了解过 Hex 六边形架构、Onion 洋葱架构、Clean 整洁架构的同学可以将本篇文章介绍的实践方法与自身项目代码架构对比并互通有无,共同改进。没了解过上述架构的同学可以学习一种新的架构方法,并尝试将其应用到业务项目中,降低项目维护成本,提高效率。
本文提及的架构主要指项目组织的“代码架构”,注意与微服务架构等名词中的服务架构进行区分。
1.为什么要有代码架构
历史悠久的项目大都会有很多开发人员参与“贡献”,在没有好的指导规则约束的情况下,大抵会变成一团乱麻。 剪不断,理还乱,也没有勇士开发者愿意去剪去理。被迫接手的勇士开发者如果想要增加一个小需求,可能需要花10倍的时间去理顺业务逻辑,再花10倍的时间去补充测试代码,实在是低效又痛苦。
这是一个普遍的痛点问题,也有无数开发者尝试过去解决它。这么多年发展累积下来,业界自然也诞生了很多软件架构。大家耳熟能详的就有六边形架构(Hexagonal Architecture),洋葱架构(Onion Architecture),整洁架构(Clean Architecture)等。这些架构在细节上肯定有所差异,但是核心目标都是一致的:致力于实现软件系统的关注点分离(separation of concerns)。
关注点分离之后的软件系统都具备如下特征:
* 不依赖特定UI。UI可以任意替换,不会影响系统重其他组件。从 Web UI 变成桌面 UI,甚至变成控制台 UI 都无所谓,业务逻辑不会被影响。
* 不依赖特定框架。以JavaScript生态举例,不管是使用web框架 koa, express,还是使用桌面应用框架 electron,还是控制台框架 commander,业务逻辑都不会被影响,被影响的只会是框架接入的那一层。
* 不依赖特定外部组件。系统可以任意使用 MySQL, MongoDB, 或 Neo4j 作为数据库,任意使用 Redis, Memcached, 或 etcd 作为键值存储等。业务逻辑不会因为这些外部组件的替换而变化。
* 容易测试。核心业务逻辑可以在不需要 UI,不需要数据库,不需要 Web 服务器等一切外界组件的情况下被测试。这种纯粹的代码逻辑意味着清晰容易的测试。
软件系统有了这些特征后,易于测试,更易于维护、更新,大大减轻了软件开发人员的心智负担。所以,好的代码架构确实值得推崇。
2.好的代码架构是如何构建的
前文所述的三个架构在理念上是近似的,从下文图1到图3三幅架构图中也能看出相似的圈层结构。图中可以看到,越往外层越具体,越往内层越抽象。这也意味着,越往外越有可能发生变化,包括但不限于框架升级,中间件变更,适配新终端等等。

图1整洁架构的同心圆结构中可以看见三条由外向内的黑色箭头,它表示依赖规则(The Dependency Rule)。依赖规则规定外层的代码可以依赖内层,但是内层的代码不可以依赖外层。也就是说内层逻辑不可以依赖任何外层定义的变量,函数,结构体,类,模块等等代码实体。假如说,最外层蓝色层“Frameworks & Drivers” DB 处使用了 go 语言的 gorm 三方库,并定义了 gorm 相关的数据库结构体及其 tag 等。那么内层的 Gateways,Use Cases, Entities 等处不可以引用任何外层中 gorm 相关的结构体或方法,甚至不应该感知到 gorm 的存在。
核心层的 Entities 定义表示核心业务规则的核心业务实体。这些实体既可以是带方法的类,也可以是带有一堆函数的结构体。但它们必须是高度抽象的,只可以随着核心业务规则变化,不可以随着外层组件的变化而变化。以简单博客系统举例的话,此层可以定义 Blog,Comment等核心业务实体。

核心层的外层是应用业务层。
应用业务层的 Use Cases 应该包含软件系统所有的业务逻辑。该层控制所有流向和流出核心层的数据流,并使用核心层的实体及其业务规则来完成业务需求。此层的变更不会影响核心层,更外层的变更,比如开发框架、数据库、UI等变化,也不会影响此层。接着博客系统的例子,此层可以定义 BlogManager 接口,并定义其中的 CreateBlog, LeaveComment 等业务逻辑方法。
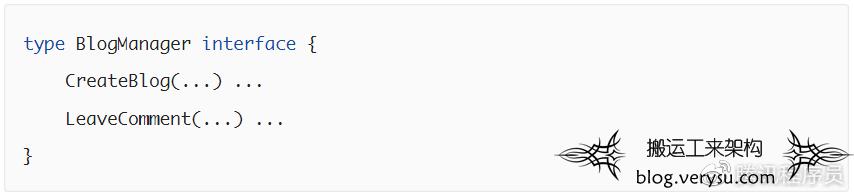
应用业务层的外层是接口适配层。
接口适配层的 Controllers 将外层输入的数据转换成内层 Use Cases 和 Entities 方便使用的格式,然后 Presenters,Gateways 再将内层处理结果转换成外层方便使用的格式,然后再由更外层呈现到 Web, UI 或者写入到数据库。假如系统选择关系型数据库作为其持久化方案的话,那么所有关于 SQL 的处理都应该在此层完成,更内层不需要感知到任何数据库的存在。同理,假如系统与外界服务通信的话,那么所有有关外界服务数据的转化都在此层完成,更内层也不需要感知到外界服务的存在。外层通过此层传递数据一般通过DTO(Data Transfer Object)或者DO(Data Object)完成。接上文博客系统例子,示例代码如下:
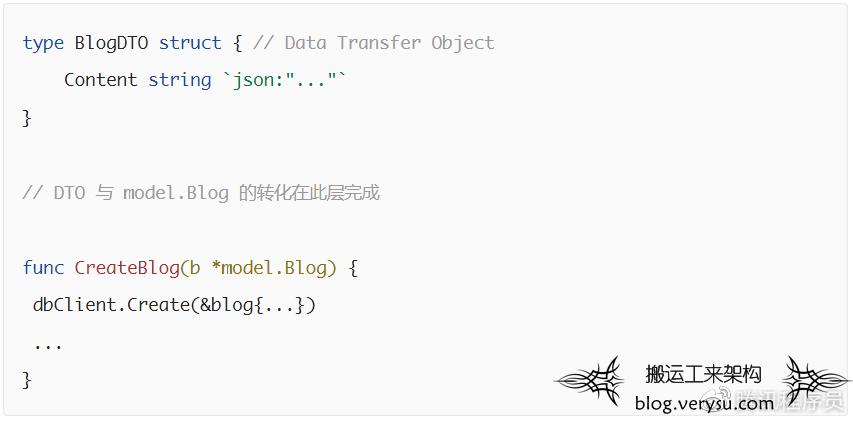
接口适配层的外层是处在最外层的框架和驱动层。
该层包含具体的框架和依赖工具细节,比如系统使用的数据库,Web 框架,消息队列等等。此层主要帮助外部框架、工具和内层进行数据衔接。接博客系统例子,框架和驱动层如果使用 gorm 来操作数据库,则相关的示例代码如下:
import "gorm.io/driver/mysql"
import "gorm.io/gorm"
type blog struct { // Data Object
Content string `gorm:"..."` // 本层的数据库 ORM 如果替换,此处的 tag 也需要随之改变
}
type MySQLClient struct { DB *gorm.DB }
func New(...) { gorm.Open(...) ... }
func Create(...)
...
至此,整洁架构图中的四层已介绍完成。但此图中的四层结构仅作示意,整洁架构并不要求软件系统必须严格按照此四层结构。只要软件系统能保证“由外向内”的依赖规则,系统的层数多少可自由裁决。
同整洁架构齐名的洋葱架构,与其相似,整体结构也是四层同心圆。

图2中洋葱架构最核心的 Domain Model 表示组织中核心业务的状态及其行为模型,与整洁架构中的 Entities 高度一致。其外层的 Domain Services 与整洁架构中的 Use Cases 职责相近。更外层的 Application Services 桥接 UI 和 Infrastructue 中的数据库、文件、外部服务等,更是与整洁架构中的 Interface Adaptors 功能相同。最边缘层的 User Interface 与整洁架构中的最外层 UI 部分一致,Infrastructure 则与整洁架构中的 DB, Devices, External Interfaces 作用一致,只 Tests 部分稍有差异。
同前两者齐名的六边形架构,虽然外形不是同心圆,但是结构上还是有很多呼应的地方。

图3六边形架构中灰色箭头表示依赖注入(Dependency Injection),其与整洁架构中的依赖规则(The Dependency Rule)有异曲同工之妙,也限制了整个架构各组件的依赖方向必须是“由外向内”。图中的各种 Port 和 Adapter 是六边形架构的重中之重,故该架构别称 Ports and Adapters。

如图4所示,在六边形架构中,来自驱动边(Driving Side)的用户或外部系统输入通过左边的 Port & Adapter 到达应用系统,处理后,再通过右边的 Adapter & Port 输出到被驱动边(Driven Side)的数据库和文件等。
Port 是系统的一种与具体实现无关的入口,该入口定义了外界与系统通信的接口(interface)。Port 不关心接口的具体实现,就好比 USB 端口允许多种设备通过其与电脑通信,但它不关心设备与电脑之间的照片,视频等等具体数据是如何编解码传输的。

如图5所示,Adapter 负责 Port 定义的接口的技术实现,并通过 Port 发起与应用系统的交互。比如,图左 Driving Side 的Adapter可以是一个 REST 控制器,客户端通过它与应用系统通信。图右 Driven Side 的Adapter可以是一个数据库驱动,应用系统的数据通过它写入数据库。此图中可以看到,虽然六边形架构看上去与整洁架构不那么相似,但其应用系统核心层的 Domain ,边缘层的User Interface 和 Infrastructure 与整洁架构中的 Entities 和 Frameworks & Drivers 完全是遥相呼应。
再次回到图3的六边形架构整体图,以 Java 生态为例,Driving Side 的 HTTP Server In Port 可以承接来自 Jetty 或 Servlet 等 Adapter 的请求,其中 Jetty 的请求可以是来自其他服务的调用。既处在 Driving Side,又处在 Driven Sides 的 Messaging In/Out Port 可以承接来自 RabbitMQ 的事件请求,也可以将 Application Adapters 中生成的数据写入到 RabbitMQ。Driven Side 的 Store Out Port 可以将 Application Adapters 产生的数据写入到 MongoDB;HTTP Client Out Port 则可以将 Application Adapters 产生的数据通过 JettyHTTP 发送到外部服务。
其实,不仅国外有优秀的代码架构,国内也有。
国内开发者在学习了六边形架构,洋葱架构和整洁架构之后,提出了 COLA (Clean Object-oriented and Layered Architecture)架构,其名称含义为“整洁的基于面向对象和分层的架构”。它的核心理念与国外三种架构相同,都是提倡以业务为核心,解耦外部依赖,分离业务复杂度和技术复杂度[4]。整体架构形式如图6所示。

虽然 COLA 架构不再是同心圆或者六边形的形式,但是还是能明显看到前文三种架构的影子。Domain 层中 model 对应整洁架构的 Entities,六边形架构和洋葱架构中的 Domain Model。Domain 层中 gateway 和 ability 对应整洁架构的 Use Cases,六边形架构中的 Application Logic,以及洋葱架构中的 Domain Services。App 层则对应整洁架构 Interface Adapters 层中的 Controllers,Gateways,和 Presenters。最上方的 Adapter 层和最下方的 Infrastructure 层合起来与整洁架构的边缘层 Frameworks & Drivers 相呼应。
Adapter 层上方的 Driving adater 与 Infrastructure 层下方的 Driven adapter 更是与六边形架构中的 Driving Side 和 Driven Side 高度一致。
COLA 架构在 Java 生态中落地已久,也为开发者们提供了 Java 语言的 archetype,可方便地用于 Java 项目脚手架代码的生成。笔者受其启发,推出了一种符合 COLA 架构规则的 Go 语言项目脚手架实践方案。
3.推荐一种 Go 代码架构实践
项目目录结构如下:
├── adapter // Adapter层,适配各种框架及协议的接入,比如:Gin,tRPC,Echo,Fiber 等
├── application // App层,处理Adapter层适配过后与框架、协议等无关的业务逻辑
│ ├── consumer //(可选)处理外部消息,比如来自消息队列的事件消费
│ ├── dto // App层的数据传输对象,外层到达App层的数据,从App层出发到外层的数据都通过DTO传播
│ ├── executor // 处理请求,包括command和query
│ └── scheduler //(可选)处理定时任务,比如Cron格式的定时Job
├── domain // Domain层,最核心最纯粹的业务实体及其规则的抽象定义
│ ├── gateway // 领域网关,model的核心逻辑以Interface形式在此定义,交由Infra层去实现
│ └── model // 领域模型实体
├── infrastructure // Infra层,各种外部依赖,组件的衔接,以及domain/gateway的具体实现
│ ├── cache //(可选)内层所需缓存的实现,可以是Redis,Memcached等
│ ├── client //(可选)各种中间件client的初始化
│ ├── config // 配置实现
│ ├── database //(可选)内层所需持久化的实现,可以是MySQL,MongoDB,Neo4j等
│ ├── distlock //(可选)内层所需分布式锁的实现,可以基于Redis,ZooKeeper,etcd等
│ ├── log // 日志实现,在此接入第三方日志库,避免对内层的污染
│ ├── mq //(可选)内层所需消息队列的实现,可以是Kafka,RabbitMQ,Pulsar等
│ ├── node //(可选)服务节点一致性协调控制实现,可以基于ZooKeeper,etcd等
│ └── rpc //(可选)广义上第三方服务的访问实现,可以通过HTTP,gRPC,tRPC等
└── pkg // 各层可共享的公共组件代码
由此目录结构可以看出通过 Adapter 层屏蔽外界框架、协议的差异,Infrastructure 层囊括各种中间件和外部依赖的具体实现,App层负责组织输入输出, Domain 层可以完全聚焦在最纯粹也最不容易变化的核心业务规则上。
按照前文 infrastructure 中目录结构,各子目录中文件样例参考如下:
├── infrastructure
│ ├── cache
│ │ └── redis.go // Redis 实现的缓存
│ ├── client
│ │ ├── kafka.go // 构建 Kafka client
│ │ ├── mysql.go // 构建 MySQL client
│ │ ├── redis.go // 构建 Redis client(cache和distlock中都会用到 Redis,统一在此构建)
│ │ └── zookeeper.go // 构建 ZooKeeper client
│ ├── config
│ │ └── config.go // 配置定义及其解析
│ ├── database
│ │ ├── dataobject.go // 数据库操作依赖的数据对象
│ │ └── mysql.go // MySQL 实现的数据持久化
│ ├── distlock
│ │ ├── distributed_lock.go // 分布式锁接口,在此是因为domain/gateway中没有直接需要此接口
│ │ └── redis.go // Redis 实现的分布式锁
│ ├── log
│ │ └── log.go // 日志封装
│ ├── mq
│ │ ├── dataobject.go // 消息队列操作依赖的数据对象
│ │ └── kafka.go // Kafka 实现的消息队列
│ ├── node
│ │ └── zookeeper_client.go // ZooKeeper 实现的一致性协调节点客户端
│ └── rpc
│ ├── dataapi.go // 第三方服务访问功能封装
│ └── dataobject.go // 第三方服务访问操作依赖的数据对象
再接前文提到的博客系统例子,假设用 Gin 框架搭建博客系统API服务的话,架构各层相关目录内容大致如下:
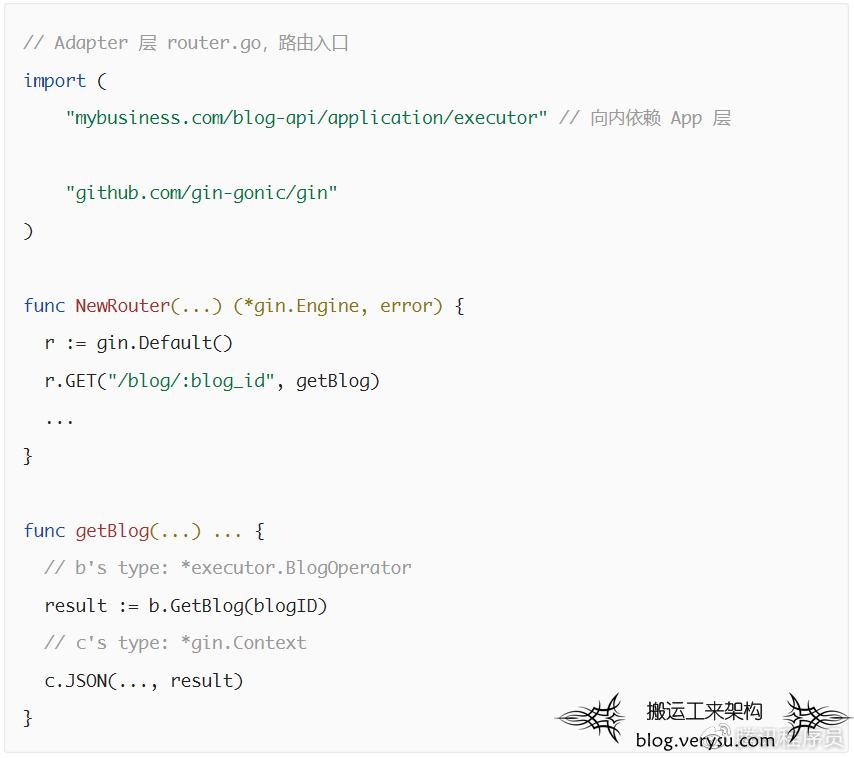
如代码所体现,Gin 框架的内容全部会被限制在 Adapter 层,其他层不会感知到该框架的存在。
// App 层 executor/blog_operator.go
import "mybusiness.com/blog-api/domain/gateway" // 向内依赖 Domain 层
type BlogOperator struct {
blogManager gateway.BlogManager // 字段 type 是接口类型,通过 Infra 层具体实现进行依赖注入
}
func (b *BlogOperator) GetBlog(...) ... {
blog, err := b.blogManager.Load(ctx, blogID)
...
return dto.BlogFromModel(...) // 通过 DTO 传递数据到外层
}
App 层会依赖 Domain 层定义的领域网关,而领域网关接口会由 Infra 层的具体实现注入。外层调用 App 层方法,通过 DTO 传递数据,App 层组织好输入交给 Domain 层处理,再将得到的结果通过 DTO 传递到外层。
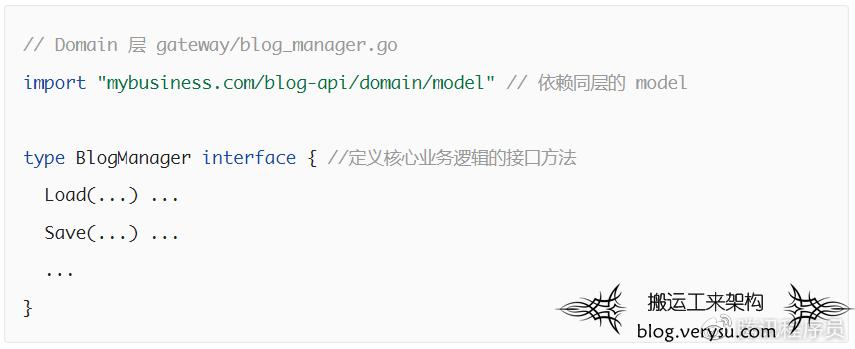
Domain 层是核心层,不会依赖任何外层组件,只能层内依赖。这也保障了 Domain 层的纯粹,保障了整个软件系统的可维护性。
// Infrastructure 层 database/mysql.go
import (
"mybusiness.com/blog-api/domain/model" // 依赖内层的 model
"mybusiness.com/blog-api/infrastructure/client" // 依赖同层的 client
)
type MySQLPersistence struct {
client client.SQLClient // client 中已构建好了所需客户端,此处不用引入 MySQL, gorm 相关依赖
}
func (p ...) Load(...) ... { // Domain 层 gateway 中接口方法的实现
record := p.client.FindOne(...)
return record.ToModel() // 将 DO(数据对象)转成 Domain 层 model
}
Infrastructure 层中接口方法的实现都需要将结果的数据对象转化成 Domain 层 model 返回,因为领域网关 gateway 中定义的接口方法的入参、出参只能包含同层的 model,不可以有外层的数据类型。
前文提及的完整调用流程如图7所示。

如图,外部请求首先抵达 Adapter 层。如果是读请求,则携带简单参数调用 App 层;如果是写请求,则携带 DTO 调用 App 层。App 层将收到的DTO转化成对应的 Model,调用 Domain 层 gateway 相关业务逻辑接口方法。由于系统初始化阶段已经完成依赖注入,接口对应的来自 Infra 层的具体实现会处理完成并返回 Model 到 Domain 层,再由 Domain 层返回到 App 层,最终经由 Adapter 层将响应内容呈现给外部。
至此可知,参照 COLA 设计的系统分层架构可以一层一层地将业务请求剥离干净,分别处理后再一层一层地组装好返回到请求方。各层之间互不干扰,职责分明,有效地降低了系统组件之间的耦合,提升了系统的可维护性。
4.总结
无论哪种架构都不会是项目开发的银弹,也不会有百试百灵的开发方法论。毕竟引入一种架构是有一定复杂度和较高维护成本的,所以开发者需要根据自身项目类型判断是否需要引入架构。
不建议引入架构的项目类型:
* 软件生命周期大概率会小于三个月的
* 项目维护人员在现在以及可见的将来只有自己的
可以考虑引入架构的项目类型:
* 软件生命周期大概率会大于三个月的
* 项目维护人员多于1人的
强烈建议引入架构的项目类型:
* 软件生命周期大概率会大于三年的
* 项目维护人员多于5人的
5. 参考文献
[1] Robert C. Martin, The Clean Architecture, https://blog.cleancoder.com/uncle-bob/2012/08/13/the-clean-architecture.html (2012)
[2] Andrew Gordon, Clean Architecture, https://www.andrewgordon.me/posts/Clean-Architecture/ (2021)
[3] Pablo Martinez, Hexagonal Architecture, there are always two sides to every story, https://medium.com/ssense-tech/hexagonal-architecture-there-are-always-two-sides-to-every-story-bc0780ed7d9c (2021)
[4] 张建飞, COLA 4.0:应用架构的最佳实践, https://blog.csdn.net/significantfrank/article/details/110934799 (2022)
[5] Jeffrey Palermo, The Onion Architecture, https://jeffreypalermo.com/2008/07/the-onion-architecture-part-1/ (2008)
文章来源:腾讯程序员



文章评论