
零,前言 经常排查线上紧急问题的IT老兵都知道,IT故障排查,和临床治病救人,有两个共同特征。 第一个特征,都容易“只见树木不见森林”。 综合性医院分科很细,医生专科化程度很高,常常“只见树木不见森林”。医生只知道处理专科的问题,其他方面的问题就通过转科或者会诊的方式交给其他科室。一旦遇到的是系统性、全身性疾病,这种工作模式就会导致延误诊断及治疗。 相对应的,IT团队也 […]

1 结论 2 问题背景及现象 3 排查过程 3.1 初次分析 3.2 问题再次出现 3.3 解决方案 4 总结与反思 1 结论 结论先行:事务+MQ的使用场景,使用方式一定得正确,稍有不慎,可能就会带来数据不一致问题。 2 问题背景及现象 商业退款业务,每周都会有几笔退款订单自动处理失败,究其直接原因,是因为数据表里的一个字段cost更新失败导致。抽象一下,业务场景大概是这 […]

本文记录了JSF异步调用超时引起的接口可用率降低问题,介绍了排查思路和JSF异步调用的流程,本文分析的JSF源码是基于JSF 1.7.5-HOTFIX-T6版本 一、前言 本文记录了由于JSF异步调用超时引起的接口可用率降低问题的排查过程,主要介绍了排查思路和JSF异步调用的流程,希望可以帮助大家了解JSF的异步调用原理以及提供一些问题排查思路。本文分析的JSF源码是基于J […]

本期作者 邹靓 哔哩哔哩创平高级测试开发 前言 2022与2023年交棒的这一天里,作为互联网打工人的大家是在边看跨年晚会边享受美食?还是陪伴在父母身边唠家常?亦或者发生了不可避免的特殊线上case正在抢修中?曾经笔者属于悲催的后者,如果刚好你也被一些跨年/跨月等特殊时间case困扰,欢迎阅读本文一起交流讨论~ 常见时间case与防护分析 话不多说,上干货!笔者经过长年累月 […]

11 月 27 日晚滴滴发生了大范围、长时间的故障。官方消息说是“底层系统软件发生故障”,而据网上的小道消息,一个规模非常大的 K8s 集群进行在线热升级,因为某些原因,所有 Pod(容器)被 kill,而 K8s 的元数据已经被新版本 K8s 修改,无法回滚,因此恢复时间拉的很长。 从滴滴近期分享的技术文章来看,这个说法并不是空穴来风。滴滴团队近两个月正在把公司内部的 K […]

一、问题是怎么发现的 系统是一个定时任务系统,需要定时执行业务代码,业务代码主要是访问MYSQL数据库和缓存进行操作,该开始启动,系统日志一切正常,但是运行一段时间到凌晨后,系统就自动崩溃了,java进程没有了,只留下了程序崩溃日志如下: cat: /proc/1/environ: Permission denied [admin@host-11-40-38-52 ~]$ […]

一次端口告警,发现 java 进程被异常杀掉,而根因竟然是因为在问题机器上 vim 查看了 nginx 日志。下面我将从时间维度详细回顾这次排查,希望读者在遇到相似问题时有些许启发。 时间线 15:19 收到端口异常 odin 告警。 状态:P1故障 名称:应用端口8989 指标:data-stream-openapi.port.8989 主机:data-stream-op […]
一、踩坑描述 写分页查询接口,order by和limit混用的时候,出现了排序的混乱情况 在进行第N页查询时,出现与第一前面页码的数据一样的记录。 二、问题 在MySQL中分页查询,我们经常会用limit,如:limit(0,20)表示查询第一页的20条数据,limit(20,20)表示查询第二页的数据。业务上我们通常也会在分页的时候加上排序 order by; 但是当l […]

一 问题是怎么发现的 最近有个Java系统上线后不久就收到了磁盘使用率告警,磁盘使用率已经超过了90%以上,并且磁盘使用率还在不停增长。 二 问题带来的影响 由于服务器磁盘被打满,导致了系统正常的业务日志无法继续打印,严重影响了系统的可靠性。 三 排查问题的详细过程 刚开始收到磁盘告警的时候,怀疑是日志级别问题,业务日志输出过多导致磁盘打满。但是查看我们自己的业务日志文件目 […]
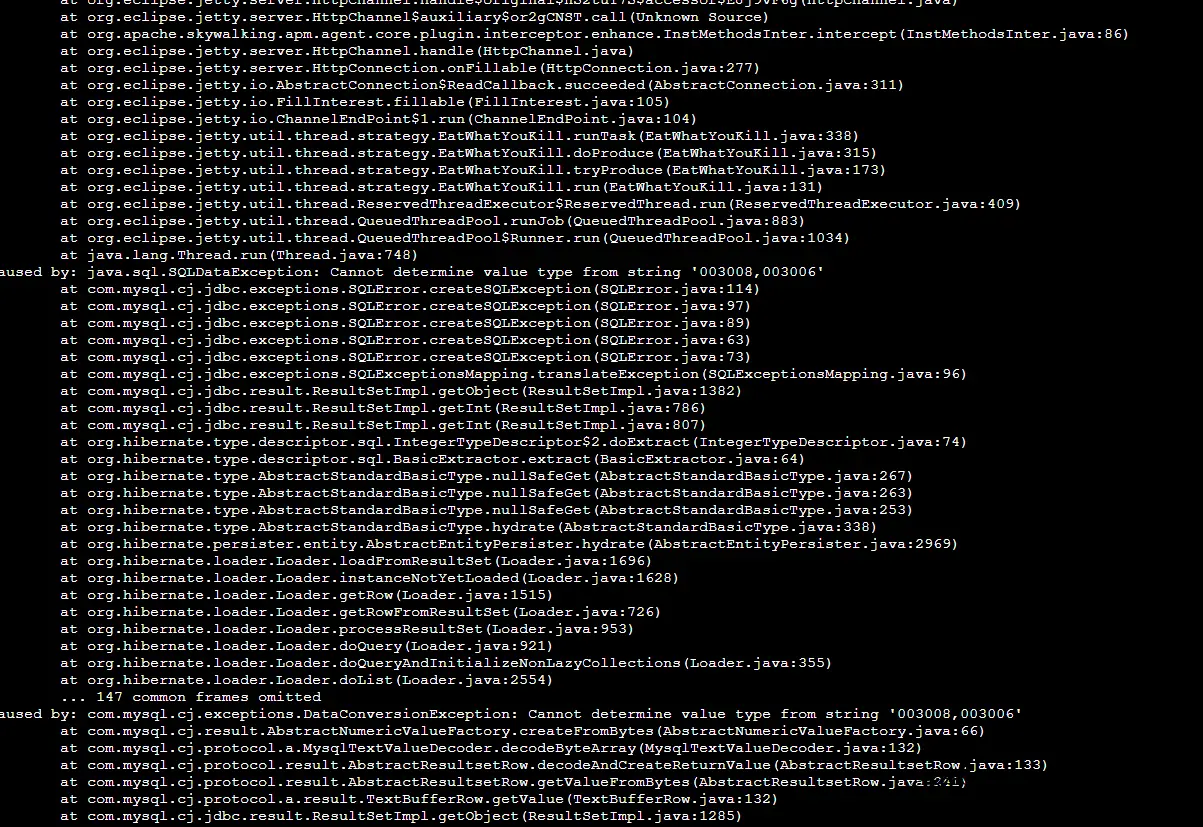
这是遇到的第三次升级MySQL8 Java驱动的“坑”之三。分享一些经历,希望可以帮你少掉进坑里。 之三如下: ①最近有伙伴悄悄升级了Java MySQL8驱动,上线之后业务报障:说某某功能怎么提交不了,而且还提示报错。接到消息,立马查看。排查是某个查询接口报错,于是进一步排查,发现这生产日志打印如下: 可以从上面的异常日志发现,应该是某个字段类型不匹配造成的 […]

作者抽丝剥茧的记录了一次访问Redis延时高问题的排查和总结。 背景 20230308 在某地域进行了线上压测, 发现接口RT频繁超时, 性能下降严重, P50 400ms+, P90 1200ms+, P99 2000ms+。 细致排查发现其中重要的原因是,访问缓存rt竟然飙到了1.2s左右。 作为高性能爱好者, 榨干CPU的每一分价值是我们的宗旨, 是可忍孰不可忍, 怎 […]

10月9日凌晨1点26分,事故发生后不少客户at我,有批评、有建议、有鼓励,由于9号早晨还要去出差,会有几个小时在飞机上,就没来得及一一回复。不论如何都要谢谢你们,因为你们,我才觉得富途所作的事情格外有意义,我们可以去努力和改善的地方还有非常多。 首先我要向大家郑重及诚恳地道歉:真的很对不起,让你们失望了,我们虚心接受所有的批评和建议,并会立即着手相应的改进。 虽然几次影响 […]
最近遇到一个服务器的问题:磁盘满了,占用率 100%~ 这个问题太常见了,于是先来排查一波是哪些文件占用了大量磁盘。 一、排查磁盘占用率100% 1.1 查看磁盘使用的大致情况 第一个命令就是 df -h,来查看磁盘的占用情况。df 是 disk free 的缩写,用于显示目前在 Linux 系统上的文件系统磁盘的使用情况统计。 如下图所示,可以看到磁盘占用率 100%。 […]
上个周日12月18号,阿里云香港服务器发生了都不知道算 P 几事故的史诗级宕机事件,整个事件导致香港地区 C 区 ECS、OSS、EBS、RDS 等云服务大范围不可用,故障时间从 早上 8 点多一直持续到晚上 10 点多才最终恢复,整个故障时间长达 14 个小时。 比较有名的交易所平台如 Gate.io 和 OKEX 都受到大面积故障影响,我都还以为他们跑路了 […]
你好,我是悟空。 本文主要内容如下: 一、前言 最近项目的生产环境遇到一个奇怪的问题: 现象:每天早上客服人员在后台创建客服事件时,都会创建失败。当我们重启这个微服务后,后台就可以正常创建了客服事件了。到第二天早上又会创建失败,又得重启这个微服务才行。 初步排查:创建一个客服事件时,会用到 Redis 的递增操作来生成一个唯一的分布式 ID 作为事件 id。代码如下所示: […]


