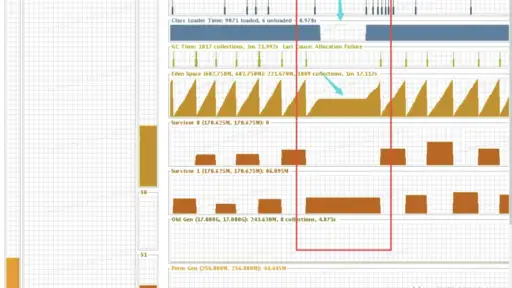
在第一个专题中已经比较系统地介绍了JVM三种常见的垃圾回收器算法和相关实践,这篇文章会在此基础上分场景将GC相关问题再梳理一番,一方面希望能够在发生GC问题的时候可以比较系统地指导问题分析的方向,另一方面也是希望通过这篇文章介绍一些关于使用GC日志分析GC问题的思路。如果在阅读的时候需要更加深入了解背后的机制,可以回头阅读公众号前期相关GC理论文章。 场景一: 没有发生GC […]
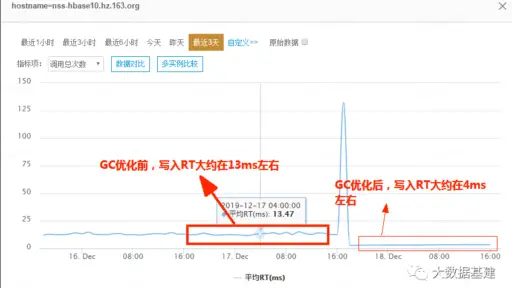
考虑CMS无法有效避免FGC,且单次GC耗时经常不可控。因此在如下两种场景下倾向于使用G1替换CMS: 大堆系统长时间FGC会引起上层服务异常,比如RegionServer/HiveServer等。 对读写毛刺比较敏感的在线数据库服务,比如在线推荐场景下的HBase,GC耗时过长就会导致整体可用率降低。 笔者在2019年开始将集团内部多数HBase所用CMS升级到G1,升级 […]
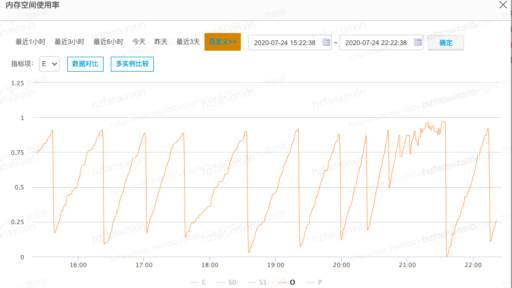
Metastore服务是Hive的核心组成部分,是整个hadoop大数据体系的元数据基石,所有数据表相关schema信息、partition信息、元数据统计信息等都存储在Metastore所依赖的MySQL中,通过Metastore服务执行各种元数据操作。Metastore服务一旦长时间异常,所有依赖服务(诸如HiveServer、Spark、Impala等)就都会出现功能 […]
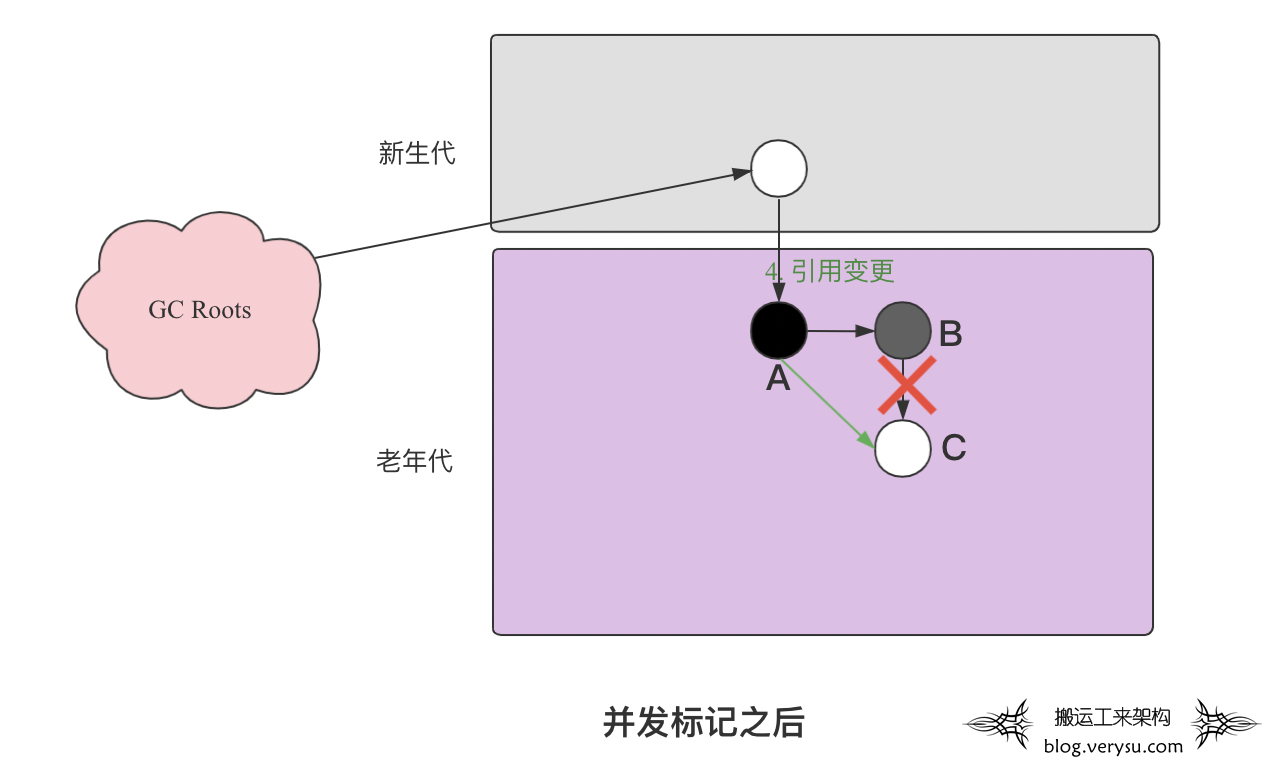
因为工作的需要,笔者前前后后分别接触了HBase RegionServer、HiveServerMetastore以及HDFS NameNode这些大内存JVM服务。 在和这些JVM系统打交道的过程中,GC优化始终是一个绕不过去的话题,有的是因为GC导致NameNode RPC请求耗时增大,有的是因为GC导致RegionServer/HiveServer/Metastore […]


