零,前言
经常排查线上紧急问题的IT老兵都知道,IT故障排查,和临床治病救人,有两个共同特征。
第一个特征,都容易“只见树木不见森林”。
综合性医院分科很细,医生专科化程度很高,常常“只见树木不见森林”。医生只知道处理专科的问题,其他方面的问题就通过转科或者会诊的方式交给其他科室。一旦遇到的是系统性、全身性疾病,这种工作模式就会导致延误诊断及治疗。
相对应的,IT团队也分为App,前端,后端,DBA(数据库管理员),SA(运维),CM(配置管理员)等细分岗位。随着系统越来越庞大,分工越来越细致,这些岗位之间也会慢慢砌起高墙,容易落入“只见树木不见森林”的境地,导致IT事故越拖越大,表征越来越复杂。

第二个特征,都容易“所见非所得”。
我们都知道,急诊科医生最怕碰到胸痛,因为仅仅是最常见、最容易快速致死的心梗、主动脉夹层、肺栓塞这三样,都会引发剧烈胸痛。虽然从医学上讲,典型的主动脉夹层胸痛感是腰背部撕裂样疼痛,或者刀割样疼痛,跟心肌梗死那种缺氧引起的类似石头或者大象压在胸口的胸痛是不大一样的,但是在急诊室里,发生不典型事件的概率可也真不小,医生往往会进一步摸排,拿到更多的数据来下判断。
IT上也是如此,单就Web服务失去响应这么一个表征,就可能是数据库出现慢查,数据库出现死锁,后端服务线程池大小配置不合理等各种原因,而不是说“加服务节点”就能扛过去的。
综上所述,临床医学诊断的方法论,非常适用于IT故障排查。下面我们简单了解一下他们的方法论。
通过阅读各种医生日志,我们了解到在临床诊断过程中,大致有如下三个原则。
第一条原则,“一元论”。
看似不相关的现象,内部可能是相互联系的,可能都是由一种疾病衍生出来的。当病患出现了多种多样的症状和体征时,医者要能联想到这可能是一个以某一种“Root Cause(根本性原因)”为中心的系统性疾病,否则头痛医头脚痛医脚,治标不治本。
第二条原则,“首先考虑常见病原则”。
同一种临床表现可以是不同疾病带来的,那么,医者首先考虑可以引起这种临床表现的最常见的疾病,作为假设诊断,然后寻找证据来支持自己的假设,这就是首先考虑常见病原则。
第三个原则,“优先排除原则”。
与上一条原则相反,上一个是优先考虑,这一个是优先排除。就像赌博一样,常见病原则是为了能让自己赢的次数多一点,优先排除原则是让自己输得少一点,两者应该结合起来灵活运用。
下面我一一展开讲讲,看这三个原则如何与IT故障排查相结合。
一,一元论
一般情况下,不管病患的临床表现有几个,比方说他同时有头疼、肚子疼、发烧等症状,都尽量用一种疾病来解释。你不能说头疼是头的诊断,肚子疼是肚子的诊断,发烧按发烧来治,而是希望用一种疾病诊断——比方说是不是某种寄生虫的多脏器表现——来最终解决问题。这就是“一元论”。
“一元论”是临床思维中最有用和最重要的一种思维方式。
看似不相关的现象其实内部可能是相互联系的,可能都是由一种疾病衍生出来的,要学会透过纷繁多样的临床表现抓住事物的本质。
一元论可以看作奥卡姆剃刀法则在临床上的一个应用,即尽量用一种病或病因来解释所观察到的临床现象。
同样,在处理IT故障的时候,如果有一种问题现象就考虑一种处理方式,有五种现象就考虑五种处理方式,那会让运维团队的判断非常混乱,更容易犯错。
我们来看一个“一元论”案例。
有一年大清早七点多,我们突然收到投诉,旗下某公司位于华北2区的某个支付通道无法支付,于是通过异地双活控制平台切换机房到华东2区,恢复了支付。然而旗下另外一家公司又报告他们业务在支付成功之后无法将通知发送给ISV。这时候才发现华北2区由内到外的所有HTTP请求都无法访问,但百度能访问。
在这种情况下,脑中立刻反应过来,这应该不是我们自己的问题,会不会是云厂商的安全中心对我们有所限制?
紧急联系云厂商技术支持,一起排查问题,发现确实是云厂商的安全中心阻断了服务器对其他服务器端口(TCP:80)的访问。

阻断的原因是,新加入公司的一个开发小组在他们自己的服务器上私自搭建了Jenkins(一个构建发布工具),因为这个工具有高危漏洞,被外网的挖矿病毒扫描到,从而植入了矿机程序。云厂商安全中心探测到了它的非正常联网行为后,阻断了外网出口访问。问题是云厂商阻断我们的出口后并没有及时短信、语音或钉钉通知到我们。所以,这才是“病根”。
当然,一元论只是建议用在排查工作中的常用思路,不是说遵循了这条原则就一定是对的,只是说,遵循了这样的原则,犯错的机会可能会小一点。
我们有句古语叫“屋漏偏逢连阴雨”,谁说得了一种病就不能再得另一种。
二,首先考虑常见病原则
这个原则的原理很简单,同样的临床表现,A疾病的发病率为70%,B疾病的发病率为40%,C疾病的发病率为10%,那么首先考虑A疾病是明智的选择,因为有七成的可能性。
《实习医生格蕾》里就有这么一句:“如果听到马蹄声,首先要想到的是马,而不是斑马。”这里的斑马就代表着一种非常特殊的情况。当医者面对一系列临床表现的时候(听到马蹄声),首先应该考虑引发这些表现的最常见疾病(普通的马),而不是某些特殊情况(斑马)。遵循这条原则,你不仅仅赌赢的概率大,而且还能节省时间。
我曾介绍过我们处理核心业务高级别故障时的口诀:
遇事不乱,分头核查,群里同步,简单陈述,绝不恋战,恢复服务。
其中遇事不乱、分头核查就是这么一个步骤:
1)接到投诉后先确认问题现象是否存在——与此同时一号位简短综述,第一时间同步线上问题群=>
2)快速分派人手,分头确认系统情况,从“常见病”角度,DBA查数据库有没有慢查、连接有没有打满,SA查系统入口和出口流量带宽、查连接数,QA查近期做了哪些变更等等——与此同时,不断简短综述,不断发布,让核心人员快速了解哪些嫌疑被排除了=>
3)快速确认处理方法=>
4)确认恢复=>
5)恢复后排查原因,整理证据链=>
6)RCA报告
你可以发现,在第二步里就是要从最常见的原因逐个排除,这就是“首先考虑常见病原则”。
三,优先排除原则
常见病原则的好处在于可以使赌徒们的赢面更大一点,而在临床诊断中,优先考虑排除预后不良和对健康有显著影响、可致死致残的疾病,则是尽可能地让赌徒们不至于输得太惨。
这个原则被应用最多的,可能就是在恶性肿瘤的诊断中了。优先考虑排除的诊断,医者不考虑它的发病率,只关心结局,只要结局足够糟糕,就应该把它放在待排疾病的第一序列。比如反复饭后恶心呕吐,可能就是一个消化不良,但是医者应该想到先排除胃癌的可能性。
我们先来看一个具体案例。
有一年上午十点多,钉钉群里开始零星报警不断,但是没有触发短信报警。此时通过业务保障平台查看超时请求的调用链路,基本上都是调用第三方API超时引起的。
再过了一会儿,不仅仅云端问题越来越严重,公司的网络还断了,要命,运维说电信DNS有问题(可惜,在这一步如果反应过来了,就能节省很多排查时间),切了DNS,隔了一会儿公司网络恢复了。
DBA说云端数据库没问题,运维说云端网络没问题,怀疑是工程问题,问昨天有没有上线,毕竟这是最大可能性。
想不出来什么原因,于是紧急通过异地双活控制平台把有问题的华北2区机房流量切换到华东2区,先容我们缓口气。
这时候已经十一点多了,事故持续了一个小时了。这个时候突然想起来,诶,刚才不是说电信DNS有问题吗,具体是什么问题?回答说是电信DNS 114.114.114.114以及谷歌DNS 8.8.8.8 都访问不了……
赶紧上微博搜索,发现各地都在说电信DNS挂了。
原来,电信DNS 114.114.114.114 和谷歌DNS 8.8.8.8 好巧不巧竟然在当年4月4日上午全挂了,全国各地用户、客户和友商都受了影响。
刚好,我们华北2区机房的DNS配置顺序是:
而华东2区机房的DNS优先级则为:
所以,好巧不巧,华北2区出问题后,把流量切到华东2区后,关二爷保佑,阿里DNS起了作用,业务还能跑~

按照首先考虑常见病原则,平常的话我们确实应该先确认数据库有没有做过变更、有没有问题,机房网络环境有没有做过变更、有没有问题,工程有没有做过变更,但按照优先排除原则,如果在公司网络一度断掉的时候,我们优先去排除后果可怕的DNS服务故障,可能提前一个小时就收兵了。
以上就是临床治疗三原则在IT领域的具体应用,一元论、首先考虑常见病原则、优先排除原则,他山之石,可以攻玉,百家之长,可以厚己。
昀哥最后更新时间:2024年3月30日
关键词:事故,故障,BUG,破案,排查
额外赠送一枚:
1、
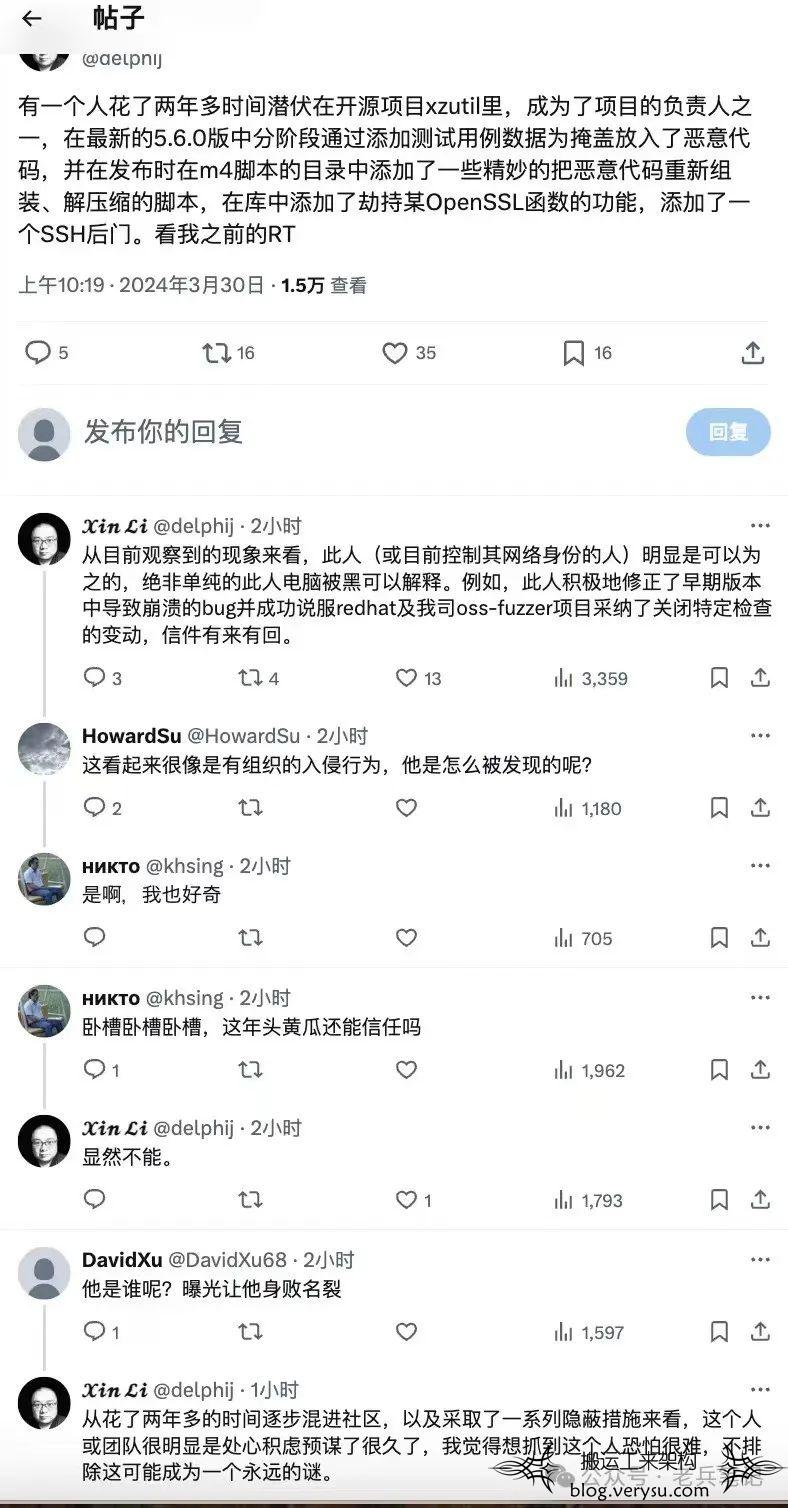
默认安装于每个Linux发行版中的XZ Utils被有心人植入后门程序,这是又一起混淆恶意代码的供应链攻击。有点像当年的 XcodeGhost 事件和XShellGhost 事件,都是谋划多时投毒植入。
本文仅供学习!所有权归属原作者。侵删!文章来源: 老兵笔记 -昀哥 :http://mp.weixin.qq.com/s?__biz=MzA4ODM0OTc0NQ==&mid=2650915928&idx=1&sn=beddfa00109991049596a710d2ddcaf4&chksm=8a9484e4aa18a417db5c45dc79fd1abf2ea4fb0c19c35492d7e4ea2b3821f423feb94563585b



文章评论