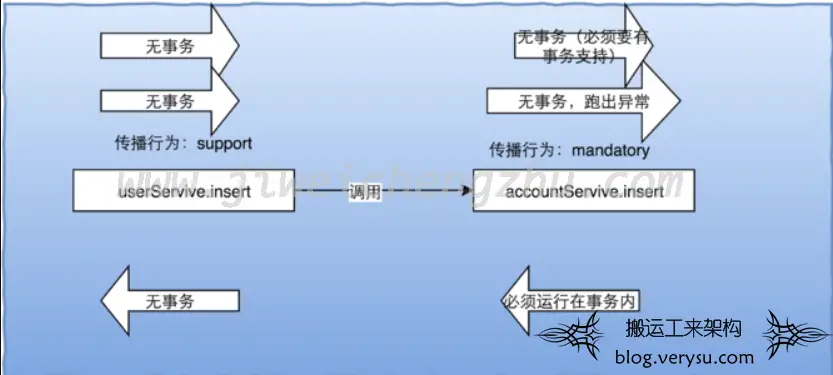
上一篇文章中见过了事务的特性以及隔离级别,今天来说一下事务的传播性,事务是一个好东西,但是并不是每一个方法都应该加上事务,在事务的隔离级别中提到过一点:越是严格,耗费的性能越大,那么如果每个方法都加了事务,而不论是否会涉及到数据的修改,那么这就属于事务的滥用了,没起到应有的作用不说,反而还会一点点的拖慢你的系统。 为了应对这一问题,“事务的传播性”这一概念又横空出世了,打个 […]
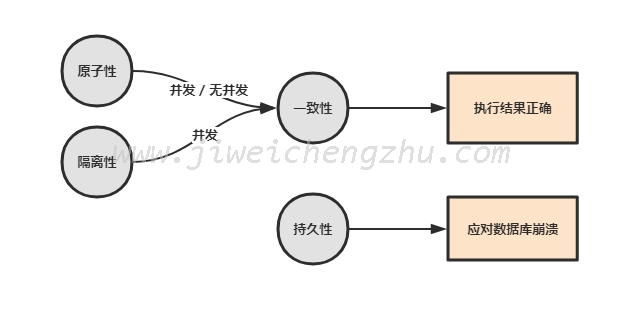
“事务”,一个经常能听到的概念,它到底是个什么东西呢?数据库管理系统执行过程中的一个逻辑单位,由一个有限的数据库操作序列构成,事务的正确执行,使得数据从一种状态转换到另外一种状态。
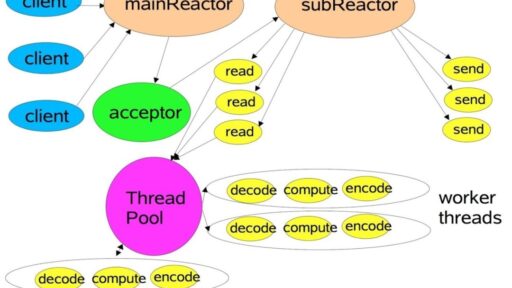
本文基于Netty4.1展开介绍相关理论模型,使用场景,基本组件、整体架构,知其然且知其所以然,希望给大家在实际开发实践、学习开源项目提供参考。这是一篇万字长文,建议先收藏,转发后再看。 Netty简介 Netty是 一个异步事件驱动的网络应用程序框架,用于快速开发可维护的高性能协议服务器和客户端。 JDK原生NIO程序的问题 JDK原生也有一套网络应用程序API,但是存在 […]

前言 今天想跟大家分享一个关于“状态机”的话题。状态属性在我们的现实生活中无处不在。比如电商场景会有一系列的订单状态(待支付、待发货、已发货、超时、关闭);员工提交请假申请会有申请状态(已申请、审核中、审核成功、审核拒绝、结束);差旅报销单会有单据审核状态(已提交、审核中、审核成功、退回、打款中、打款成功、打款失败、结束)等等。 上述场景有一个共同问题:根据不同触发条件执行 […]

一、背景 在京东到家购物车系统中,用户基于门店能够对商品进行加车操作。用户与门店商品使用Redis的Hash类型存储,如下代码块所示。不知细心的你有没有发现,如果单门店加车商品过多,或者门店过多时,此Key就会越来越大,从而影响线上业务。 userPin:{ storeId:{门店下加车的所有商品基本信息}, storeId:{门店下加车的所有商品基本信息}, ... […]

前言 本文是京东交易链路众多核心应用GC优化经验的总结,旨在简明扼要说明各种回收器的基本调优设置,为各应用GC配置提供指引。 一、JDK版本 以下所有优化全部基于JDK8版本,强烈建议低版本升级到JDK8,并尽可能使用update_191以后版本。 二、如何选择垃圾回收器 响应优先应用:面向C端对响应时间敏感的应用,堆内存8G以上建议选择G1,堆内存较小或低版本JDK选择C […]
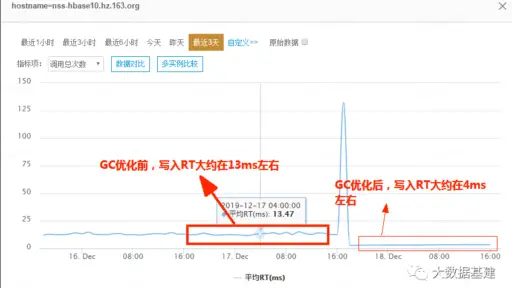
考虑CMS无法有效避免FGC,且单次GC耗时经常不可控。因此在如下两种场景下倾向于使用G1替换CMS: 大堆系统长时间FGC会引起上层服务异常,比如RegionServer/HiveServer等。 对读写毛刺比较敏感的在线数据库服务,比如在线推荐场景下的HBase,GC耗时过长就会导致整体可用率降低。 笔者在2019年开始将集团内部多数HBase所用CMS升级到G1,升级 […]

一、问题回顾 1.1 问题描述 在项目的性能测试中,相关的接口的随着并发数增加,接口的响应时间变长,接口吞吐不再增长,应用的CPU使用率较高。 1.2 分析思路 谁导致的CPU较高,阻塞接口TPS的增长?接口的响应时间的调用链分布是什么样的,有没有慢的点? 1)使用火焰图分析应用的CPU如下,其中log4j2日志占了40%左右CPU,初步怀疑是log4j2的问题。 2)调用 […]
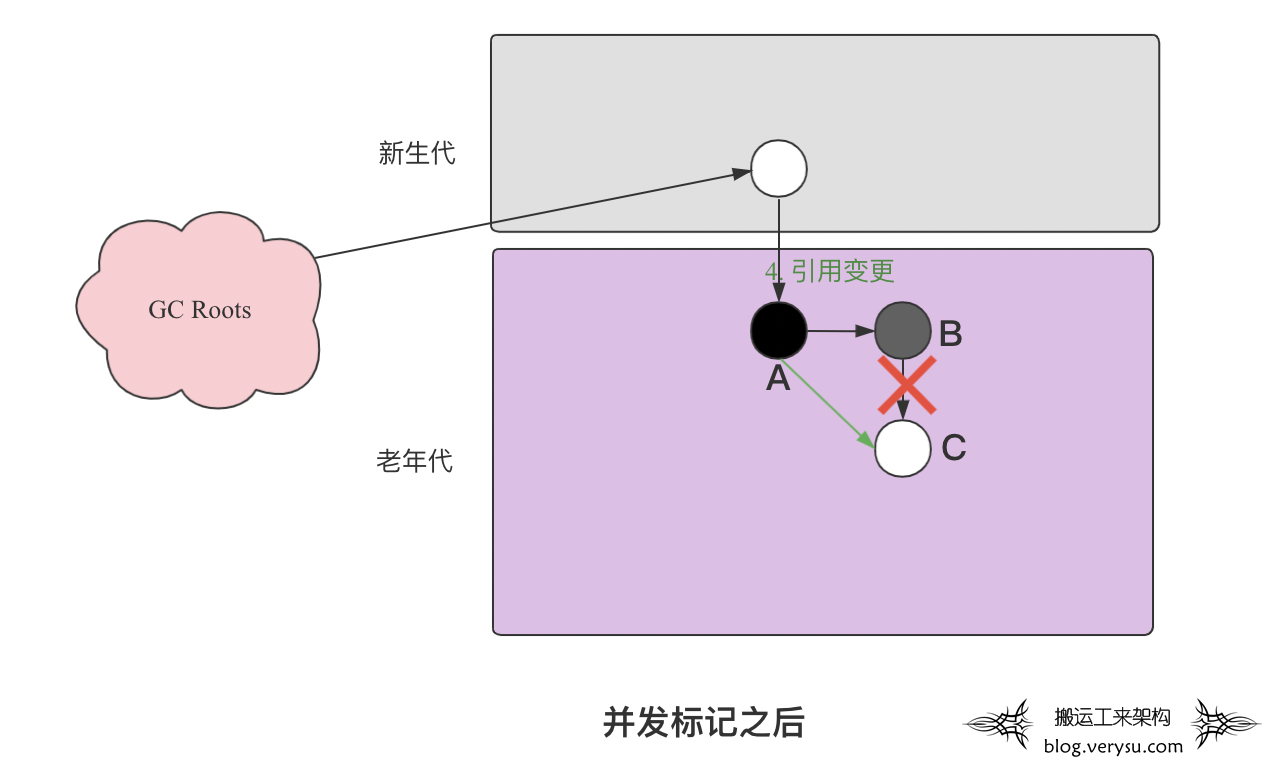
一. 背景介绍 笔者在这个系列的第一篇文章《一文看懂”ParNew+CMS”垃圾回收器》中详细介绍了”ParNew+CMS”垃圾回收器的工作原理。文章最后笔者提到CMS垃圾回收器有两个比较显著的问题,一个是长时间运行无法避免Full GC,一个是Remark阶段STW时间较长。正是因为这两个问题的存在,CMS垃圾回收器在JDK9被标记弃用,慢慢开始退出历史舞台。有走的,就有 […]
这是”大内存服务GC实践”的第三篇文章,前面两篇文章分别系统地介绍了”ParNew+CMS”组合垃圾回收器的原理以及FullGC的一些排查思路。分别见: 【大内存服务GC实践】- 一文看懂”ParNew+CMS”垃圾回收器 【大内存服务GC实践】- “ParNew+CMS”实践案例 : HiveMetastore FullGC诊断优化 本篇文章重点结合生产线上NameNod […]
Metastore服务是Hive的核心组成部分,是整个hadoop大数据体系的元数据基石,所有数据表相关schema信息、partition信息、元数据统计信息等都存储在Metastore所依赖的MySQL中,通过Metastore服务执行各种元数据操作。Metastore服务一旦长时间异常,所有依赖服务(诸如HiveServer、Spark、Impala等)就都会出现功能 […]
因为工作的需要,笔者前前后后分别接触了HBase RegionServer、HiveServerMetastore以及HDFS NameNode这些大内存JVM服务。 在和这些JVM系统打交道的过程中,GC优化始终是一个绕不过去的话题,有的是因为GC导致NameNode RPC请求耗时增大,有的是因为GC导致RegionServer/HiveServer/Metastore […]
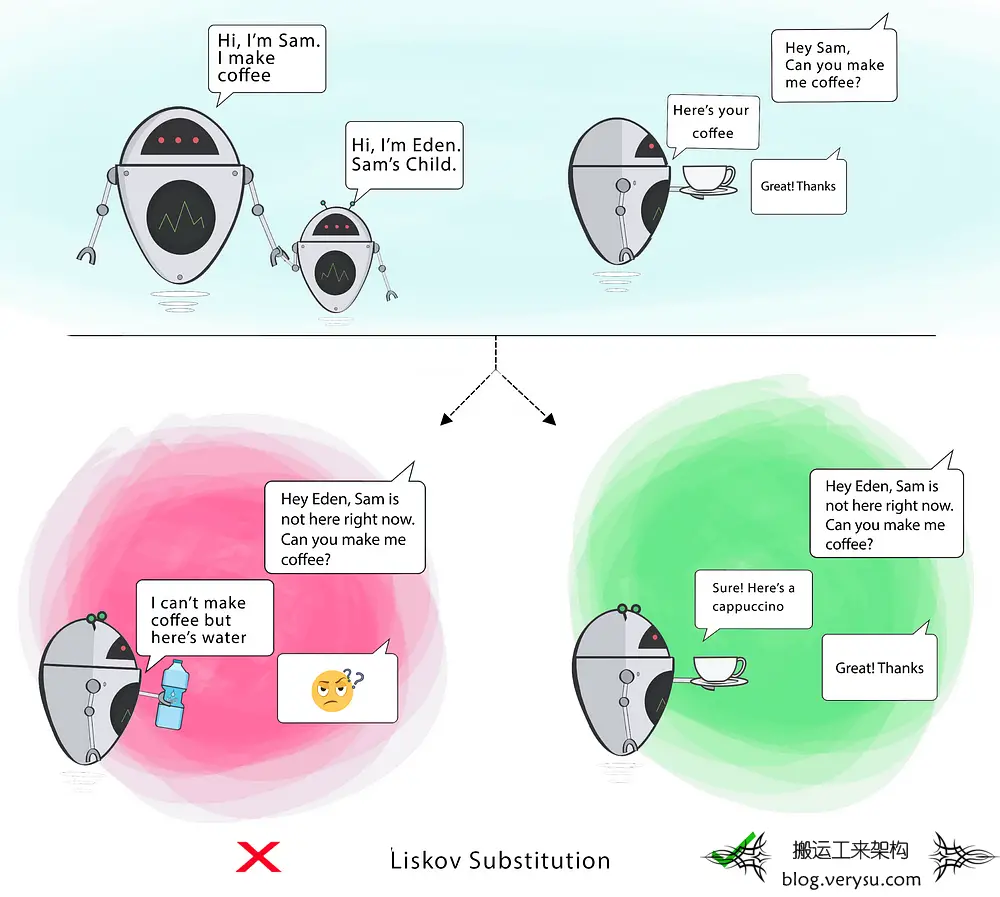
*All illustrations in this article are by Ugonna Thelma If you are familiar with Object-Oriented Programming, then you’ve probably heard about the SOLID principles. These five software de […]

Tech 导读 分层单体架构风格是分层思想在单体架构中的应用,其关注于技术视角的职责分层。同时,基于不同层变化速率的不同,在一定程度上控制变化在系统内的传播,有助于提升系统的稳定性。但这种技术视角而非业务视角的关注点隔离,导致了问题域与工程实现之间的Gap,这种割裂会导致系统认知复杂度的提升。 01 经典单体分层架构 在今年的敏捷团队建设中,我通过Suite执行器实现了一 […]

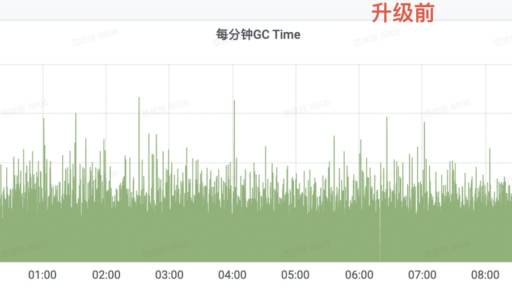
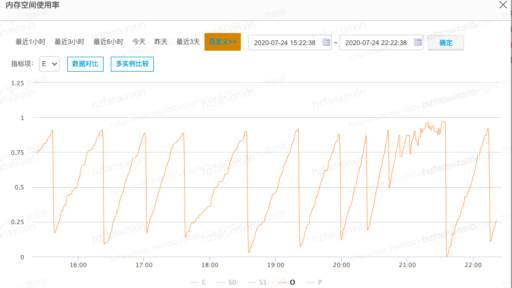
作者:vivo互联网技术团队 Li Guanyun、 Jessica Chen 一、背景 2021年2月,收到反馈,视频APP某核心接口高峰期响应慢,影响用户体验。 通过监控发现,接口响应慢主要是P99耗时高引起的,怀疑与该服务的GC有关,该服务典型的一个实例GC表现如下图: 可以看出,在观察周期里: 平均每10分钟Young GC次数66次,峰值为470次; […]


