist' with 100004 items
[35.77%] Biggest string found so far 'counter:__rand_int__' with 6 bytes
[73.91%] Biggest hash found so far 'myobject' with 3 fields
-------- 第一部分end -------
-------- summary -------
-------- 第二部分start -------
Sampled 506 keys in the keyspace!
Total key length in bytes is 3452 (avg len 6.82)
Biggest string found 'counter:__rand_int__' has 6 bytes
Biggest list found 'mylist' has 100004 items
Biggest hash found 'myobject' has 3 fields
-------- 第二部分end -------
-------- 第三部分start -------
504 strings with 1403 bytes (99.60% of keys, avg size 2.78)
1 lists with 100004 items (00.20% of keys, avg size 100004.00)
0 sets with 0 members (00.00% of keys, avg size 0.00)
1 hashs with 3 fields (00.20% of keys, avg size 3.00)
0 zsets with 0 members (00.00% of keys, avg size 0.00)
-------- 第三部分end -------
$ redis-cli --bigkeys
# Scanning the entire keyspace to find biggest keys as well as
# average sizes per key type. You can use -i 0.01 to sleep 0.01 sec
# per SCAN command (not usually needed).
-------- 第一部分start -------
[00.00%] Biggest string found so far 'key-419' with 3 bytes
[05.14%] Biggest list found so far 'mylist' with 100004 items
[35.77%] Biggest string found so far 'counter:__rand_int__' with 6 bytes
[73.91%] Biggest hash found so far 'myobject' with 3 fields
-------- 第一部分end -------
-------- summary -------
-------- 第二部分start -------
Sampled 506 keys in the keyspace!
Total key length in bytes is 3452 (avg len 6.82)
Biggest string found 'counter:__rand_int__' has 6 bytes
Biggest list found 'mylist' has 100004 items
Biggest hash found 'myobject' has 3 fields
-------- 第二部分end -------
-------- 第三部分start -------
504 strings with 1403 bytes (99.60% of keys, avg size 2.78)
1 lists with 100004 items (00.20% of keys, avg size 100004.00)
0 sets with 0 members (00.00% of keys, avg size 0.00)
1 hashs with 3 fields (00.20% of keys, avg size 3.00)
0 zsets with 0 members (00.00% of keys, avg size 0.00)
-------- 第三部分end -------
fprintf(stderr, "Failed to allocate memory for key!n");
exit(1);
}
//每当找到一个更大的key时则输出该key信息
printf(
"[%05.2f%%] Biggest %-6s found so far '%s' with %llu %sn",
pct, type->name, type->biggest_key, sizes[i],
!memkeys? type->sizeunit: "bytes");
/* Keep track of the biggest size for this type */
//更新最大key的大小
type->biggest = sizes[i];
}
......//前面已解析
}
/* Now update our stats */
for(i=0;i<keys->elements;i++) {
......//前面已解析
//如果遍历到比记录值更大的key时
if(type->biggest<sizes[i]) {
/* Keep track of biggest key name for this type */
if (type->biggest_key)
sdsfree(type->biggest_key);
//更新最大key的键名
type->biggest_key = sdscatrepr(sdsempty(), keys->element[i]->str, keys->element[i]->len);
if(!type->biggest_key) {
fprintf(stderr, "Failed to allocate memory for key!n");
exit(1);
}
//每当找到一个更大的key时则输出该key信息
printf(
"[%05.2f%%] Biggest %-6s found so far '%s' with %llu %sn",
pct, type->name, type->biggest_key, sizes[i],
!memkeys? type->sizeunit: "bytes");
/* Keep track of the biggest size for this type */
//更新最大key的大小
type->biggest = sizes[i];
}
......//前面已解析
}
/* Now update our stats */
for(i=0;i<keys->elements;i++) {
......//前面已解析
//如果遍历到比记录值更大的key时
if(type->biggest<sizes[i]) {
/* Keep track of biggest key name for this type */
if (type->biggest_key)
sdsfree(type->biggest_key);
//更新最大key的键名
type->biggest_key = sdscatrepr(sdsempty(), keys->element[i]->str, keys->element[i]->len);
if(!type->biggest_key) {
fprintf(stderr, "Failed to allocate memory for key!n");
exit(1);
}
//每当找到一个更大的key时则输出该key信息
printf(
"[%05.2f%%] Biggest %-6s found so far '%s' with %llu %sn",
pct, type->name, type->biggest_key, sizes[i],
!memkeys? type->sizeunit: "bytes");
/* Keep track of the biggest size for this type */
//更新最大key的大小
type->biggest = sizes[i];
}
......//前面已解析
}
/* Output the biggest keys we found, for types we did find */
di = dictGetIterator(types_dict);
while ((de = dictNext(di))) {
typeinfo *type = dictGetVal(de);
if(type->biggest_key) {
printf("Biggest %6s found '%s' has %llu %sn", type->name, type->biggest_key,
type->biggest, !memkeys? type->sizeunit: "bytes");
}
}
dictReleaseIterator(di);
/* Output the biggest keys we found, for types we did find */
di = dictGetIterator(types_dict);
while ((de = dictNext(di))) {
typeinfo *type = dictGetVal(de);
if(type->biggest_key) {
printf("Biggest %6s found '%s' has %llu %sn", type->name, type->biggest_key,
type->biggest, !memkeys? type->sizeunit: "bytes");
}
}
dictReleaseIterator(di);
int dbSyncDelete(redisDb *db, robj *key) {
return dbGenericDelete(db, key, 0, DB_FLAG_KEY_DELETED);
}
int dbAsyncDelete(redisDb *db, robj *key) {
return dbGenericDelete(db, key, 1, DB_FLAG_KEY_DELETED);
}
int dbGenericDelete(redisDb *db, robj *key, int async, int flags) {
dictEntry **plink;
int table;
dictEntry *de = dictTwoPhaseUnlinkFind(db->dict,key->ptr,&plink,&table);
if (de) {
robj *val = dictGetVal(de);
/* RM_StringDMA may call dbUnshareStringValue which may free val, so we need to incr to retain val */
incrRefCount(val);
/* Tells the module that the key has been unlinked from the database. */
moduleNotifyKeyUnlink(key,val,db->id,flags);
/* We want to try to unblock any module clients or clients using a blocking XREADGROUP */
signalDeletedKeyAsReady(db,key,val->type);
// 在调用用freeObjAsync之前,我们应该先调用decrRefCount。否则,引用计数可能大于1,导致freeObjAsync无法正常工作。
decrRefCount(val);
// 如果是异步删除,则会调用 freeObjAsync 异步释放 value 占用的内存。同时,将 key 对应的 value 设置为 NULL。
if (async) {
/* Because of dbUnshareStringValue, the val in de may change. */
freeObjAsync(key, dictGetVal(de), db->id);
dictSetVal(db->dict, de, NULL);
}
// 如果是集群模式,还会更新对应 slot 的相关信息
if (server.cluster_enabled) slotToKeyDelEntry(de, db);
/* Deleting an entry from the expires dict will not free the sds of the key, because it is shared with the main dictionary. */
if (dictSize(db->expires) > 0) dictDelete(db->expires,key->ptr);
// 释放内存
dictTwoPhaseUnlinkFree(db->dict,de,plink,table);
return 1;
} else {
return 0;
}
}
int dbSyncDelete(redisDb *db, robj *key) {
return dbGenericDelete(db, key, 0, DB_FLAG_KEY_DELETED);
}
int dbAsyncDelete(redisDb *db, robj *key) {
return dbGenericDelete(db, key, 1, DB_FLAG_KEY_DELETED);
}
int dbGenericDelete(redisDb *db, robj *key, int async, int flags) {
dictEntry **plink;
int table;
dictEntry *de = dictTwoPhaseUnlinkFind(db->dict,key->ptr,&plink,&table);
if (de) {
robj *val = dictGetVal(de);
/* RM_StringDMA may call dbUnshareStringValue which may free val, so we need to incr to retain val */
incrRefCount(val);
/* Tells the module that the key has been unlinked from the database. */
moduleNotifyKeyUnlink(key,val,db->id,flags);
/* We want to try to unblock any module clients or clients using a blocking XREADGROUP */
signalDeletedKeyAsReady(db,key,val->type);
// 在调用用freeObjAsync之前,我们应该先调用decrRefCount。否则,引用计数可能大于1,导致freeObjAsync无法正常工作。
decrRefCount(val);
// 如果是异步删除,则会调用 freeObjAsync 异步释放 value 占用的内存。同时,将 key 对应的 value 设置为 NULL。
if (async) {
/* Because of dbUnshareStringValue, the val in de may change. */
freeObjAsync(key, dictGetVal(de), db->id);
dictSetVal(db->dict, de, NULL);
}
// 如果是集群模式,还会更新对应 slot 的相关信息
if (server.cluster_enabled) slotToKeyDelEntry(de, db);
/* Deleting an entry from the expires dict will not free the sds of the key, because it is shared with the main dictionary. */
if (dictSize(db->expires) > 0) dictDelete(db->expires,key->ptr);
// 释放内存
dictTwoPhaseUnlinkFree(db->dict,de,plink,table);
return 1;
} else {
return 0;
}
}
如果为异步删除,调用freeObjAsync()方法,根据以下代码分析:
Plain text
Copy to clipboard
Open code in new window
EnlighterJS 3 Syntax Highlighter
#define LAZYFREE_THRESHOLD 64
/* Free an object, if the object is huge enough, free it in async way. */



文章评论