随着互联网技术的飞速发展,分布式已经成为一个绕不开的话题,分布式环境下,“高并发访问共享资源”的场景并不少见,带来的问题也显⽽易见:共享资源在访问前后出现了数据不一致或非预期结果!!!
单体时代可以⽤JVM提供的ReentrantLock或者Synchronized解决,分布式环境下,JVM就有点力不不从心了。于是乎,“分布式锁”便出现了。
01 什么是分布式锁?
在计算机科学中,锁(lock)与互斥(mutex)是一种同步机制,用于在许多线程执行时对资源的限制。
分布式锁可以理解为,控制分布式系统有序的去对共享资源进行操作,通过互斥来保持一致性。
1、分布式锁应具备哪些特性?
分布式锁是多服务共享锁,在分布式的部署环境下,通过锁机制来让客户端互斥的对共享资源进行访问,应该具备以下特性。
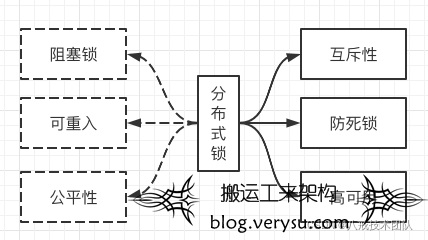
**互斥性:**同一时间,保证共享资源只能被一个客户端的一个线程能访问,具有排他性。
**防死锁:**锁在一段时间后,一定会被释放(正常释放或异常释放)。
**高可用:**获取锁的机制必须高可用,性能佳。
**阻塞锁(可选):**当前资源已被加锁,其他客户端或者线程是阻塞等待,还是立即返回。
**可重入(可选):**当前锁的持有者是否能再次进入。
**公平性(可选):**加锁的顺序和请求加锁的顺序是一致,还是随机抢锁。
2、分布式锁可以解决哪些场景的问题?
分布式锁就是用来解决高并发访问导致数据不一致的问题,这里列举几种常见的场景。
**多用户修改数据,造成数据不准确:**多个请求对同一条数据同时进行修改,导致数据不准确。比如“下单减库存”、“互联网秒杀”、“抢红包”、“抢票”、“抢优惠券”、“互联网选号”、“转账”等。
**多次请求,数据重复:**请求结果暂未返回时,进行多次操作或重试,产生多个相同的请求,不加锁的情况下成功,会产生很多重复记录。
**分布式协调:**分布式环境下,多台机器都可以执行任务,每次只能一台机器执行,也可以用分布式锁来做标记,只有获取到锁的机器可以执行。
3、分布式锁有哪些实现方式?
关于锁,Java提供了种类丰富的锁,每种锁因其特性的不同,在适当的场景下能够展现出非常高的效率。
“分布式锁”其实是一种解决方案,并非专有组件或者类,实现这一解决方案仍旧需要额外的组件或者中间件来辅助,甚至某些情况下,需要借助数据库级别的方式来实现。
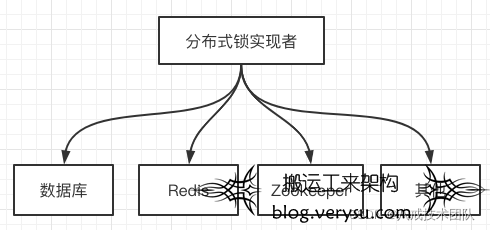
关于分布式锁的实现方案,在业界流行的有三种:
**基于数据库:**借助数据库锁实现,实现简单,性能是最大问题。(不推荐)
**基于Redis:**CAP模型属于AP,无一致性算法,速度快。(高性能场景推荐)
基于Zookeeper:CAP模型属于CP,可靠性高,性能比Redis差一些。(高可靠场景推荐)
另外,还有使用etcd、consul来实现的。
到这里,我们已经对分布式锁的特点、使用场景、实现方式有了大致的了解。那么,一款高性能分布式锁到底应该如何设计?请继续往下看。
02 高并发场景下分布式锁如何设计?
因为Redis出色的性能,在高并发环境中,使用最多的是Redis方案,实现最复杂,最容易出问题的也是Redis方案。
接下来,用Redis来实现一个库存加分锁的列子,对分布式锁的设计原理和思路进行阐述。
需求场景:假设库存有100件商品,通过互联网秒杀下单,要求抢完的同时不能超卖。
分布式模拟:启用2个服务,来模拟分布式环境,前端用Nginx分发请求。
并发工具:使用JMeter并发模拟多个用户并发请求。
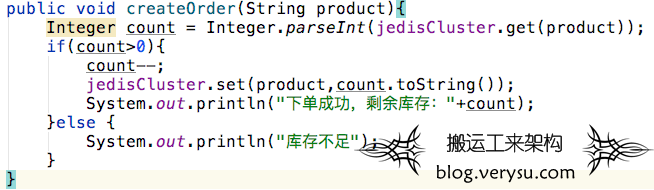
1、无锁减库存
我们先来看一下无锁的情况,下单减库存会存在什么问题?具体代码如下:

并发请求模拟:
测试计划->添加线程组(配置线程属性)
线程组->添加->Sampler ->HTTP请求(配置http请求地址)
HTTP请求->添加监听器(图形结果、查看结果树)
选项-> Log Viewer (打开日志)
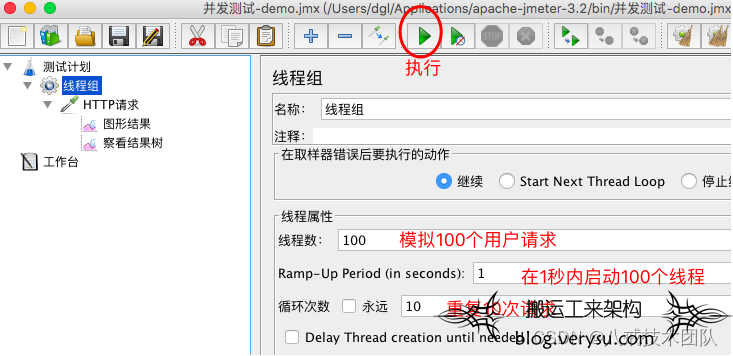
执行结果如下:

问题很明显,当库存为1时,还成功了3个订单,这结果并不是我们所期望的。这是因为,分布式环境下,当只有1个库存时候,同时有3个线程读取到了该库存,完成了下单。这种多用户访问导致数据不准确的问题,就可以用分布式锁来解决。
接下来,我们看看用Redis怎么实现分布式锁。
2、分布式锁实现(初级版)
根据前面介绍的,分布式锁,必须具备下面三个特性:
**互斥性:**只有获取到锁的线程才能访问。
**防死锁:**设置过期自动删除来实现解释失败导致的死锁。
**高可用:**通过Redis Cluster的高可用来保证。
实现思路很简单:访问库存前,往Redis写入一个锁标志,访问结束删除锁,只有拿到锁的才可以访问。
设置过期时间来清理未被成功删除的锁。
设置加锁人的身份标识,防止被他人误删。
Redis提供了丰富的命令操作功能,JAVA可以用RedisTemplate操作,代码如下:
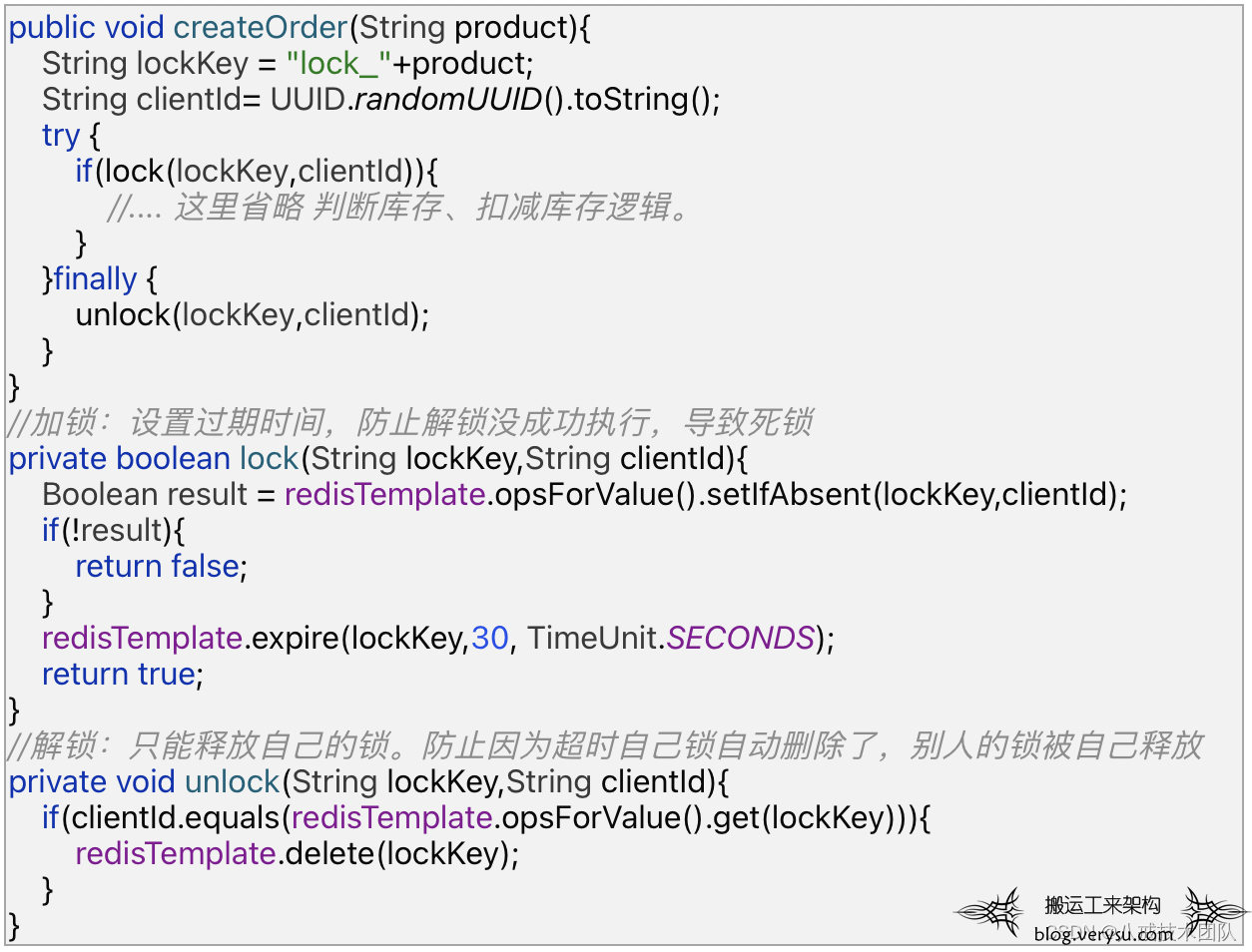
再看⼀下结果:

执行结果正常,到这里,一个简单分布式锁就完成了。 作为一个思路严谨的程序员,你可能还有诸多疑问:如果设置锁成功,设置过期时间失败了怎么办?如果过期时间到了,业务没执行完怎么办?如果没获取到锁,想等待锁空闲再获取,该怎么实现?如果加锁方法调用了其他方法,其他方法又调用加锁方法,需多次进入该锁,怎么办?
生产级使用,还需要实现:原子操作、续期、阻塞获取、支持重入。
具体实现方法,请接着往下看。

3、分布式锁实现(高级版)
基于上面的问题,你也许想到了解决方案,比如:
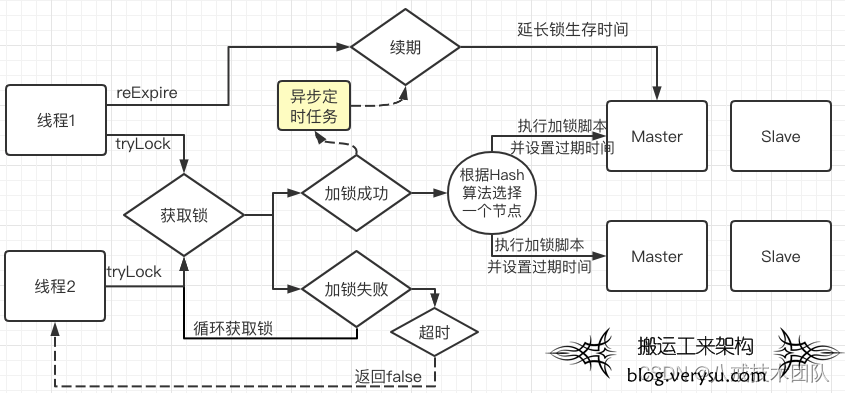
**原子操作:**可以通过Redis提供的Lua脚本功能来实现。
**续期:**可以用异步线程自动续期,或者显示调用续期方法。
**阻塞获取:**获取锁时设置等待时间,内部用循环自旋获取锁,直到超时。
**重入:**可以通过Redis Hash结构存储,同时记录key和value,每次进入value+1。
简单介绍一下Lua脚本:
Redis Lua脚本
从redis 2.6.0推出了脚本功能,允许开发者用Lua语言编写脚本,传到Redis中执行。使用脚本好处:
- 减少网络开销
- 原子操作
- 替代Redis的事物功能
接下来,我们分析一下加锁、重入、解锁的完整流程。
加锁(续期)原理
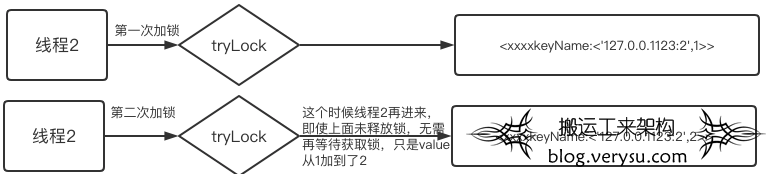
重入原理
数据结构类似Java的Map <key,Map<key1,value>>类型,这里key为锁名称,key1为客户端信息,value为重入次数。
数据结构设计:<工程名称+keyName,hostaddress+uuid:线程ID,重入次数>
每重入一次,value就+1。
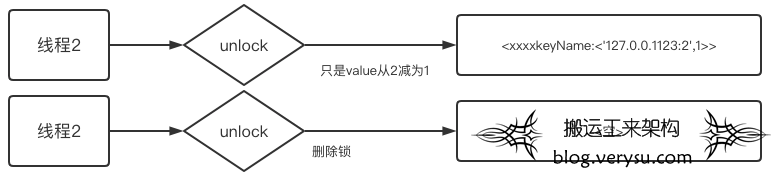
解锁原理
解锁时,先判断线程信息(只能操作当前线程的锁),再将加锁次数减1,当次数为0就删除锁。

加锁和重入的Lua脚本:
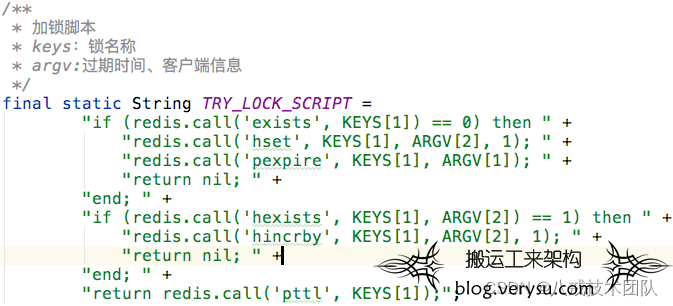
Redis命令解释:
EXISTS key:检查给定 key 是否存在,存在返回 1 ,否则返回0 。
HSET key field value:将哈希表 key 中的域 field 的值设为 value 。
PEXPIRE key milliseconds:以毫秒为单位设置 key 的生存时间。
HEXISTS key field:查看哈希表 key 中,给定域 field 是否存在。
HINCRBY key field increment:为哈希表 key 中的域 field 的值加上增量 increment 。
PTTL key:以毫秒为单位返回 key 的剩余生存时间。
解锁Lua脚本:

脚本执行:
执行Lua脚本,可以通过下面两个方法(一次加载,多次执行)。
String hash = redisCluster.scriptLoad(script, key);
Object result = redisCluster.evalsha(hash, keys, args);
实现了上面这些功能,一个企业级高可用分布式锁基本就完成了。
当然,在实现过程,还需要考虑很多细节问题,比如:脚本加载失败重试、Redis集群路由、脚本执行失败重试等等。
顺便说一句,完整版“lock-sdk”已发布在公司maven仓库,可以直接使用。Redis高性能版内部实现了CashCloud接入,注解方式使用锁,后期也会实现Zookeeper高可靠版本。
写在最后的话
本文介绍了分布式锁特性、应用场景、以及实现方式,并以一个基于Redis设计分布式锁的例子,介绍了分布式锁的设计原理和思路,希望帮助大家对分布式锁有一个更新的认识。
Redis实现分布式锁只是其中一种方案,也不能保证100%的一致性,比如Redis集群Master加锁成功,还没来得及同步到Slave节点,Master就挂了,这种场景也会出现数据不一致的问题。如果对可靠性有更高要求,可以选择Zookeeper实现方案。再比如,互联网秒杀场景仅仅基于一个分布式锁也不能完全扛得住,可能需要引入分段库存锁机制来实现。
任何技术都不是万能的,没有哪一种技术方案能解决所有业务场景的问题,希望大家根据业务场景选择合适的技术方案!
希望以上内容能对有需要的人有所帮助
欢迎大家一起探讨交流


