一、SPI 是什么
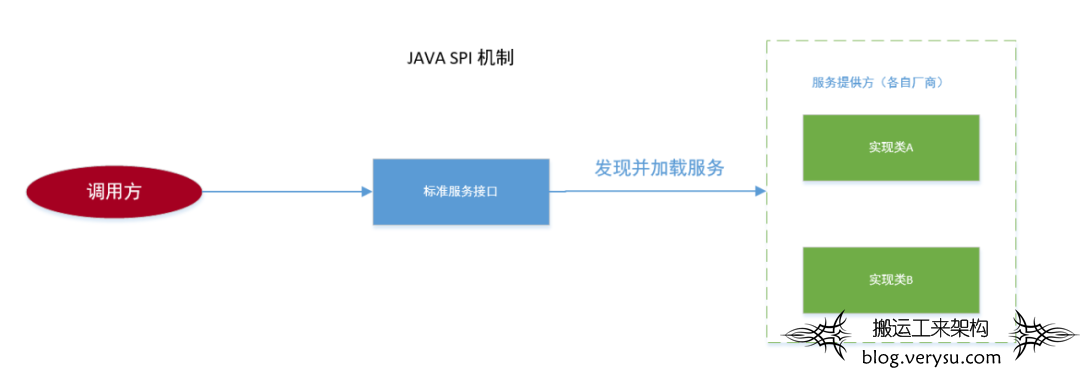
二、适用场景
-
数据库驱动加载接口实现类的加载;如:JDBC 加载Mysql,Oracle... -
日志门面接口实现类加载,如:SLF4J 对log4j、logback 的支持 -
Spring中大量使用了SPI,特别是spring-boot 中自动化配置的实现 -
Dubbo 也是大量使用SPI 的方式实现框架的扩展,它是对原生的SPI 做了封装,允许用户扩展实现Filter 接口。
三、使用介绍
-
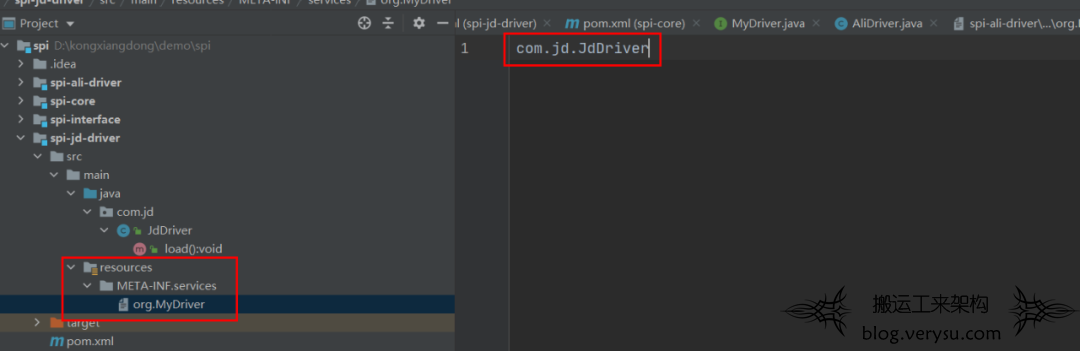
当服务提供者提供了接口的一种具体实现后,需要在JAR 包的META-INF/services 目录下创建一个以“接口全限制定名”为命名的文件,内容为实现类的全限定名; -
接口实现类所在的JAR放在主程序的classpath 下,也就是引入依赖。 -
主程序通过java.util.ServiceLoder 动态加载实现模块,它会通过扫描META-INF/services 目录下的文件找到实现类的全限定名,把类加载值JVM,并实例化它; -
SPI 的实现类必须携带一个不带参数的构造方法。
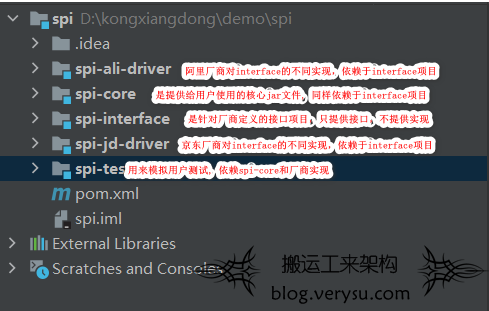
spi-interface 模块定义
- 定义一组接口:public interface MyDriver
实现为:public class JdDriver implements MyDriverpublic class AliDriver implements MyDriver
public void invoker(){
ServiceLoader<MyDriver> serviceLoader = ServiceLoader.load(MyDriver.class);
Iterator<MyDriver> drivers = serviceLoader.iterator();
boolean isNotFound = true;
while (drivers.hasNext()){
isNotFound = false;
drivers.next().load();
}
if(isNotFound){
throw new RuntimeException("一个驱动实现类都不存在");
}
}
public class App
{
public static void main( String[] args )
{
DriverFactory factory = new DriverFactory();
factory.invoker();
}
}


四、原理解析
ServiceLoader<MyDriver> serviceLoader = ServiceLoader.load(MyDriver.class); Iterator<MyDriver> drivers = serviceLoader.iterator();
public final class ServiceLoader<S> implements Iterable<S>{
//配置文件的路径
private static final String PREFIX = "META-INF/services/";
// 代表被加载的类或者接口
private final Class<S> service;
// 用于定位,加载和实例化providers的类加载器
private final ClassLoader loader;
// 创建ServiceLoader时采用的访问控制上下文
private final AccessControlContext acc;
// 缓存providers,按实例化的顺序排列
private LinkedHashMap<String,S> providers = new LinkedHashMap<>();
// 懒查找迭代器,真正加载服务的类
private LazyIterator lookupIterator;
//服务提供者查找的迭代器
private class LazyIterator
implements Iterator<S>
{
.....
private boolean hasNextService() {
if (nextName != null) {
return true;
}
if (configs == null) {
try {
//全限定名:com.xxxx.xxx
String fullName = PREFIX + service.getName();
if (loader == null)
configs = ClassLoader.getSystemResources(fullName);
else
configs = loader.getResources(fullName);
}
}
while ((pending == null) || !pending.hasNext()) {
if (!configs.hasMoreElements()) {
return false;
}
pending = parse(service, configs.nextElement());
}
nextName = pending.next();
return true;
}
private S nextService() {
if (!hasNextService())
throw new NoSuchElementException();
String cn = nextName;
nextName = null;
Class<?> c = null;
try {
//通过反射获取
c = Class.forName(cn, false, loader);
}
if (!service.isAssignableFrom(c)) {
fail(service, "Provider " + cn + " not a subtype");
}
try {
S p = service.cast(c.newInstance());
providers.put(cn, p);
return p;
}
}
........
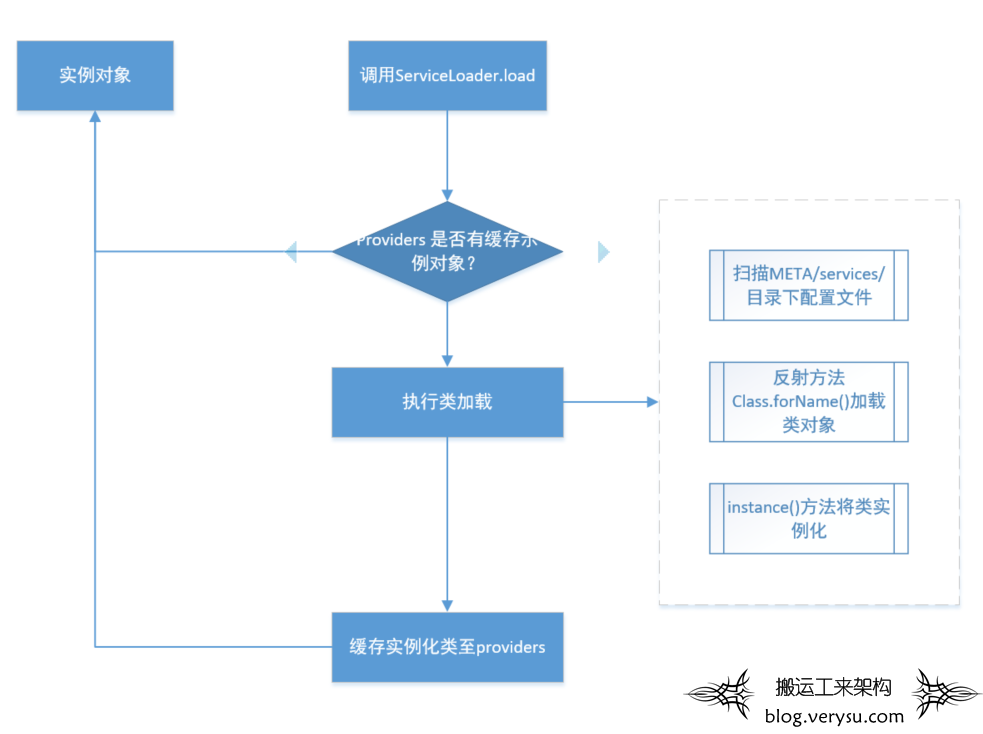
-
应用程序调用ServiceLoader.load 方法 -
应用程序通过迭代器获取对象实例,会先判断providers对象中是否已经有缓存的示例对象,如果存在直接返回 -
如果没有存在,执行类转载 - 将实例化类缓存至providers对象中,同步返回。
- 并用Instance() 方法示例化类
- 通过反射方法Class.forName()加载对象
- 读取META-INF/services 下的配置文件,获取所有能被实例化的类的名称,可以跨越JAR 获取配置文件
五、总结
优点:解耦
-
代码硬编码import 导入 -
指定类全限定名反射获取,例如JDBC4.0 之前;Class.forName("com.mysql.jdbc.Driver")
六、对比
| JDK SPI | DUBBO SPI | Spring SPI | |
| 文件方式 | 每个扩展点单独一个文件 | 每个扩展点单独一个文件 | 所有的扩展点在一个文件 |
| 获取某个固定的实现 | 不支持,只能按顺序获取所有实现 | 有“别名”的概念,可以通过名称获取扩展点的某个固定实现,配合Dubbo SPI的注解很方便 | 不支持,只能按顺序获取所有实现。但由于Spring Boot ClassLoader会优先加载用户代码中的文件,所以可以保证用户自定义的spring.factoires文件在第一个,通过获取第一个factory的方式就可以固定获取自定义的扩展 |
| 其他 | 无 | 支持Dubbo内部的依赖注入,通过目录来区分Dubbo 内置SPI和外部SPI,优先加载内部,保证内部的优先级最高 | 无 |
| 文档完整度 | 文章 & 三方资料足够丰富 | 文档 & 三方资料足够丰富 | 文档不够丰富,但由于功能少,使用非常简单 |
| IDE支持 | 无 | 无 | IDEA 完美支持,有语法提示 |
本文仅供学习!所有权归属原作者。侵删!文章来源: 京东云开发者



文章评论