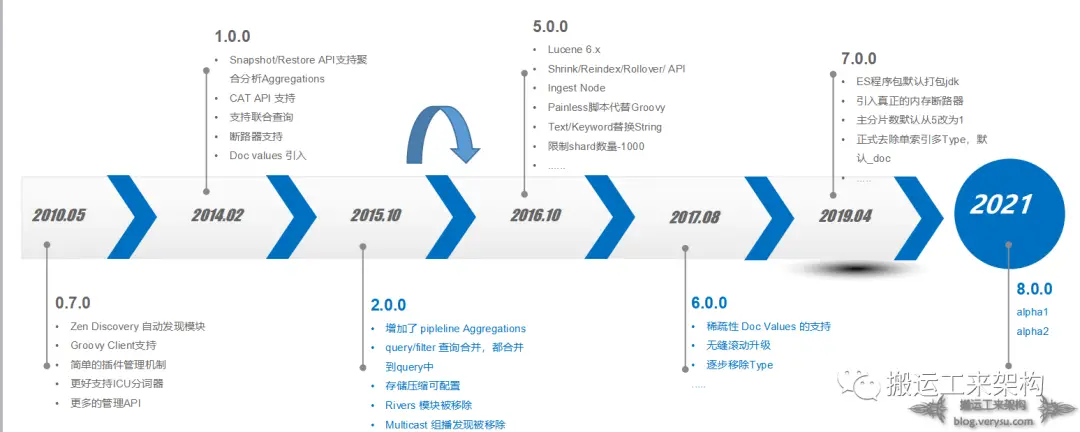
ES各大版本演进时间线:
视频版的可以移步B站同号——点击左下角 “阅读原文” 直达。
初始版本 0.7.0
2010年5月14日-
Zen Discovery 自动发现模块
-
Groovy Client支持
-
简单的插件管理机制
-
更好支持ICU分词器
-
更多的管理API
icu_分词器 和 标准分词器 使用同样的 Unicode 文本分段算法, 只是为了更好的支持亚洲语,添加了泰语、老挝语、中文、日文、和韩文基于词典的词汇识别方法,并且可以使用自定义规则将缅甸语和柬埔寨语文本拆分成音节。
1.0.0
2014年2月14日-
Snapshot/Restore API 备份恢复API
-
支持聚合分析Aggregations
-
CAT API 支持
-
支持联合查询
-
断路器支持
断熔器通过内部检查(字段的类型、基数、大小等等)来估算一个查询需要的内存。如果估算查询的大小超出限制,就会 触发 断路器,查询会被中止并返回异常。可防止OOM异常等。
-
Doc Values 引入
Doc Values本质上是一个序列化了的列式存储结构,非常适合排序、聚合以及字段相关的脚本操作。而且这种存储方式便于压缩,尤其是数字类型。压缩后能够大大减少磁盘空间,提升访问速度。默认每个字段 都是开启的,Doc Values是在索引时创建,当字段索引时会把字段的值加入到倒排索引并且会存储该字段的Doc Values。场景:对字段进行排序、聚合、过滤(地理位置过滤)、脚本计算等。作用:提升效率,防止JVM堆内存溢出异常。
2.0.0
2015年10月28日-
增加了 pipleline Aggregations
-
query/filter 查询合并,都合并到query中,根据不同的上下文执行不同的查询
-
存储压缩可配置
-
Rivers 模块被移除
river代表es的一个数据源,也是其它存储方式(如:数据库)同步数据到es的一个方法。它是以插件方式存在的一个es服务,通过读取river中的数据并把它索引到es中,官方的river有couchDB的,RabbitMQ的,Twitter的,Wikipedia的。由于Rivers会造成集群的不稳定。Rivers处理外部系统,而这些外部系统需要外部库来处理。这些工具使用起来很好,但是会带来一定的开销。它的一部分是建立在开销上的,比如额外的内存使用量、更多的套接字、文件描述符等等。遗憾的是,还有一些是bug。
-
Multicast 组播发现成为组件
成为一个插件,生产环境必须配置单播地址。组播发现有很多缺点,当elasticsearch集群规模较大的时候,组播的发现机制会产生太多不必要的流量开销,不属于当前集群的es节点会错误的加入集群中,当网络环境发生变动的时候,组播的发现机制也会变得不可靠,从elasticsearch 5.0开始,elasticsearch已经移除了对组播的支持。但是elasticsearch可以发现位于同一台机器上的实例,并和相同的cluster.name名字组成集群
5.0.0
2016年10月26日-
Lucene 6.x 的支持,磁盘空间少一半;索引时间少一半;查询性能提升25%;支持IPV6。
-
Internal engine级别移除了用于避免同一文档并发更新的竞争锁,带来15%-20%的性能提升
-
Shrink API
它可将分片数进行收缩成它的因数,如之前你是15个分片,你可以收缩成5个或者3个又或者1个,那么我们就可以想象成这样一种场景,在写入压力非常大的收集阶段,设置足够多的索引,充分利用shard的并行写能力,索引写完之后收缩成更少的shard,提高查询性能
-
新增Ingest Node
之前如果需要对数据进行加工,都是在索引之前进行处理,比如logstash可以对日志进行结构化和转换,现在直接在es就可以处理了。数据前置处理转换的节点,支持 pipeline管道 设置,可以使用 ingest 对数据进行过滤、转换等操作,类似于 logstash 中 filter 的作用,功能相当强大。
-
提供 Painless 脚本,代替Groovy脚本
-
移除 site plugins
就是说 head 、 bigdesk 都不能直接装 es 里面了,不过可以部署独立站点(反正都是静态文件)或开发 kibana 插件
-
新增 Sliced Scroll类型
现在Scroll接口可以并发来进行数据遍历了。每个Scroll请求,可以分成多个Slice请求,可以理解为切片,各Slice独立并行,利用Scroll重建或者遍历要快很多倍。
-
新增Profile API
性能执行情况
-
新增Rollover API
索引被认为太大或太旧时,滚动索引API 会将别名滚动到新的索引
-
新增Reindex API
将一个索引的数据复制到另一个已存在的索引,但是并不会复制原索引的mapping(映射)、shard(分片)、replicas(副本)等配置信息
-
提供了第一个Java原生的REST客户端SDK
基于HTTP协议的客户端对Elasticsearch的依赖解耦,没有jar包冲突,提供了集群节点自动发现、日志处理、节点请求失败自动进行请求轮询,充分发挥Elasticsearch的高可用能力
-
引入新的字段类型 Text/Keyword 来替换 String
-
限制索引请求大小,避免大量并发请求压垮 ES
-
限制单个请求的 shards 数量,默认 1000 个
6.0.0
2017年8月31日-
稀疏性 Doc Values 的支持
稀疏性指一个索引里面,文档的结构其实是多样性的,但是郁闷的是只要一个文档有这个字段,其他所有的文档尽管没有这个字段,可也都要承担这个字段的开销,所以会存在磁盘空间的浪费,而这块的改进就是这个问题。
-
Index sorting,即索引阶段的排序。
即在索引阶段的排序,即我们查询的时候有时候会根据某个字段的值进行排序,比如时间、编号等等,如果在索引的时候提取排好序,那么搜索或聚合的时候就会非常快,相应的直接走预先排序好的索引就行了。当然索引的时候会要增加额外开销,适合不怎么变化的索引的场景。
-
顺序号的支持
每个 es 的操作都有一个顺序编号(类似增量设计),这个属于 es 内部的一个功能,可以提供:快速的分片副本恢复或同步;跨数据中心的节点恢复;甚至提供一个 Changes API 等等;
-
无缝滚动升级
使之能够从 5 的最后一个版本滚动升级到 6 的最后一个版本,不需要集群的完整重启。无缝滚动升级,也就是不用停服务,在线升级
-
逐步移除Type
在 6.0 里面,开始不支持一个 index 里面存在多个 type
-
Index-template inheritance
索引版本的继承,目前索引模板是所有匹配的都会合并,这样会造成索引模板有一些冲突问题, 6.0 将会只匹配一个,索引创建时也会进行验证
-
Load aware shard routing
基于负载的请求路由,目前的搜索请求是全节点轮询,那么性能最慢的节点往往会造成整体的延迟增加,新的实现方式将基于队列的耗费时间自动调节队列长度,负载高的节点的队列长度将减少,让其他节点分摊更多的压力,搜索和索引都将基于这种机制。
-
已经关闭的索引将也支持 replica 的自动处理,确保数据可靠。
7.0.0
2019年4月10日-
集群连接变化:TransportClient被废弃 以至于,es7的java代码,只能使用restclient。然后,个人综合了一下,对于java编程,建议采用 High-level-rest-client 的方式操作ES集群
-
ES程序包默认打包jdk:以至于7.x版本的程序包大小突然变300MB+ 对比6.x发现,包大了200MB+, 正是JDK的大小
-
重大改进-正式废除单个索引下多Type的支持 es6时,官方就提到了es7会删除type,并且es6时已经规定每一个index只能有一个type。在es7中使用默认的_doc作为type,官方说在8.x版本会彻底移除type。api请求方式也发送变化,如获得某索引的某ID的文档:GET index/_doc/id其中index和id为具体的值
-
7.1开始,Security功能免费使用
-
ECK-ElasticSearch Operator on Kubernetes
-
引入了真正的内存断路器
它可以更精准地检测出无法处理的请求,并防止它们使单个节点不稳定
-
Zen2 是 Elasticsearch 的全新集群协调层,提高了可靠性、性能和用户体验,变得更快、更安全,并更易于使用
-
新功能
-
New Cluster coordination
-
Feature - Complete High Level REST Client
-
Script Score Query
-
性能优化
-
Weak-AND算法提高查询性能
-
默认的Primary Shared数从5改为1,避免Over Sharding
-
更快的前 k 个查询
-
间隔查询(Intervals queries) 某些搜索用例(例如,法律和专利搜索)引入了查找单词或短语彼此相距一定距离的记录的需要。Elasticsearch 7.0中的间隔查询引入了一种构建此类查询的全新方式,与之前的方法(跨度查询span queries)相比,使用和定义更加简单。与跨度查询相比,间隔查询对边缘情况的适应性更强。
8.0.0
alhpa1 August 11, 2021
alpha2 September 17, 2021PS:以上各大版本罗列内容只是冰山一角,具体内容可以去官网了解。
参考资料
Elasticsearch各版本升级核心内容必看ttps://www.cnblogs.com/flyrock/p/11614396.html
Elasticsearch各版本及其下载地址 https://www.elastic.co/cn/downloads/past-releases#elasticsearch
Doc Values介绍 https://www.elastic.co/guide/cn/elasticsearch/guide/current/docvalues-intro.html
Deprecating Rivers https://www.elastic.co/cn/blog/deprecating-rivers
Elasticsearch之elasticsearch5.x 新特性 https://www.cnblogs.com/zlslch/p/6619089.html
Elasticsearch2.x Breaking changes https://blog.csdn.net/chennanymy/article/details/52562993
Elasticsearch5.0 BreakChange摘要 https://blog.csdn.net/weixin_30920513/article/details/99312266
Elasticsearch 6.x版本重大改变(Breaking changes in 6.x)https://blog.csdn.net/weixin_43249121/article/details/108584146
Elasticsearch 7.x版本重大改变(Breaking changes in 7.x)https://blog.csdn.net/weixin_43249121/article/details/108641958
4、Netty 5.0为啥被舍弃?原因竟然是...
5、中台之上——业务架构系列【汇总】

-关注搬运工来架构,与优秀的你一同进步-
如果喜欢这篇文章可以点在看哦↘



文章评论